
[ad_1]
بعد 3 أشهر فقط من إطلاق نموذجهم المتطور Gemini 3 Pro، أصبح Google DeepMind هنا مع أحدث إصدار له: الجوزاء 3.1 برو.
ترقية جذرية من حيث القدرات والسلامة، يسعى طراز Gemini 3.1 Pro إلى أن يكون في متناول الجميع وقابلاً للتشغيل. بغض النظر عن تفضيلاتك أو النظام الأساسي أو القوة الشرائية، فإن النموذج لديه الكثير ليقدمه لجميع المستخدمين.
سأختبر قدرات Gemini 3.1 Pro وسأشرح ميزاته الرئيسية بالتفصيل. بدءًا من كيفية الوصول إلى Gemini 3.1 Pro وحتى المعايير، تم التطرق إلى كل ما يتعلق بهذا النموذج الجديد في هذه المقالة.
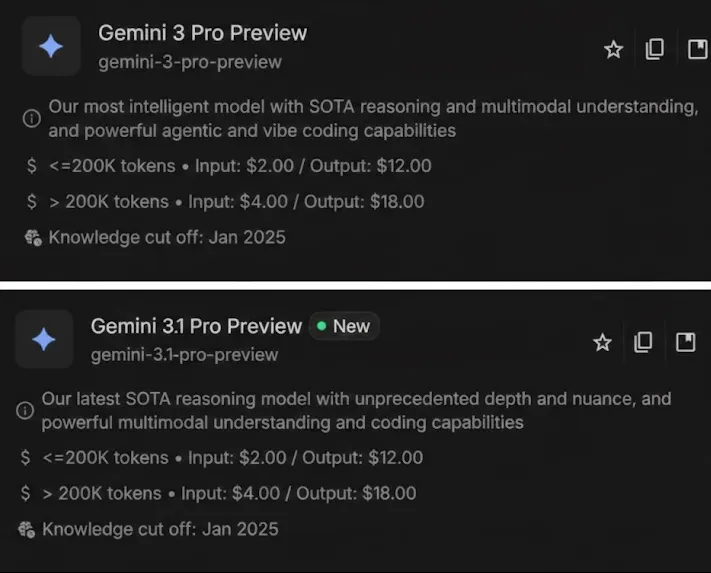
الجوزاء 3.1 برو: ما الجديد؟
Gemini 3.1 Pro هو أحدث عضو في عائلة طرازات Gemini. كالعادة يأتي النموذج مع عدد مذهل من الميزات والتحسينات من الماضي. بعض من أبرزها هي:
- 1 مليون نافذة سياقية: يحافظ على قدرة إدخال رمزية رائدة في الصناعة تبلغ مليون رمز، مما يسمح له بمعالجة أكثر من 1500 صفحة من النصوص أو مستودعات التعليمات البرمجية بأكملها في موجه واحد.
- الأداء المنطقي المتقدم: فهو يقدم أكثر من ضعف الأداء المنطقي الذي يقدمه Gemini 3 Pro، ويسجل النقاط 77.1% على معيار ARC-AGI-2.
- تعزيز موثوقية الوكيل: تم تحسينه خصيصًا لسير العمل المستقل، بما في ذلك نقطة نهاية واجهة برمجة التطبيقات (API) المخصصة (Gemini-3.1-pro-preview-customtools) لتنسيق الأدوات عالية الدقة وتنفيذ bash.
- التسعير: التكلفة/الرمز المميز لأحدث طراز هو نفس تكلفة الطراز السابق. بالنسبة لأولئك الذين اعتادوا على الإصدار Pro، سيحصلون على ترقية مجانية.
- ترميز فيبي المتقدم: يتعامل النموذج مع الترميز المرئي بشكل جيد للغاية. يمكنه إنشاء صور SVG متحركة جاهزة لموقع الويب من خلال التعليمات البرمجية فقط، مما يعني تحجيمًا واضحًا وأحجام ملفات صغيرة.
- الهلوسة: لقد عالج Gemini 3.1 Pro مشكلة الهلوسة بشكل مباشر عن طريق تقليل معدل الهلوسة من 88% إلى 50% عبر AA-Omniscience: معيار المعرفة والهلوسة
- التفكير الحبيبي: يضيف النموذج مزيدًا من التفاصيل إلى خيار التفكير الذي يقدمه سابقه. الآن يمكن للمستخدمين الاختيار بين معايير التفكير العالية والمتوسطة والمنخفضة.
