
نماذج اللغات الكبيرة (LLMs) هي قلب أنظمة Agentic وأنظمة RAG. والبناء باستخدام LLMs أمر مثير حتى يجعل الحجم باهظ الثمن. هناك دائمًا مقايضة بين التكلفة مقابل الجودة، ولكن في هذه المقالة سنستكشف أفضل 10 طرق وفقًا لي يمكنها خفض تكاليف استخدام LLM مع التركيز على الحفاظ على جودة النظام. لاحظ أيضًا أنني سأستخدم OpenAI API للاستدلال ولكن يمكن تطبيق التقنيات على موفري النماذج الآخرين أيضًا. لذلك، دون أي مزيد من اللغط، دعونا نفهم معادلة التكلفة ونرى طرق تحسين تكلفة LLM.
المتطلب السابق: فهم معادلة التكلفة
قبل أن نبدأ، من الأفضل أن نكون على دراية أفضل بالتكاليف والرموز المميزة ونافذة السياق:
- الرموز: هذه هي الوحدات الصغيرة من النص. لجميع الأغراض العملية، يمكنك افتراض أن 1000 رمز يساوي 750 كلمة تقريبًا.
- الرموز الفورية: هذه هي رموز الإدخال التي نرسلها إلى النموذج. فهي أرخص عموما.
- رموز الإكمال: هذه هي الرموز المميزة التي تم إنشاؤها بواسطة النموذج. غالبًا ما تكون أغلى بـ 3-4 مرات من رموز الإدخال.
- نافذة السياق: هذا يشبه الذاكرة قصيرة المدى (يمكن أن تشمل المدخلات والمخرجات القديمة). إذا تجاوزت هذا الحد، فسيتجاهل النموذج الأجزاء السابقة من المحادثة. إذا قمت بإرسال 10 رسائل سابقة في نافذة السياق، فسيتم احتساب تلك الرسائل كرموز إدخال للطلب الحالي وستتم إضافتها إلى التكاليف.
- التكلفة الإجمالية: (رموز الإدخال × تكلفة رمز الإدخال) + (رموز الإخراج × تكلفة رمز الإخراج)
ملحوظة: بالنسبة لـ OpenAI، يمكنك استخدام لوحة تحكم الفوترة لتتبع التكاليف: https://platform.openai.com/settings/organization/billing/overview
لمعرفة كيفية الحصول على OpenAI API، اقرأ هذه المقالة.
1. توجيه الطلبات إلى النموذج الصحيح
لا تتطلب كل مهمة أفضل وأحدث نموذج، يمكنك تجربة نموذج أرخص أو تجربة استخدام بضع لقطات مع نموذج أرخص لتكرار نموذج أكبر.
قم بتكوين مفتاح API
from google.colab import userdata
import os
os.environ('OPENAI_API_KEY')=userdata.get('OPENAI_API_KEY') تحديد الوظائف
from openai import OpenAI
client = OpenAI()
SYSTEM_PROMPT = "You are a concise, helpful assistant. You answer in 25-30 words"
def generate_examples(questions, n=3):
examples = ()
for q in questions(:n):
response = client.chat.completions.create(
model="gpt-5.1",
messages=({"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": q})
)
examples.append({"q": q, "a": response.choices(0).message.content})
return examplesتستخدم هذه الوظيفة GPT-5.1 الأكبر وتجيب على السؤال في 25-30 كلمة.
# Example usage
questions = (
"What is overfitting?",
"What is a confusion matrix?",
"What is gradient descent?"
