
هل تقوم ببناء أنظمة GenAI وترغب في نشرها، أم أنك تريد فقط معرفة المزيد حول FastAPI؟ ثم هذا هو بالضبط ما كنت تبحث عنه! فقط تخيل أن لديك الكثير من تقارير PDF وتريد البحث عن إجابات محددة فيها. يمكنك إما قضاء ساعات في التمرير، أو يمكنك إنشاء نظام يقرأها لك ويجيب على أسئلتك. نحن نقوم ببناء نظام RAG الذي سيتم نشره والوصول إليه من خلال واجهة برمجة التطبيقات (API) باستخدام FastAPI. لذلك، دون مزيد من اللغط، دعونا نتعمق.
ما هو FastAPI؟
FastAPI هو إطار عمل Python لبناء واجهات برمجة التطبيقات (API). يتيح لنا FastAPI استخدام أساليب HTTP للتواصل مع الخادم.
إحدى ميزاته المفيدة هي أنه يقوم تلقائيًا بإنشاء وثائق لواجهات برمجة التطبيقات التي تقوم بإنشائها. بعد كتابة التعليمات البرمجية الخاصة بك وإنشاء واجهات برمجة التطبيقات، يمكنك زيارة عنوان URL واستخدام الواجهة (Swagger UI) لاختبار نقاط النهاية الخاصة بك دون الحاجة إلى ترميز الواجهة الأمامية.
فهم واجهات برمجة تطبيقات REST
REST API هي واجهة تعمل على إنشاء اتصال بين العميل والخادم. REST API هو اختصار لـ Representational State Transfer API. يمكن للعميل إرسال طلبات HTTP إلى نقطة نهاية API محددة، ويقوم الخادم بمعالجة هذه الطلبات. هناك عدد لا بأس به من طرق HTTP الموجودة. سنقوم بتنفيذ عدد قليل منها في مشروعنا باستخدام FastAPI.
طرق HTTP:
في مشروعنا، سوف نستخدم طريقتين للتواصل:
- يحصل: يستخدم هذا لاسترداد المعلومات. سنستخدم طلب GET /health للتحقق مما إذا كان الخادم قيد التشغيل.
- بريد: يُستخدم هذا لإرسال البيانات إلى الخادم لإنشاء شيء ما أو معالجته. سنستخدم طلبات POST/inest و/query. نستخدم POST هنا لأنها تتضمن إرسال بيانات معقدة مثل الملفات أو كائنات JSON. المزيد عن هذا في قسم التنفيذ.
ما هو خرقة؟
يعد توليد الاسترجاع المعزز (RAG) إحدى الطرق لمنح LLM إمكانية الوصول إلى معرفة محددة لم يتم تدريبه عليها في الأصل.
مكونات راج:
- استرجاع: العثور على الجمل ذات الصلة من المستند (المستندات) بناءً على الاستعلام.
- جيل: تمرير هذه الجمل إلى LLM حتى يتمكن من تلخيصها في إجابة.
دعونا نفهم المزيد عن RAG في قسم التنفيذ القادم.
تطبيق
بيان المشكلة: إنشاء نظام يسمح للمستخدمين بتحميل المستندات وتحديداً ملفات .txt أو ملفات PDF. ثم يقوم بفهرستها في قاعدة بيانات قابلة للبحث ويضمن قدرة LLM على الإجابة على الأسئلة المتعلقة بالبيانات الجديدة. سيتم نشر هذا النظام واستخدامه من خلال نقاط نهاية API التي سنقوم بإنشائها من خلال FastAPI.
المتطلبات المسبقة
– سنطلب مفتاح OpenAI API، وسنستخدم نموذج gpt-4.1-mini باعتباره عقل النظام. يمكنك الحصول على مفتاح API من الرابط: (https://platform.openai.com/settings/organization/api-keys)
– بيئة تطوير متكاملة (IDE) لتنفيذ نصوص Python، سأستخدم VSCode للعرض التوضيحي. إنشاء مشروع جديد (مجلد).
– أنشئ ملف .env في مشروعك وأضف مفتاح OpenAI الخاص بك تمامًا كما يلي:
OPENAI_API_KEY=sk-proj... – إنشاء بيئة افتراضية لهذا المشروع (لعزل تبعيات المشروع).