| مستوى التفكير | الجوزاء 3.1 برو | الجوزاء 3 برو | الجوزاء 3 فلاش | وصف |
| الحد الأدنى | غير معتمد | غير معتمد | المدعومة |
يطابق إعداد عدم التفكير لمعظم الاستعلامات. قد يفكر النموذج بالحد الأدنى لمهام البرمجة المعقدة. يقلل من زمن الوصول للدردشة أو تطبيقات الإنتاجية العالية. |
| قليل | المدعومة | المدعومة | المدعومة |
يقلل الكمون والتكلفة. الأفضل للتعليمات البسيطة التالية أو التطبيقات عالية الإنتاجية. |
| واسطة | المدعومة | غير معتمد | المدعومة |
التفكير المتوازن لمعظم المهام. |
| عالي | مدعوم (افتراضي، ديناميكي) | مدعوم (افتراضي، ديناميكي) | مدعوم (افتراضي، ديناميكي) |
يزيد من عمق التفكير. قد يزيد زمن الوصول، لكن المخرجات تكون مدروسة بعناية أكبر. |
التدريب العملي: دعونا نحظى ببعض المرح
كل الكلام في العالم لن يصل إلى أي شيء إذا فشل الأداء في الممارسة العملية. لتقييم Gemini 3.1 Pro بشكل صحيح، قمت باختباره عبر ثلاث فئات:
- المنطق المعقد
- توليد التعليمات البرمجية وتصحيح الأخطاء
- توليف السياق الطويل
المهمة 1: التفكير المنطقي متعدد الخطوات
ماذا يختبر هذا: التفكير في سلسلة الأفكار، والتعامل مع القيود، ومقاومة الهلوسة.
اِسْتَدْعَى:
“يتم إعطاؤك السيناريو التالي:
تم تعيين خمسة محللين – A وB وC وD وE – لثلاثة مشاريع: Alpha وBeta وGamma.
قواعد:
1. يجب أن يكون لكل مشروع محلل واحد على الأقل.
2. لا يمكن لـ A العمل مع C.
3. يجب تعيين B لنفس المشروع مثل D.
4. لا يمكن أن يكون E على Alpha.
5. لا يجوز لأي مشروع أن يضم أكثر من ثلاثة محللين.
سؤال: قم بإدراج جميع مجموعات المهام الصالحة. أظهر أسبابك بوضوح وتأكد من عدم انتهاك أي قاعدة.
“
إجابة:
تعامل Gemini 3.1 Pro مع المنطق الثقيل دون الانهيار في التناقضات، وهو المكان الذي تتعثر فيه معظم النماذج. أظهر الاتساق والوضوح في تعداد المجموعات الصحيحة عمقًا جديًا في التفكير.
المهمة 2: إنشاء التعليمات البرمجية وإعادة البناء
ماذا يختبر هذا: التفكير المنظم، والوعي بحالة الحافة، وتصحيح الكود، وواقعية الإنتاج.
اِسْتَدْعَى:
“يتم إعطاؤك وظيفة بايثون التالية:
def process_orders(orders):
total = 0
for order in orders:
if order("status") == "completed":
total += order("amount")
return totalإعادة صياغة هذه الوظيفة إلى:
1. التعامل مع المفاتيح المفقودة بأمان.
2. تجاهل المبالغ السلبية.
3. سجل تخطي الإدخالات غير الصالحة.
4. كن جاهزًا للإنتاج باستخدام تلميحات الكتابة والمستندات.
5. قم بتضمين اختبارات الوحدة لحالات الحافة.
قم بإرجاع كود Python النظيف والمنظم جيدًا فقط.
“
إجابة:
import logging
import unittest
from typing import List, Dict, Any
logger = logging.getLogger(__name__)
def process_orders(orders: List(Dict(str, Any))) -> float:
"""
Process a list of order dictionaries and calculate
the total amount of completed orders.
"""
total: float = 0.0
if not isinstance(orders, list):
logger.error("'orders' must be a list.")
return total
for index, order in enumerate(orders):
if not isinstance(order, dict):
logger.warning("Skipping index %d: Not a dictionary.", index)
continue
if order.get("status") != "completed":
continue
if "amount" not in order:
logger.warning("Skipping index %d: Missing 'amount'.", index)
continue
amount = order("amount")
if not isinstance(amount, (int, float)) or isinstance(amount, bool):
logger.warning("Skipping index %d: 'amount' must be numeric.", index)
continue
if amount < 0:
logger.warning("Skipping index %d: Negative amount (%.2f).", index, amount)
continue
total += float(amount)
return total
class TestProcessOrders(unittest.TestCase):
def setUp(self):
logging.disable(logging.WARNING)
def tearDown(self):
logging.disable(logging.NOTSET)
def test_valid_completed_orders(self):
orders = (
{"status": "completed", "amount": 100},
{"status": "completed", "amount": 50.5}
)
self.assertEqual(process_orders(orders), 150.5)
def test_ignore_pending_orders(self):
orders = (
{"status": "pending", "amount": 100},
{"status": "completed", "amount": 50}
)
self.assertEqual(process_orders(orders), 50.0)
def test_missing_keys_skipped(self):
orders = (
{"amount": 100},
{"status": "completed"},
{"status": "completed", "amount": 20}
)
self.assertEqual(process_orders(orders), 20.0)
def test_negative_amounts_ignored(self):
orders = (
{"status": "completed", "amount": -10},
{"status": "completed", "amount": 3بدا الكود المُعاد هيكلته مدركًا للإنتاج وليس على مستوى اللعبة. لقد توقعت حالات الحافة، وفرضت سلامة النوع، وتضمنت اختبارات ذات معنى. هذا هو نوع المخرجات التي تحترم في الواقع معايير التنمية في العالم الحقيقي.