)
few_shot = generate_examples(questions, n=3)عظيم، لقد حصلنا على أزواج الأسئلة والأجوبة.
def build_prompt(examples, question):
prompt = ""
for ex in examples:
prompt += f"Q: {ex('q')}\nA: {ex('a')}\n\n"
return prompt + f"Q: {question}\nA:"
def ask_small_model(examples, question):
prompt = build_prompt(examples, question)
response = client.chat.completions.create(
model="gpt-5-nano",
messages=({"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": prompt})
)
return response.choices(0).message.contentهنا، لدينا وظيفة تستخدم “gpt-5-nano” أصغر ووظيفة أخرى تقوم بإجراء المطالبة باستخدام أزواج الأسئلة والإجابات للنموذج.
answer = ask_small_model(few_shot, "Explain regularization in ML.")
print(answer)دعنا نمرر سؤالاً إلى النموذج.
الإخراج:
Regularization adds a penalty to the loss for model complexity to reduce overfitting. Common forms include L1 (lasso) promoting sparsity and L2 (ridge) shrinking weights; elastic net blends.
عظيم! لقد استخدمنا نموذجًا أرخص بكثير (gpt-5-nano) للحصول على مخرجاتنا، ولكن بالتأكيد لا يمكننا استخدام النموذج الأرخص لكل مهمة.
2. استخدم النماذج حسب المهمة
الفكرة هنا هي استخدام نموذج أصغر للمهام الروتينية، واستخدام النماذج الأكبر فقط للاستدلال المعقد. فكيف نفعل هذا؟ سنحدد هنا مصنفًا يُرجع “بسيطًا” أو “معقدًا” ونوجه الاستعلامات وفقًا لذلك. وهذا يساعدنا على توفير التكاليف على التكاليف الروتينية.
مثال:
from openai import OpenAI
client = OpenAI()
def get_complexity(question):
prompt = f"Rate the complexity of the question from 1 to 10 for an LLM to answer. Provide only the number.\nQuestion: {question}"
res = client.chat.completions.create(
model="gpt-5.1",
messages=({"role": "user", "content": prompt}),
)
return int(res.choices(0).message.content.strip())
print(get_complexity("Explain convolutional neural networks"))الإخراج:
4
لذلك يقول المصنف الخاص بنا أن التعقيد هو 4، فلا تقلق بشأن استدعاء LLM الإضافي لأن هذا يولد رقمًا واحدًا فقط. يمكن استخدام رقم التعقيد هذا لتوجيه المهام، مثل: التعقيد <7 ثم انتقل إلى نموذج أصغر، وإلا إلى نموذج أكبر.
3. استخدام التخزين المؤقت الفوري
إذا كان نظام LLM يستخدم تعليمات النظام الضخمة أو الكثير من الأمثلة القليلة عبر العديد من المكالمات، فتأكد من وضعها في يبدأ من رسالتك.
بعض النقاط المهمة هنا:
- تأكد من أن البادئة متطابقة تمامًا عبر الطلبات (بما في ذلك جميع الأحرف، بما في ذلك المسافات البيضاء).
- وفقًا لـ OpenAI، ستستفيد النماذج المدعومة تلقائيًا من التخزين المؤقت ولكن يجب أن تكون المطالبة أطول من 1024 رمزًا مميزًا.
- الطلبات التي تستخدم التخزين المؤقت الفوري لها
cached_tokensالقيمة كجزء من الاستجابة.
4. استخدم Batch API للمهام التي يمكن أن تنتظر
لا تتطلب العديد من المهام استجابات فورية، وهذا هو المكان الذي يمكننا فيه استخدام نقطة نهاية Batch غير المتزامنة للاستدلال. من خلال إرسال ملف الطلبات ومنح OpenAI ما يصل إلى 24 ساعة من الوقت لمعالجتها، سيؤدي ذلك إلى تقليل تكاليف الرمز المميز بنسبة 50% مقارنة باستدعاءات OpenAI API المعتادة.
