[ad_1]
تعتمد نماذج التعلم العميق على وظائف التنشيط التي توفر عدم الخطية وتمكن الشبكات من تعلم الأنماط المعقدة. ستناقش هذه المقالة وظيفة تنشيط Softplus، وما هي وكيف يمكن استخدامها في PyTorch. يمكن القول أن Softplus هو شكل سلس من تنشيط ReLU الشهير، والذي يخفف من عيوب ReLU ولكنه يقدم عيوبه الخاصة. سنناقش ماهية Softplus، وصيغتها الرياضية، ومقارنتها مع ReLU، وما هي مزاياها وقيودها، وسنقوم بجولة عبر بعض أكواد PyTorch التي تستخدمها.
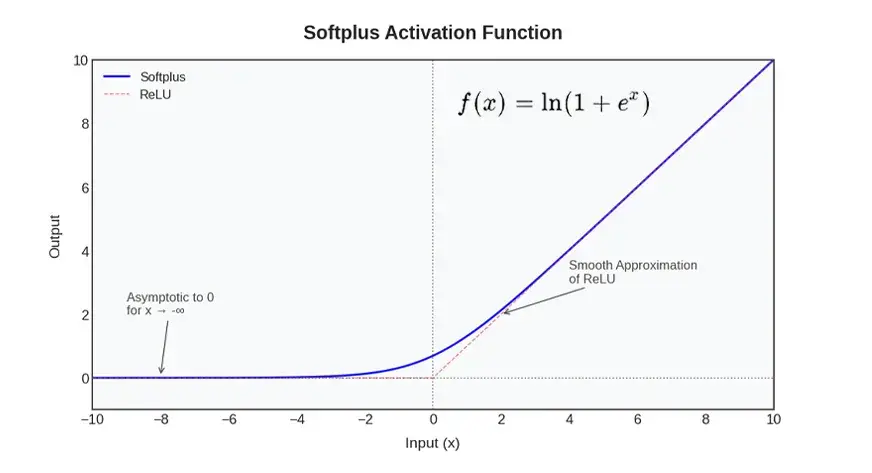
ما هي وظيفة تفعيل Softplus؟
وظيفة تنشيط Softplus هي وظيفة غير خطية للشبكات العصبية وتتميز بالتقريب السلس لوظيفة ReLU. بكلمات أسهل، يعمل Softplus مثل ReLU في الحالات التي يكون فيها الإدخال الإيجابي أو السلبي كبيرًا جدًا، ولكن لا توجد زاوية حادة عند نقطة الصفر. وفي مكانه، يرتفع بسلاسة وينتج ناتجًا إيجابيًا هامشيًا للمدخلات السلبية بدلاً من الصفر الثابت. يشير هذا السلوك المستمر والقابل للتمييز إلى أن Softplus مستمر وقابل للتمييز في كل مكان على عكس ReLU الذي يكون متقطعًا (مع تغيير حاد في الميل) عند x = 0.
لماذا يتم استخدام سوفت بلس؟
يتم اختيار Softplus من قبل المطورين الذين يفضلون التنشيط الأكثر ملاءمة الذي يقدمه. التدرجات غير الصفرية أيضًا حيث يكون ReLU غير نشط. يمكن تجنب التحسين القائم على التدرج من الاضطرابات الكبيرة الناجمة عن سلاسة Softplus (يتحول التدرج بسلاسة بدلاً من التدرج). كما أنه يقوم أيضًا بقص المخرجات بطبيعته (كما يفعل ReLU) ولكن القطع لا يصل إلى الصفر. باختصار، Softplus هو الإصدار الأكثر ليونة من ReLU: إنه يشبه ReLU عندما تكون القيمة كبيرة ولكنها أفضل عند الصفر وتكون لطيفة وسلسة.
صيغة Softplus الرياضية
يتم تعريف Softplus رياضيًا على أنه:
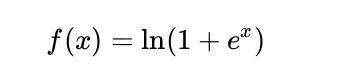
متى س كبير، هس كبيرة جدًا ولذلك قانون الجنسية (1 + لس) مشابه جدًا لـ إلن (هس)، يساوي س. وهذا يعني أن Softplus خطي تقريبًا عند المدخلات الكبيرة، مثل ReLU.