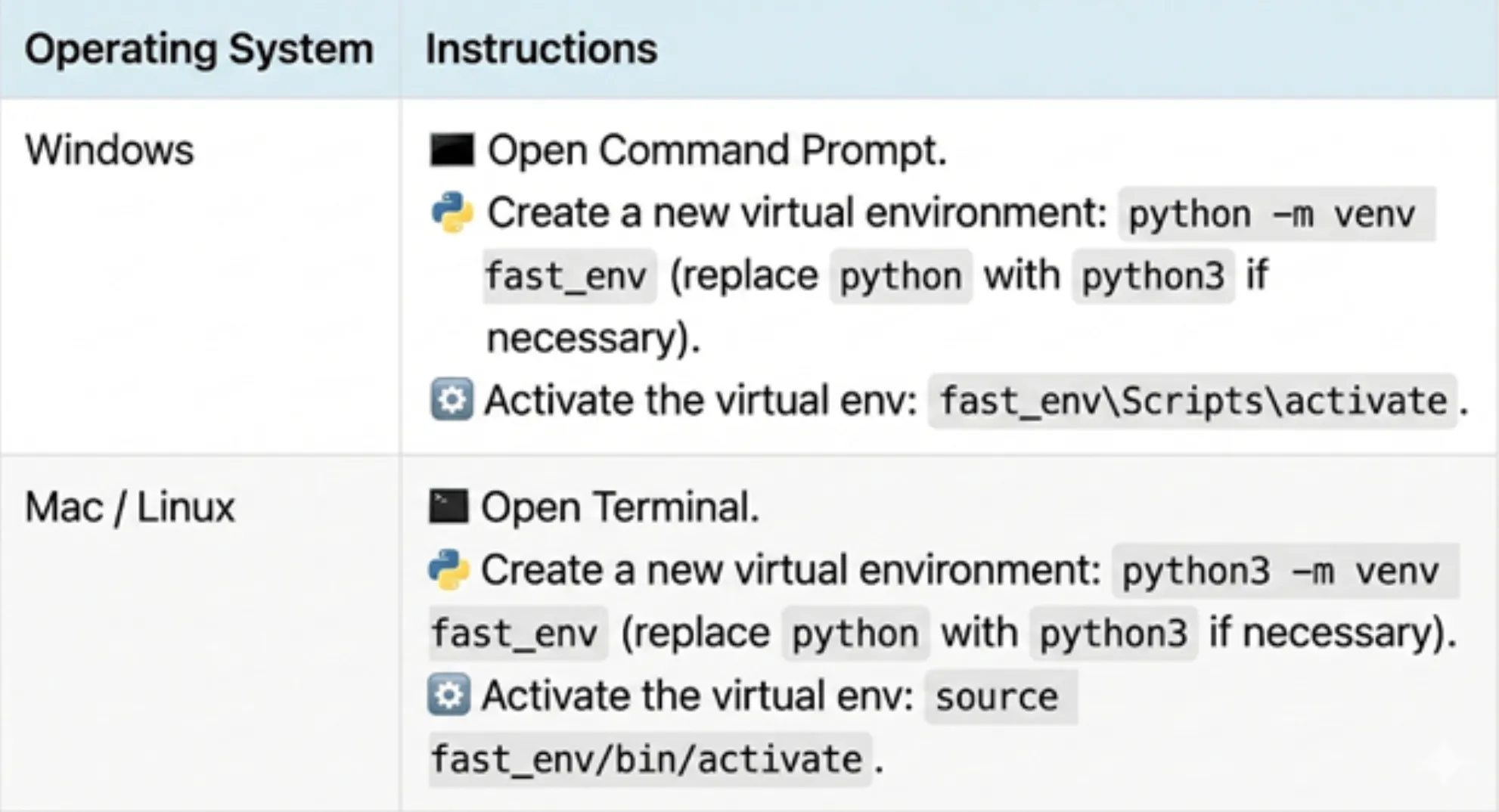
ملحوظة:
- تأكد من إنشاء fast_env في مشروعك، حيث قد تحدث أخطاء في المسار إذا لم يتم تعيين دليل العمل على دليل المشروع.
- بمجرد التنشيط، سيتم احتواء أي حزم تقوم بتثبيتها داخل هذه البيئة.
– قم بتنزيل المدونة أدناه كملف PDF باستخدام “رمز التنزيل” لاستخدامها في نظام RAG الخاص بنا:
متطلبات
لحل هذه المشكلة، نحتاج إلى مكدس يتعامل مع رفع الأحمال الثقيلة بكفاءة:
- واجهة برمجة التطبيقات السريعة: للتعامل مع طلبات الويب وتحميل الملفات.
- لانجشين: لتوسيع قدرات LLM.
- FAISS (بحث التشابه مع الذكاء الاصطناعي على فيسبوك): يساعد في البحث من خلال قطع النص. سوف نستخدمها كقاعدة بيانات متجهة.
- يوفيكرن: لاستضافة الخادم.
يمكنك إنشاء ملف require.txt في مشروعك وتشغيل “pip install -r require.txt”:
fastapi==0.129.0
uvicorn(standard)==0.41.0
python-multipart==0.0.22
langchain==1.2.10
langchain-community==0.4.1
langchain-openai==1.1.10
langchain-core==1.2.13
faiss-cpu==1.13.2
openai==2.21.0
pypdf==6.7.1
python-dotenv==1.2.1نهج التنفيذ
سنقوم بتنفيذ نقطتي نهاية FastAPI:
1. خط أنابيب الاستيعاب (/ابتلاع)
عندما يقوم المستخدم بتحميل ملف، فإننا نستفيد من RecursiveCharacterTextSplitter من لانجشين. تقوم هذه الوظيفة بتقسيم المستندات الطويلة إلى أجزاء أصغر (سنقوم بتكوين الوظيفة لجعل حجم كل قطعة 500 حرف).
يتم بعد ذلك تحويل هذه القطع إلى تضمينات وتخزينها في ملفاتنا فايس الفهرس (قاعدة بيانات المتجهات). سوف نستخدم وحدة التخزين المحلية لـ FAISS، بحيث لا يتم فقدان المستندات التي تم تحميلها حتى في حالة إعادة تشغيل الخادم.
2. مسار الاستعلام (/query)
عندما تطرح سؤالاً، يتحول السؤال إلى متجه. نستخدم بعد ذلك FAISS لاسترداد الأجزاء العلوية k (عادةً 4) من النص الأكثر تشابهًا مع السؤال.
وأخيراً نستخدم LCEL (لغة التعبير LangChain) لتنفيذ مكون التوليد في RAG. نرسل السؤال وتلك الأجزاء الأربعة إلى gpt-4.1-mini مع مطالبتنا للحصول على الإجابة.