المهمة 3: التوليف التحليلي طويل السياق
ماذا يختبر هذا: ضغط المعلومات والتلخيص المنظم والتفكير عبر السياق.
اِسْتَدْعَى:
“يوجد أدناه تقرير أعمال اصطناعي:
الشركة: NovaGrid AI
إيرادات 2022: 12 مليون دولار
2023 ربح : 28 مليون دولار
2024 ربح: 46 مليون دولار
ارتفع معدل تراجع العملاء من 4% إلى 11% في عام 2024.
وارتفع الإنفاق على البحث والتطوير بنسبة 70% في عام 2024.
وانخفض هامش التشغيل من 18% إلى 9%.
ارتفع عدد عملاء المؤسسات بنسبة 40%.
انخفض عدد عملاء الشركات الصغيرة والمتوسطة بنسبة 22%.
تضاعفت تكاليف البنية التحتية السحابية.
مهمة:
1. تشخيص الأسباب الجذرية الأكثر احتمالاً لانخفاض الهامش.
2. تحديد المخاطر الإستراتيجية.
3. التوصية بثلاثة إجراءات مدعومة بالبيانات.
4. قدم إجابتك في شكل مذكرة تنفيذية منظمة.
“
إجابة:
لقد ربطت الإشارات المالية، والتحولات التشغيلية، والمخاطر الاستراتيجية في سرد تنفيذي متماسك. تُظهر القدرة على تشخيص ضغط الهامش مع موازنة إشارات النمو منطقًا تجاريًا قويًا. يبدو الأمر وكأنه شيء قد يقوم مستشار استراتيجي حاد بصياغته، وليس ملخصًا عامًا.
ملحوظة: لم أستخدم المهام القياسية “إنشاء لوحة معلومات” حيث أن معظم الموديلات الحديثة مثل Sonnet 4.6 وKimi K 2.5 قادرة على إنشاء واحدة بسهولة. لذلك لن يمثل هذا تحديًا كبيرًا لنموذج قادر على ذلك.
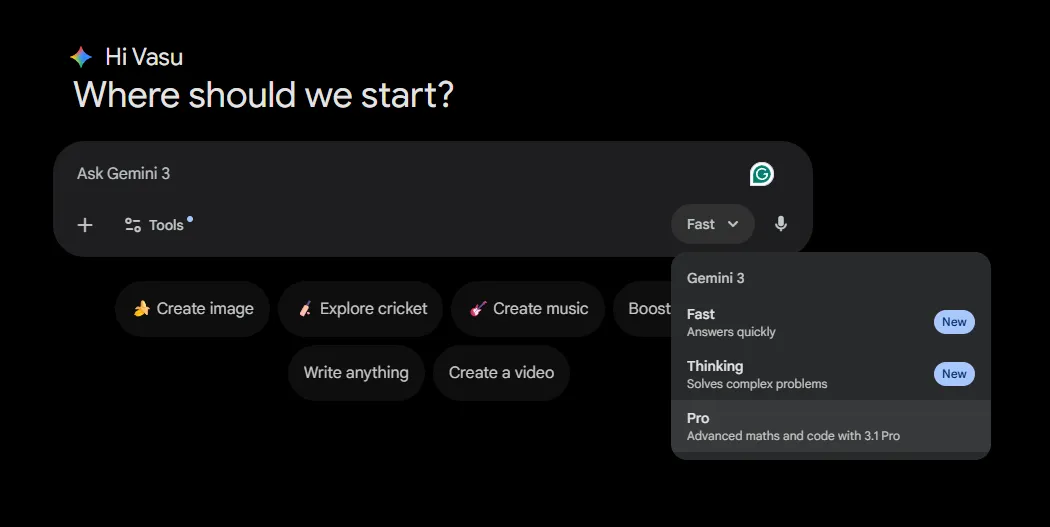
كيفية الوصول إلى الجوزاء 3.1 برو؟
على عكس نماذج Pro السابقة، يمكن لجميع المستخدمين الوصول إلى Gemini 3.1 Pro مجانًا على النظام الأساسي الذي يختارونه.