5. قم بقص المخرجات باستخدام معلمات max_tokens وStops
ما نحاول القيام به هنا هو إيقاف إنشاء الرموز المميزة غير الخاضعة للرقابة، لنفترض أنك بحاجة إلى ملخص مكون من 75 كلمة أو كائن JSON محدد، ولا تدع النموذج يستمر في إنشاء نص غير ضروري. بدلا من ذلك يمكننا الاستفادة من المعلمات:
مثال:
from openai import OpenAI
client = OpenAI()
response = client.chat.completions.create(
model="gpt-5.1",
messages=(
{
"role": "system",
"content": "You are a data extractor. Output only raw JSON."
}
),
max_tokens=100,
stop=("\n\n", "}")
)لقد قمنا بتعيين max_tokens على 100 حيث إنها 75 كلمة تقريبًا.
6. الاستفادة من RAG
بدلاً من إغراق نافذة السياق، يمكننا استخدام تقنية الاسترجاع المعزز. سيساعد هذا في تحويل قاعدة المعرفة إلى تضمينات وتخزينها في قاعدة بيانات متجهة. عندما يقوم المستخدم بالاستعلام، فلن يكون السياق بأكمله في نافذة السياق، ولكن سيتم تمرير الأجزاء القليلة ذات الصلة من النص التي تم استردادها للسياق.
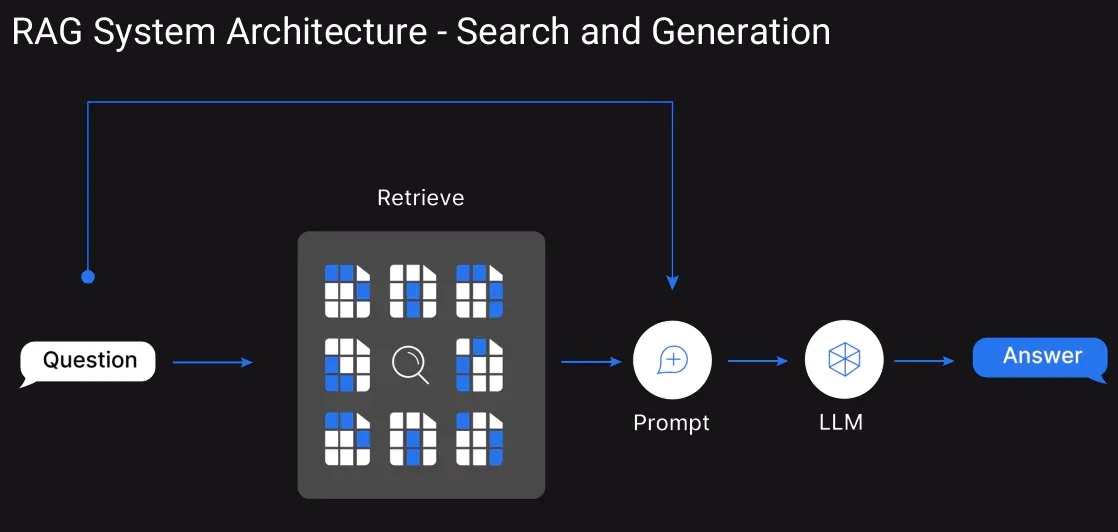
7. إدارة سجل المحادثات دائمًا
ينصب تركيزنا هنا على سجل المحادثة حيث نمرر المدخلات والمخرجات القديمة. بدلاً من إضافة المحادثات بشكل متكرر، يمكننا تنفيذ نهج “النافذة المنزلقة”.
نقوم هنا بإسقاط الرسائل الأقدم بمجرد أن يصبح السياق طويلاً جدًا (قم بتعيين حد معين)، أو نلخص المنعطفات السابقة في رسالة نظام واحدة قبل المتابعة. تأكد من أن نافذة السياق النشط ليست طويلة جدًا لأنها ضرورية للجلسات طويلة الأمد.
وظيفة للتلخيص
from openai import OpenAI
client = OpenAI()
SYSTEM_PROMPT = "You are a concise assistant. Summarize the chat history in 30-40 words."
def summarize_chat(history_text):
response = client.chat.completions.create(
model="gpt-5.1",
messages=(
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": history_text}
)
)
return response.choices(0).message.contentالاستدلال
chat_history = """
User: Hi, I'm trying to understand how embeddings work.