كود بايثون
في نفس مجلد المشروع، أنشئ نصين برمجيين، rag_pipeline.py وmain.py:
rag_pipeline.py:
الواردات
import os
from langchain_community.document_loaders import TextLoader, PyPDFLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings, ChatOpenAI
from langchain_community.vectorstores import FAISS
from langchain_core.runnables import RunnablePassthrough, RunnableParallel
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_core.documents import Document
from dotenv import load_dotenv
from typing import List إعدادات
# Loading OpenAI API key
load_dotenv()
# Config
FAISS_INDEX_PATH = "faiss_index"
EMBEDDING_MODEL = "text-embedding-3-small"
LLM_MODEL = "gpt-4.1-mini"
CHUNK_SIZE = 500
CHUNK_OVERLAP = 50ملاحظة: تأكد من إضافة مفتاح API في ملف .env
التهيئة وتحديد الوظائف
# Shared state
_vectorstore: FAISS | None = None
embeddings = OpenAIEmbeddings(model=EMBEDDING_MODEL)
def _load_vectorstore() -> FAISS | None:
"""Load existing FAISS index from disk if it exists."""
global _vectorstore
if _vectorstore is None and os.path.exists(FAISS_INDEX_PATH):
_vectorstore = FAISS.load_local(
FAISS_INDEX_PATH,
embeddings,
allow_dangerous_deserialization=True
)
return _vectorstore
def ingest_document(file_path: str, filename: str = "") -> int:
"""
Chunks, Embeds, Stores in FAISS and returns the number of chunks stored.
"""
global _vectorstore
# 1. Load
if file_path.endswith(".pdf"):
loader = PyPDFLoader(file_path)
else:
loader = TextLoader(file_path)
documents = loader.load()
# Overwriting source with the filename
display_name = filename or os.path.basename(file_path)
for doc in documents:
doc.metadata("source") = display_name
# 2. Chunk
splitter = RecursiveCharacterTextSplitter(
chunk_size=CHUNK_SIZE,
chunk_overlap=CHUNK_OVERLAP,
separators=("\n\n", "\n", ".", " ", "")
)
chunks = splitter.split_documents(documents)
# 3. Embed and Store
if _vectorstore is None:
_load_vectorstore()
if _vectorstore is None:
_vectorstore = FAISS.from_documents(chunks, embeddings)
else:
_vectorstore.add_documents(chunks)
# 4. Persist to disk
_vectorstore.save_local(FAISS_INDEX_PATH)
return len(chunks)
def _format_docs(docs: List(Document)) -> str:
"""Concatenate document page_content to add to the prompt."""
return "\n\n".join(doc.page_content for doc in docs)تساعد هذه الوظائف على تقطيع المستندات وتقسيم النص إلى أجزاء مضمنة (باستخدام نموذج التضمين: text-embedding-3-small) وتخزينها في فهرس FAISS (متجر المتجهات).
تعريف المسترد والمولد
def query_rag(question: str, top_k: int = 4) -> dict:
"""
Returns answer text and source references.
"""
vs = _load_vectorstore()
if vs is None:
return {
"answer": "No documents have been ingested yet. Please upload a document first.",
"sources": ()
}
# Retriever
retriever = vs.as_retriever(
search_type="similarity",
search_kwargs={"k": top_k}
)
# Prompt
prompt = PromptTemplate(
input_variables=("context", "question"),
template="""You are a helpful assistant. Use only the context below to answer the question.
If the answer is not in the context, say "I don't know based on the provided documents."
Context:
{context}
Question: {question}
Answer:"""
)
llm = ChatOpenAI(model=LLM_MODEL, temperature=0)
# LCEL chain
# Step 1:
retrieve = RunnableParallel(
{
"source_documents": retriever,
"context": retriever | _format_docs,
"question": RunnablePassthrough(),
}
)
# Step 2:
answer_chain = prompt | llm | StrOutputParser()
# Invoke
retrieved = retrieve.invoke(question)
answer = answer_chain.invoke(retrieved)
# Extracting sources
sources = list({
doc.metadata.get("source", "unknown")
for doc in retrieved("source_documents")
})
return {
"answer": answer,
"sources": sources,
}لقد قمنا بتنفيذ RAG الخاص بنا، والذي يسترد 4 مستندات باستخدام بحث التشابه ويمرر السؤال والسياق والموجه إلى المولد (gpt-4.1-mini).
أولاً، يتم جلب المستندات ذات الصلة باستخدام الاستعلام، ثم يتم استدعاء سلسلة الإجابة التي تجيب على السؤال كسلسلة باستخدام StrOutputParser().
ملاحظة: سيتم تمرير أعلى k والسؤال كوسائط للوظيفة.
main.py
الواردات
import os
import tempfile
from fastapi import FastAPI, UploadFile, File, HTTPException
from pydantic import BaseModel
from rag_pipeline import ingest_document, query_ragلقد قمنا باستيراد وظائف ingest_document وquery_rag، والتي سيتم استخدامها بواسطة نقاط نهاية API التي سنحددها.
إعدادات
app = FastAPI(
title="RAG API",
description="Upload documents and query them using RAG",
version="1.0.0"
)
ALLOWED_EXTENSIONS = {
"application/pdf": ".pdf",
"text/plain": ".txt",
}
class QueryRequest(BaseModel):
question: str
top_k: int = 4
class QueryResponse(BaseModel):
answer: str
sources: list(str)استخدام Pydantic لتحديد بنية المدخلات إلى واجهة برمجة التطبيقات بدقة.
ملاحظة: يمكن إضافة أدوات التحقق هنا أيضًا لإجراء عمليات فحص معينة (على سبيل المثال: للتحقق مما إذا كان رقم الهاتف يتكون من 10 أرقام بالضبط)
/ واجهة برمجة التطبيقات الصحية
@app.get("/health", tags=("Health"))
def health():
"""Check if the API is running."""
return {"status": "ok"}تعد واجهة برمجة التطبيقات (API) هذه مفيدة لتأكيد ما إذا كان الخادم قيد التشغيل.
ملاحظة: نقوم بتغليف وظائف واجهة برمجة التطبيقات (API) باستخدام مُزخرف؛ هنا، نستخدم @app لأننا قمنا بتهيئة FastAPI بهذا المتغير مسبقًا. أيضًا، يتبعه أسلوب HTTP، ومن هنا get(). ثم نقوم بتمرير المسار إلى نقطة النهاية، وهي “/ الصحة” هنا.