متى س كبيرة وسلبية هس صغير جدًا، وبالتالي قانون الجنسية (1 + لس) هو تقريبا قانون الجنسية(1)، وهذا هو 0. القيم التي تنتجها Softplus قريبة من الصفر ولكنها ليست صفرًا أبدًا. لكي تأخذ قيمة صفر، يجب أن تقترب x من اللانهاية السالبة.
شيء آخر مفيد هو أن مشتق Softplus هو السيني. مشتق من قانون الجنسية (1 + لس) يكون:
هس / (1 + هس)
هذا هو السيني جدا س. وهذا يعني أنه في أي لحظة، يكون منحدر Softplus السيني (x)، أي أن تدرجها غير صفري في كل مكان وهي سلسة. وهذا يجعل Softplus مفيدًا في التعلم القائم على التدرج لأنه لا يحتوي على مناطق مسطحة حيث تختفي التدرجات.
استخدام Softplus في PyTorch
يوفر PyTorch التنشيط Softplus كتنشيط أصلي وبالتالي يمكن استخدامه بسهولة مثل ReLU أو أي تنشيط آخر. ويرد أدناه مثال على اثنين بسيطين. يستخدم الأول Softplus على عدد صغير من قيم الاختبار، ويوضح الأخير كيفية إدراج Softplus في شبكة عصبية صغيرة.
Softplus على مدخلات العينة
ينطبق المقتطف أدناه nn.Softplus إلى موتر صغير حتى تتمكن من رؤية كيف يتصرف مع المدخلات السالبة والصفرية والإيجابية.
import torch
import torch.nn as nn
# Create the Softplus activation
softplus = nn.Softplus() # default beta=1, threshold=20
# Sample inputs
x = torch.tensor((-2.0, -1.0, 0.0, 1.0, 2.0))
y = softplus(x)
print("Input:", x.tolist())
print("Softplus output:", y.tolist())
ماذا يظهر هذا:
- عند x = -2 وx = -1، تكون قيمة Softplus عبارة عن قيم موجبة صغيرة بدلاً من 0.
- يبلغ الناتج حوالي 0.6931 عند x =0، أي قانون الجنسية(2)
- في حالة المدخلات الإيجابية مثل 1 أو 2، تكون النتائج أكبر قليلاً من المدخلات حيث يقوم Softplus بتنعيم المنحنى. يقترب Softplus من x مع زيادة.
يتم تمثيل Softplus of PyTorch بالصيغة قانون الجنسية (1 + إكسب (بيتاكس)). قيمة العتبة الداخلية البالغة 20 هي منع التجاوز الرقمي. Softplus خطي في النسخة الكبيرة، مما يعني أنه في هذه الحالة يعود PyTorch ببساطة س.
استخدام Softplus في الشبكة العصبية
فيما يلي شبكة PyTorch بسيطة تستخدم Softplus كتنشيط لطبقتها المخفية.
import torch
import torch.nn as nn
class SimpleNet(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(SimpleNet, self).__init__()
self.fc1 = nn.Linear(input_size, hidden_size)
self.activation = nn.Softplus()
self.fc2 = nn.Linear(hidden_size, output_size)
def forward(self, x):
x = self.fc1(x)
x = self.activation(x) # apply Softplus
x = self.fc2(x)
return x
# Create the model
model = SimpleNet(input_size=4, hidden_size=3, output_size=1)
print(model)
يعمل تمرير المدخلات عبر النموذج كالمعتاد:
x_input = torch.randn(2, 4) # batch of 2 samples
y_output = model(x_input)
print("Input:\n", x_input)
print("Output:\n", y_output)
في هذا الترتيب، يتم استخدام تنشيط Softplus بحيث تكون القيم الخارجة من الطبقة الأولى إلى الطبقة الثانية غير سالبة. قد لا يحتاج استبدال Softplus بنموذج موجود إلى أي تغيير هيكلي آخر. من المهم فقط أن تتذكر أن Softplus قد يكون أبطأ قليلاً في التدريب ويتطلب عمليات حسابية أكثر من ReLU.
يمكن أيضًا تنفيذ الطبقة النهائية باستخدام Softplus عندما تكون هناك قيم إيجابية يجب أن يولدها النموذج كمخرجات، على سبيل المثال معلمات القياس أو أهداف الانحدار الإيجابية.