Assistant: Embeddings turn text into numeric vectors.
User: Can I use them for similarity search?
Assistant: Yes, that’s a common use case.
User: Nice, show me simple code.
Assistant: Sure, here's a short example...
"""
summary = summarize_chat(chat_history)سأل المستخدم ما هي التضمينات؟ أوضح المساعد أنهم يقومون بتحويل النص إلى نواقل رقمية. ثم سأل المستخدم عن استخدام التضمينات للبحث عن التشابه؛ أكد المساعد وقدم مثالًا قصيرًا لمقتطف التعليمات البرمجية الذي يوضح البحث الأساسي عن التشابه.
لدينا الآن ملخص يمكن إضافته إلى نافذة سياق النموذج عندما تكون رموز الإدخال أعلى من عتبة محددة.
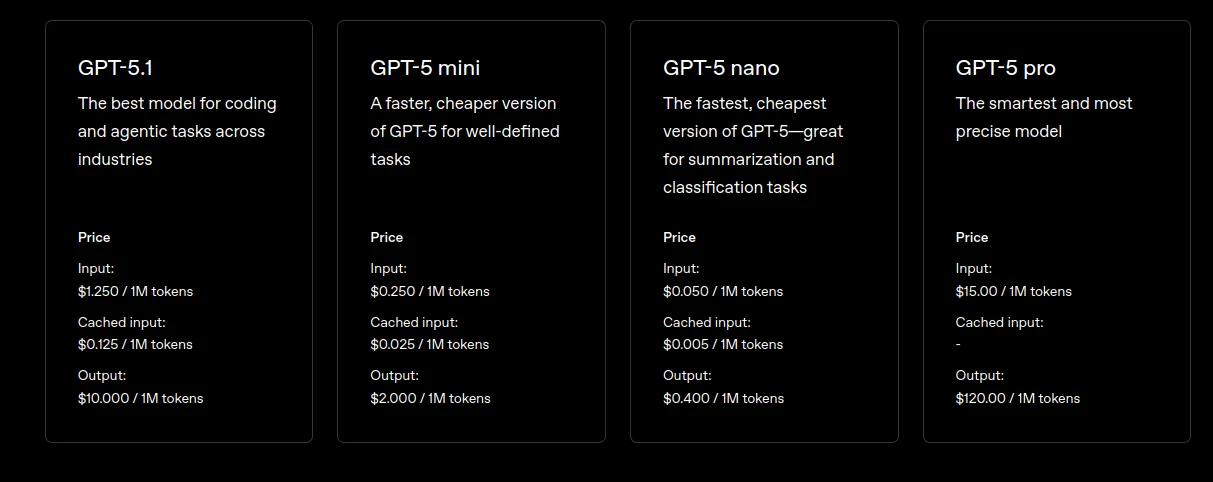
8. الترقية إلى أوضاع النموذج الفعالة
تقوم OpenAI بشكل متكرر بإصدار إصدارات محسنة من نماذجها. تحقق دائمًا من وجود إصدارات “Mini” أو “Nano” الأحدث من أحدث الموديلات. تم تصميمها خصيصًا لتحقيق الكفاءة، وغالبًا ما تقدم أداءً مماثلاً لمهام معينة مقابل جزء صغير من التكلفة.
9. فرض المخرجات المنظمة (JSON)
عندما تحتاج إلى استخراج البيانات أو تنسيقها. يؤدي تحديد مخطط صارم إلى إجبار النموذج على قطع الرموز المميزة غير الضرورية وإرجاع حقول البيانات المطلوبة فقط. تعني الاستجابات الأكثر كثافة عددًا أقل من الرموز المميزة التي تم إنشاؤها في فاتورتك.