/ingest API (لأخذ المستند من المستخدم)
@app.post("/ingest", tags=("Ingestion"), summary="Upload and index a document")
async def ingest(file: UploadFile = File(...)):
"""
Upload a **.txt** or **.pdf** file.
"""
if file.content_type not in ALLOWED_EXTENSIONS:
raise HTTPException(
status_code=400,
detail=f"Unsupported file type '{file.content_type}'. Only .txt and .pdf are supported."
)
suffix = ALLOWED_EXTENSIONS(file.content_type)
contents = await file.read()
with tempfile.NamedTemporaryFile(delete=False, suffix=suffix) as tmp:
tmp.write(contents)
tmp_path = tmp.name
try:
num_chunks = ingest_document(tmp_path, filename=file.filename)
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
finally:
os.unlink(tmp_path)
return {
"message": f"Successfully ingested '{file.filename}'",
"chunks_indexed": num_chunks
}تضمن هذه الوظيفة قبول ملف .txt أو .pdf فقط ثم تستدعي وظيفة ingest_document() المحددة في البرنامج النصي rag_pipeline.py.
/query API (لتشغيل خط أنابيب RAG)
@app.post("/query", response_model=QueryResponse, tags=("Query"), summary="Ask a question about your documents")
def query(request: QueryRequest):
"""
Ask a question related to the provided document.
The pipeline will return the answer and the source file names used to generate it.
"""
if not request.question.strip():
raise HTTPException(status_code=400, detail="Question cannot be empty.")
try:
result = query_rag(request.question, request.top_k)
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
return QueryResponse(answer=result("answer"), sources=result("sources"))أخيرًا، قمنا بتعريف واجهة برمجة التطبيقات (API) التي تستدعي الدالة query_rag() وترجع الاستجابة للمستخدم وفقًا للمستندات. دعونا نختبره بسرعة.
تشغيل التطبيق
– قم بتشغيل الأمر أدناه في موجه الأوامر أو المحطة الطرفية:
uvicorn main:app --reloadملحوظة: تأكد من تنشيط بيئتك وتثبيت كافة التبعيات. وإلا قد ترى أخطاء تتعلق بنفس الشيء.
– الآن يجب أن يكون التطبيق جاهزًا للعمل هنا: http://127.0.0.1:8000
– افتح Swagger UI (الواجهة) باستخدام عنوان URL أدناه:
http://127.0.0.1:8000/docs
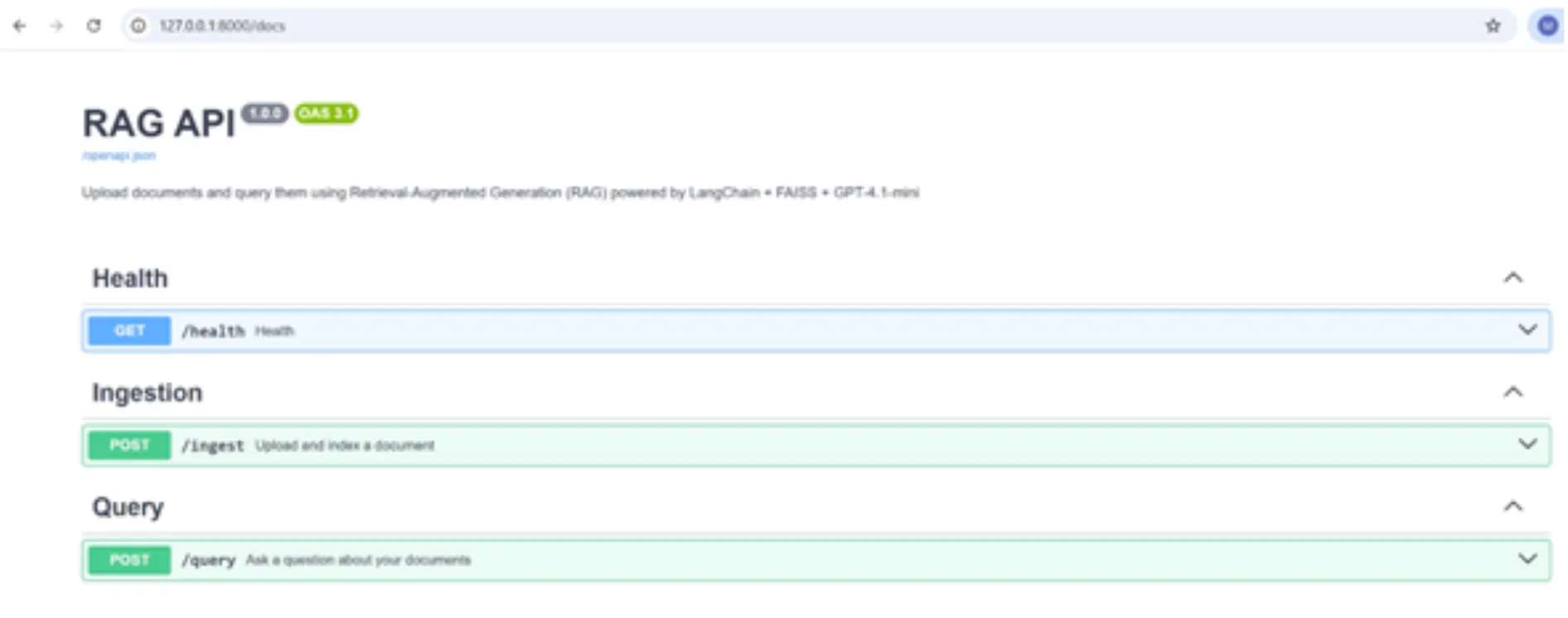
عظيم! يمكننا اختبار واجهات برمجة التطبيقات الخاصة بنا باستخدام الواجهة فقط عن طريق تمرير الوسائط إلى واجهات برمجة التطبيقات.