Softplus vs ReLU: جدول المقارنة
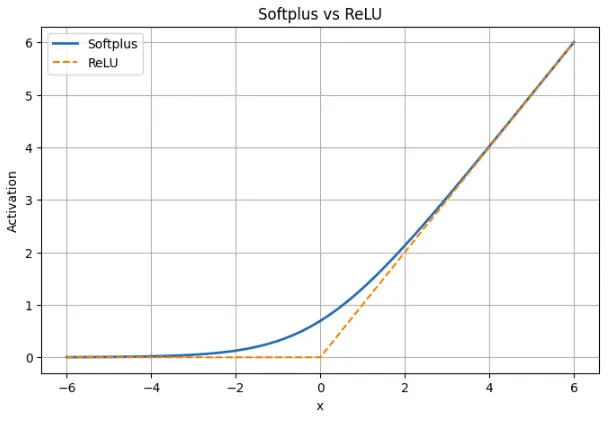
| وجه | سوفت بلس | سيرة ذاتية |
|---|---|---|
| تعريف | و (س) = قانون الجنسية (1 + لس) | و(س) = الحد الأقصى(0، س) |
| شكل | الانتقال السلس عبر جميع x | شبك حاد عند x = 0 |
| السلوك لـ x <0 | إخراج إيجابي صغير. لا يصل أبدا إلى الصفر | الناتج هو بالضبط صفر |
| مثال عند x = -2 | سوفت بلس ≈ 0.13 | ريلو = 0 |
| بالقرب من س = 0 | سلسة وقابلة للتمييز. القيمة ≈ 0.693 | غير قابلة للتمييز عند 0 |
| السلوك لـ x > 0 | خطي تقريبًا، ويطابق ReLU بشكل وثيق | خطي مع المنحدر 1 |
| مثال عند x = 5 | سوفت بلس ≈ 5.0067 | ريلو = 5 |
| التدرج | دائما غير الصفر؛ مشتق هو السيني (x) | صفر لـ x <0، غير محدد عند 0 |
| خطر الخلايا العصبية الميتة | لا أحد | ممكن للمدخلات السلبية |
| متناثرة | لا تنتج أصفارًا دقيقة | ينتج أصفارًا حقيقية |
| تأثير التدريب | تدفق متدرج مستقر، وتحديثات أكثر سلاسة | بسيطة ولكنها يمكن أن تتوقف عن التعلم بالنسبة لبعض الخلايا العصبية |
التناظرية لـ ReLU هي softplus. إنه ReLU بمدخلات إيجابية أو سلبية كبيرة جدًا ولكن مع إزالة الزاوية عند الصفر. وهذا يمنع الخلايا العصبية الميتة لأن التدرج لا يصل إلى الصفر. يأتي هذا على حساب أن Softplus لا تنشئ أصفارًا حقيقية مما يعني أنها ليست متفرقة مثل ReLU. توفر Softplus ديناميكيات تدريب أكثر راحة في الممارسة العملية، لكن ReLU لا يزال يستخدم لأنه أسرع وأبسط.
فوائد استخدام Softplus
يتمتع Softplus ببعض الفوائد العملية التي تجعله مفيدًا في بعض النماذج.
- في كل مكان على نحو سلس ومختلف
لا توجد زوايا حادة في Softplus. إنه قابل للتمييز تمامًا لكل مدخلات. يساعد هذا في الحفاظ على التدرجات التي قد تؤدي في النهاية إلى جعل التحسين أسهل قليلاً نظرًا لأن الخسارة تختلف بشكل أبطأ.
- يتجنب الخلايا العصبية الميتة
يمكن لـ ReLU منع التحديث عندما تتلقى الخلية العصبية مدخلات سلبية بشكل مستمر، حيث سيكون التدرج صفرًا. لا يعطي Softplus قيمة الصفر الدقيقة على الأرقام السالبة وبالتالي تظل جميع الخلايا العصبية نشطة جزئيًا ويتم تحديثها على التدرج.
- يتفاعل بشكل أكثر إيجابية مع المدخلات السلبية
لا يقوم Softplus بطرد المدخلات السالبة عن طريق توليد قيمة صفرية كما يفعل ReLU، بل يقوم بإنشاء قيمة موجبة صغيرة. وهذا يسمح للنموذج بالاحتفاظ بجزء من معلومات الإشارات السلبية بدلاً من فقدانها كلها.