الآن بعد أن اتخذت قرارك بشأن استخدام Gemini 3.1 Pro، دعنا نرى كيف يمكنك الوصول إلى النموذج.
- واجهة مستخدم ويب الجوزاء: يتوفر الآن لمستخدمي الإصدار المجاني وGemini Advanced الإصدار 3.1 Pro ضمن خيار قسم الطراز.
- واجهة برمجة التطبيقات: متاح عبر Google AI Studio للمطورين (النماذج/Gemini-3.1-pro).
| نموذج | رموز الإدخال الأساسية | 5m ذاكرة التخزين المؤقت يكتب | 1H ذاكرة التخزين المؤقت يكتب | ذاكرة التخزين المؤقت الزيارات والتحديثات | رموز الإخراج |
| Gemini 3.1 Pro (أقل من 200 ألف رمز) | 2 دولار / 1 مليون رمز | ~0.20 دولار – 0.40 دولار / 1 مليون رمز | ~4.50 دولارًا أمريكيًا / مليون رمز لكل ساعة تخزين | لم يتم توثيقها رسميا | 12 دولارًا / 1 مليون رمزًا |
| Gemini 3.1 Pro (> 200 ألف رمز) | 4 دولارات / 1 مليون رمز | ~0.20 دولار – 0.40 دولار / 1 مليون رمز | ~4.50 دولارًا أمريكيًا / مليون رمز لكل ساعة تخزين | لم يتم توثيقها رسميا | 18 دولارًا / 1 مليون رمزًا |
- المنصات السحابية: يتم طرحه على NotebookLM وVertex AI من Google Cloud وMicrosoft Foundry.
المعايير
ولقياس مدى جودة هذا النموذج، فإن المعايير المرجعية سوف تساعد.
هناك الكثير لفك تشفيره هنا. لكن التحسن الأكثر إثارة للدهشة على الإطلاق هو بالتأكيد في ألغاز التفكير التجريدي.
اسمحوا لي أن أضع الأمور في نصابها الصحيح: تم إصدار Gemini 3 Pro بنتيجة ARC-AGI-2 بنسبة 31.1%. كان هذا هو الأعلى في ذلك الوقت ويعتبر اختراقًا لمعايير LLM. تقدم سريعًا لمدة 3 أشهر فقط، وقد تجاوزت هذه النتيجة خليفتها مضاعفة الهامش!
هذه هي الوتيرة السريعة التي تتحسن بها نماذج الذكاء الاصطناعي.
إذا لم تكن على دراية بما تختبره هذه المعايير، فاقرأ هذا المقال: معايير الذكاء الاصطناعي.
الخلاصة: قوية ويمكن الوصول إليها
يثبت Gemini 3.1 Pro أنه أكثر من مجرد نموذج متعدد الوسائط مبهرج. ومن خلال المنطق والتعليمات البرمجية والتوليف التحليلي، فإنه يوضح القدرة الحقيقية ذات الصلة بالإنتاج. إنها ليست خالية من العيوب ولا تزال تتطلب تحفيزًا منظمًا وإشرافًا بشريًا. ولكن باعتباره نموذجًا رائدًا مضمنًا في نظام Google البيئي، فهو قوي وتنافسي ويستحق التقييم الجاد تمامًا.
الأسئلة المتداولة
ج: تم تصميمه للاستدلال المتقدم ومعالجة السياق الطويل والفهم متعدد الوسائط وتطبيقات الذكاء الاصطناعي على مستوى الإنتاج.
ج. يمكن للمطورين الوصول إليه عبر Google AI Studio للنماذج الأولية أو Vertex AI لعمليات النشر المؤسسية القابلة للتطوير.
ج: إنه يؤدي أداءً قويًا ولكنه لا يزال يتطلب تحفيزًا منظمًا وإشرافًا بشريًا لضمان الدقة وتقليل الهلوسة.
![]()
أنا متخصص في مراجعة وتحسين الأبحاث المستندة إلى الذكاء الاصطناعي والوثائق الفنية والمحتوى المتعلق بتقنيات الذكاء الاصطناعي الناشئة. تشمل خبرتي التدريب على نماذج الذكاء الاصطناعي، وتحليل البيانات، واسترجاع المعلومات، مما يسمح لي بصياغة محتوى دقيق تقنيًا ويمكن الوصول إليه.
قم بتسجيل الدخول لمواصلة القراءة والاستمتاع بالمحتوى الذي ينظمه الخبراء.
[ad_2]
Source link