اختبار كل من واجهات برمجة التطبيقات
1./ استيعاب واجهة برمجة التطبيقات:
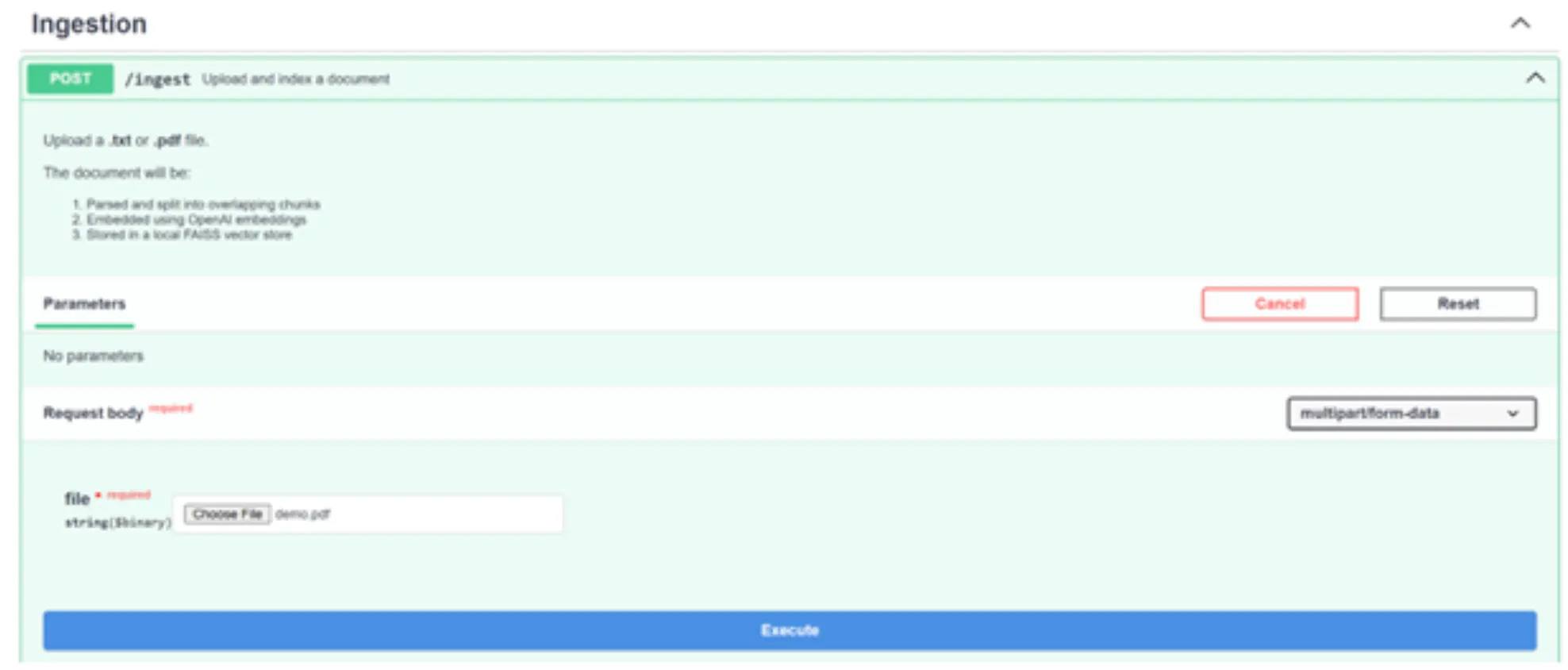
انقر فوق “جربه” وقم بتمرير ملف demo.pdf (يمكنك استبداله بأي ملف PDF آخر أيضًا). وانقر على تنفيذ.
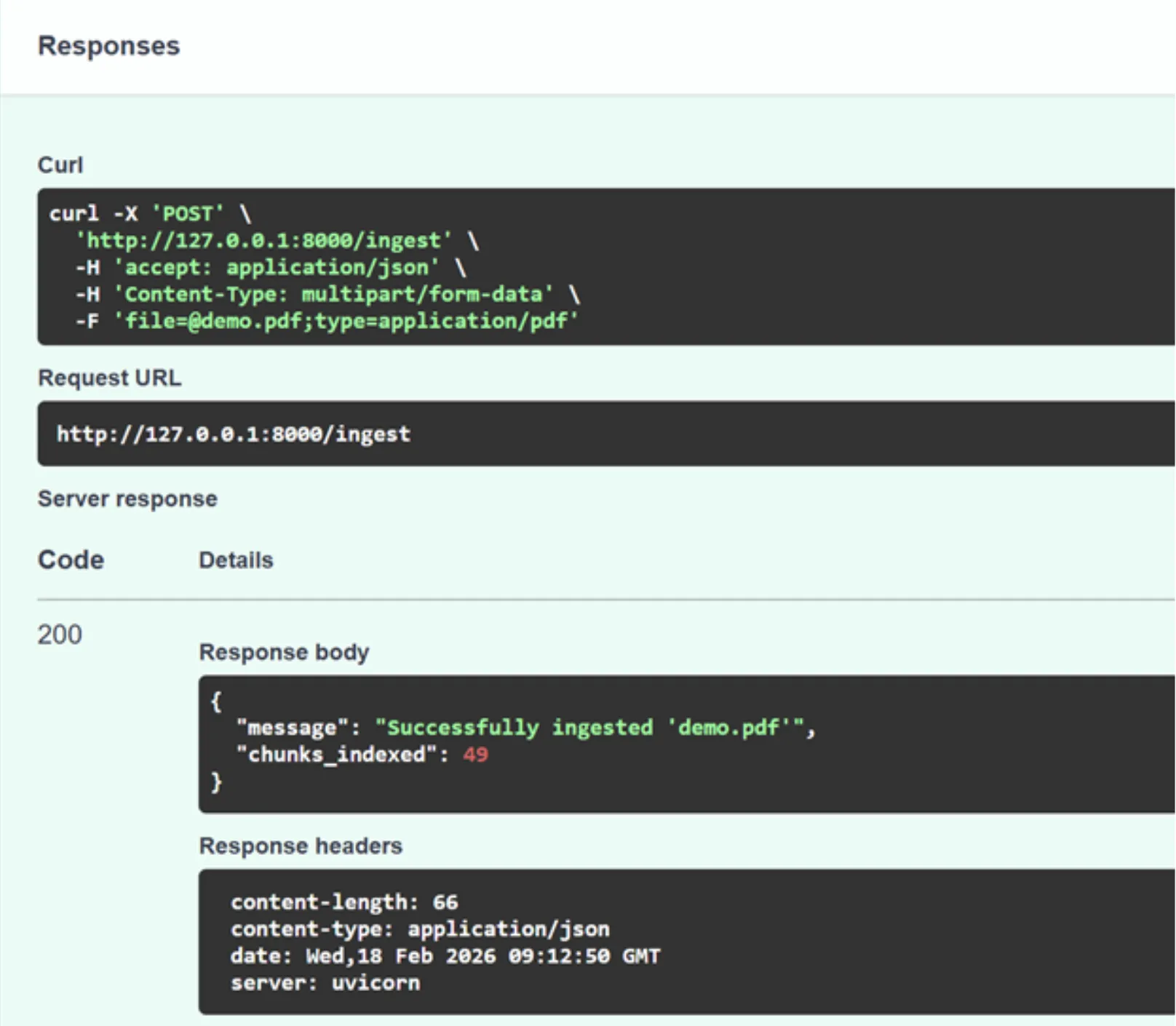
عظيم! قامت واجهة برمجة التطبيقات (API) بمعالجة طلبنا