بإيجاز، يحافظ Softplus على تدفق التدرجات، ويمنع الخلايا العصبية الميتة ويوفر سلوكًا سلسًا لاستخدامه في بعض البنى أو المهام التي تكون فيها الاستمرارية مهمة.
القيود والمقايضات الخاصة بـ Softplus
هناك أيضًا عيوب في Softplus تحد من تكرار استخدامه.
- أكثر تكلفة لحساب
يستخدم Softplus العمليات الأسية واللوغاريتمية التي تكون أبطأ من العمليات البسيطة max(0, x) من ريلو. يمكن الشعور بهذا الحمل الإضافي بشكل واضح في الطرز الكبيرة لأن ReLU مُحسّن للغاية على معظم الأجهزة.
- لا يوجد تناثر حقيقي
يُنشئ ReLU أصفارًا مثالية على الأمثلة السالبة، مما يمكن أن يوفر وقت الحوسبة ويساعد أحيانًا في التنظيم. لا يعطي Softplus صفرًا حقيقيًا، وبالتالي فإن جميع الخلايا العصبية ليست دائمًا غير نشطة. وهذا يلغي خطر الخلايا العصبية الميتة بالإضافة إلى مزايا كفاءة التنشيط المتناثر.
- إبطاء تقارب الشبكات العميقة تدريجيًا
يستخدم ReLU بشكل شائع لتدريب النماذج العميقة. لديها قطع حاد ومنطقة إيجابية خطية يمكن أن تجبر على التعلم. يعد Softplus أكثر سلاسة وقد يكون تحديثاته بطيئة خاصة في الشبكات العميقة جدًا حيث يكون الفرق بين الطبقات صغيرًا.
لتلخيص ذلك، يتمتع Softplus بخصائص رياضية جيدة ويتجنب مشاكل مثل الخلايا العصبية الميتة، لكن هذه الفوائد لا تترجم دائمًا إلى نتائج أفضل في الشبكات العميقة. من الأفضل استخدامه في الحالات التي تكون فيها السلاسة أو المخرجات الإيجابية مهمة، وليس كبديل عالمي لـ ReLU.
خاتمة
توفر Softplus بدائل سلسة وناعمة لـ ReLU للشبكات العصبية. فهو يتعلم التدرجات، ولا يقتل الخلايا العصبية، ويمكن تمييزه بالكامل عبر المدخلات. إنه مثل ReLU عند القيم الكبيرة، ولكن عند الصفر، يتصرف كثابت أكثر من ReLU لأنه ينتج مخرجات وانحدارًا غير صفري. وفي الوقت نفسه، فإنه يرتبط بالمقايضات. كما أنه أبطأ في الحساب؛ كما أنها لا تولد أصفارًا حقيقية وقد لا تسرع التعلم في الشبكات العميقة بنفس سرعة ReLU. يعتبر Softplus أكثر فعالية في النماذج، حيث تكون التدرجات سلسة أو حيث تكون المخرجات الإيجابية إلزامية. في معظم السيناريوهات الأخرى، يعد هذا بديلاً مفيدًا لاستبدال ReLU الافتراضي.
الأسئلة المتداولة
A. يمنع Softplus الخلايا العصبية الميتة عن طريق الحفاظ على التدرجات غير الصفرية لجميع المدخلات، مما يوفر بديلاً سلسًا لـ ReLU مع الاستمرار في التصرف بشكل مشابه للقيم الإيجابية الكبيرة.
ج: يعد هذا اختيارًا جيدًا عندما يستفيد نموذجك من التدرجات اللونية المتجانسة أو يجب أن يقوم بإخراج قيم إيجابية تمامًا، مثل معلمات المقياس أو أهداف انحدار معينة.
ج: إنه أبطأ في الحساب من ReLU، ولا ينشئ عمليات تنشيط متفرقة، ويمكن أن يؤدي إلى تقارب أبطأ قليلاً في الشبكات العميقة.
![]()
مرحبًا، أنا جانفي، متحمس لعلوم البيانات وأعمل حاليًا في Analytics Vidhya. بدأت رحلتي إلى عالم البيانات بفضول عميق حول كيفية استخلاص رؤى ذات معنى من مجموعات البيانات المعقدة.
قم بتسجيل الدخول لمواصلة القراءة والاستمتاع بالمحتوى الذي ينظمه الخبراء.
[ad_2]
Source link