الواردات وتعريف الهيكل
from openai import OpenAI
import json
client = OpenAI()
prompt = """
You are an extraction engine. Output ONLY valid JSON.
No explanations. No natural language. No extra keys.
Extract these fields:
- title (string)
- date (string, format: YYYY-MM-DD)
- entities (array of strings)
Text:
"On 2025-12-05, OpenAI introduced Structured Outputs, allowing developers to enforce strict JSON schemas. This improved reliability was welcomed by many engineers."
Return JSON in this exact format:
{
"title": "",
"date": "",
"entities": ()
}
"""الاستدلال
response = client.chat.completions.create(
model="gpt-5.1",
messages=({"role": "user", "content": prompt})
)
data = response.choices(0).message.content
json_data = json.loads(data)
print(json_data)الإخراج:
{'title': 'OpenAI Introduces Structured Outputs', 'date': '2025-12-05', 'entities': ('OpenAI', 'Structured Outputs', 'JSON', 'developers', 'engineers')}
كما نرى يتم إرجاع القاموس المطلوب فقط مع التفاصيل المطلوبة. كما يتم تنظيم الإخراج بدقة كأزواج قيمة المفتاح.
10. استعلامات ذاكرة التخزين المؤقت
على عكس فكرتنا السابقة حول التخزين المؤقت، فإن هذا الأمر مختلف تمامًا. إذا كان المستخدمون يطرحون نفس الأسئلة بشكل متكرر، فقم بتخزين استجابة LLM في قاعدة البيانات الخاصة بك. تحقق من قاعدة البيانات هذه قبل الاتصال بواجهة برمجة التطبيقات (API). هذه الاستجابة المخزنة مؤقتًا أسرع للمستخدم وهي مجانية عمليًا. أيضًا، إذا كنت تعمل مع LangGraph for Agents، فيمكنك استكشاف هذا للتخزين المؤقت على مستوى العقدة: التخزين المؤقت في LangGraph
خاتمة
يعد البناء باستخدام LLMs أمرًا قويًا ولكن النطاق يمكن أن يجعلها باهظة الثمن بسرعة، لذا يصبح فهم معادلة التكلفة أمرًا ضروريًا. من خلال تطبيق المزيج الصحيح من توجيه النموذج، والتخزين المؤقت، والمخرجات المنظمة، وRAG، وإدارة السياق الفعالة، يمكننا خفض تكاليف الاستدلال بشكل كبير. تساعد هذه التقنيات في الحفاظ على جودة النظام مع ضمان بقاء الاستخدام الشامل لـ LLM عمليًا وفعالاً من حيث التكلفة. لا تنس التحقق من لوحة تحكم الفوترة لمعرفة التكاليف بعد تنفيذ كل أسلوب.
الأسئلة المتداولة
ج: الرمز هو وحدة صغيرة من النص، حيث يتوافق ما يقرب من 1000 رمز مع حوالي 750 كلمة.
أ. نظرًا لأن الرموز المميزة للإخراج (من النموذج) غالبًا ما تكون أكثر تكلفة بعدة مرات لكل رمز مميز من الرموز المميزة للإدخال (الموجه).
A. نافذة السياق هي الذاكرة قصيرة المدى (المدخلات والمخرجات السابقة) المرسلة إلى النموذج؛ يزيد السياق الأطول من استخدام الرمز المميز وبالتالي التكلفة.
![]()
شغوف بالتكنولوجيا والابتكار، خريج معهد فيلور للتكنولوجيا. أعمل حاليًا كمتدرب في علوم البيانات، مع التركيز على علوم البيانات. مهتم بشدة بالتعلم العميق والذكاء الاصطناعي التوليدي، ومتلهف لاستكشاف التقنيات المتطورة لحل المشكلات المعقدة وإنشاء حلول مؤثرة.
قم بتسجيل الدخول لمواصلة القراءة والاستمتاع بالمحتوى الذي ينظمه الخبراء.