وإنشاء متجر المتجهات باستخدام ملف PDF. يمكنك التحقق من ذلك من خلال النظر إلى مجلد مشروعك، حيث يمكنك رؤية مجلد faiss_index الجديد.
2. / واجهة برمجة التطبيقات للاستعلام:
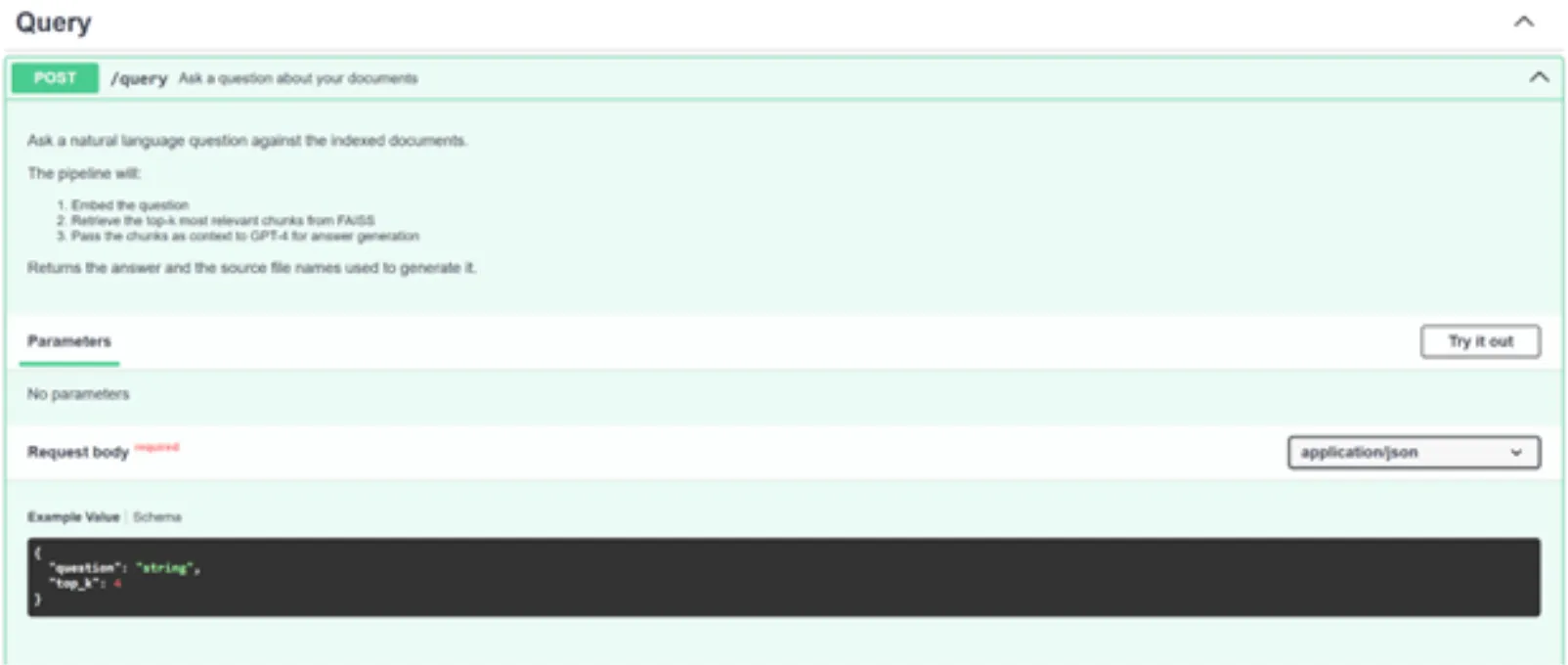
الآن، انقر فوق “جربها” وقم بتمرير الوسيطات أدناه (لا تتردد في استخدام مطالبات وملفات PDF مختلفة).
{
"question": "Name 3 applications of Machine Learning",
"top_k": 4
}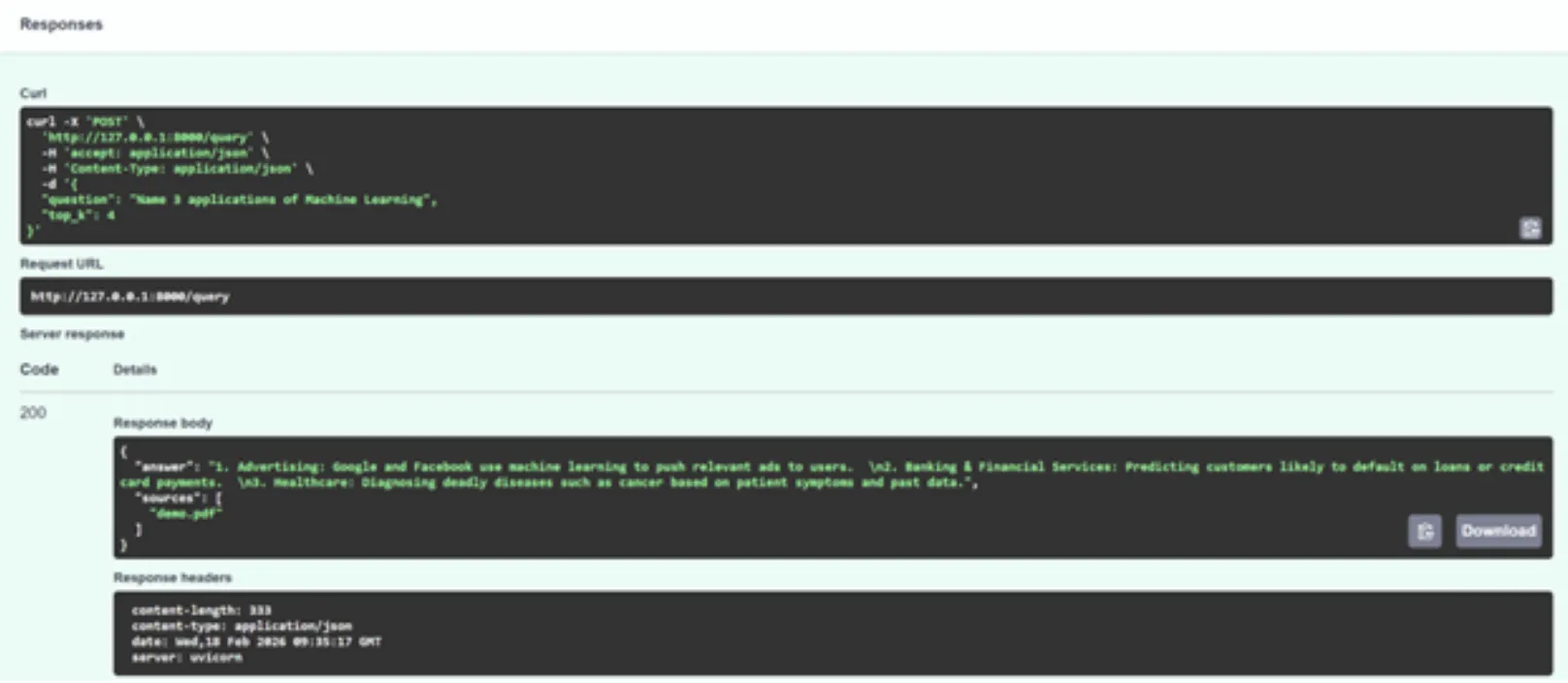
كما هو متوقع، تبدو الاستجابة مرتبطة جدًا بالمحتوى الموجود في ملف PDF. يمكنك المضي قدمًا واللعب باستخدام المعلمة top-k واختبارها أيضًا بأسئلة مختلفة.

فهم رموز حالة HTTP
رموز حالة HTTP إبلاغ العميل ما إذا كان الطلب ناجحًا أو إذا حدث خطأ ما.
فئات رمز الحالة:
نجاح
*تم استلام الطلب ومعالجته بنجاح.
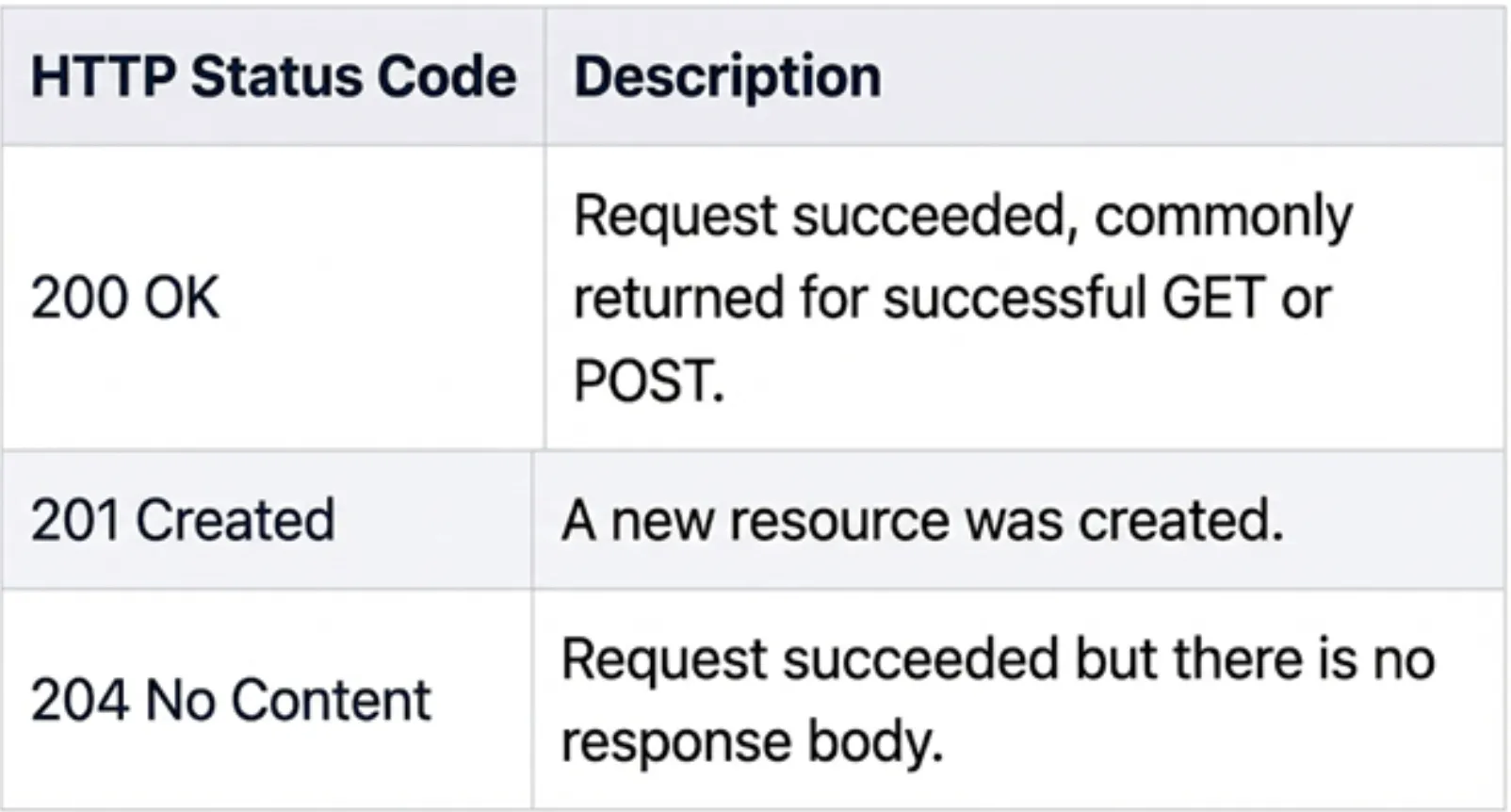
في مشروعنا:
- /health ترجع 200 OK عند تشغيل الخادم.
- /inest و /query يُرجعان 200 OK عند النجاح.
أخطاء العميل
* الخطأ ناتج عن شيء أرسله العميل.

في مشروعنا:
- إذا قمت بتحميل نوع ملف غير متوقع (ليس ملف PDF أو txt)، فسترجع واجهة برمجة التطبيقات رمز الحالة 400.
- إذا كان السؤال فارغًا في /query، فستُرجع واجهة برمجة التطبيقات رمز الحالة 400.
- يقوم FastAPI بإرجاع رمز الحالة 422 إذا كان نص الطلب لا يتطابق مع نموذج Pydantic المتوقع الذي حددناه.
أخطاء الخادم
* تشير إلى حدوث خطأ ما من جانب الخادم.

في مشروعنا:
- إذا فشل استيعاب التعليمات البرمجية أو الاستعلام عنها بسبب خطأ FAISS أو خطأ OpenAI، تقوم واجهة برمجة التطبيقات بإرجاع رمز الحالة 500.
إقرأ أيضاً:
خاتمة
لقد نجحنا في تنفيذ وتعلم بناء ونشر نظام RAG باستخدام FastAPI. لقد أنشأنا هنا واجهة برمجة التطبيقات (API) التي تستوعب ملفات PDF/.txt، وتسترجع المعلومات ذات الصلة، وتولد الإجابات ذات الصلة. يسهل جزء النشر الوصول إلى أنظمة GenAI أو أنظمة ML التقليدية في تطبيقات العالم الحقيقي. يمكننا تحسين RAG الخاص بنا بشكل أكبر من خلال تحسين استراتيجية التقطيع والجمع بين طرق الاسترجاع المختلفة لاستفساراتنا
الأسئلة المتداولة
-reload يجعل خادم FastAPI يتم إعادة تشغيله تلقائيًا عند تغيير التعليمات البرمجية، مما يعكس التحديثات دون إعادة تشغيل الخادم يدويًا.
نستخدم POST لأن الاستعلامات تتضمن بيانات منظمة مثل كائنات JSON. يمكن أن تكون هذه كبيرة ومعقدة. وهذه تختلف عن طلبات GET التي تُستخدم لعمليات الاسترجاع البسيطة.
يوازن MMR (الحد الأقصى للملاءمة الهامشية) بين الملاءمة والتنوع عند تحديد أجزاء المستند، مما يضمن أن النتائج المستردة مفيدة دون أن تكون زائدة عن الحاجة.
تؤدي زيادة top_k إلى استرداد المزيد من الأجزاء الخاصة بـ LLM، مما قد يؤدي إلى تشويش محتمل في الإجابات التي تم إنشاؤها بسبب وجود محتوى غير ذي صلة.
![]()
شغوف بالتكنولوجيا والابتكار، خريج معهد فيلور للتكنولوجيا. أعمل حاليًا كمتدرب في علوم البيانات، مع التركيز على علوم البيانات. مهتم بشدة بالتعلم العميق والذكاء الاصطناعي التوليدي، ومتلهف لاستكشاف التقنيات المتطورة لحل المشكلات المعقدة وإنشاء حلول مؤثرة.
قم بتسجيل الدخول لمواصلة القراءة والاستمتاع بالمحتوى الذي ينظمه الخبراء.


