[ad_1]
إذا كنت تشاهد مساحة LLM مفتوحة المصدر، فأنت تعلم بالفعل أنها تحولت إلى سباق كامل. كل بضعة أشهر، يظهر نموذج جديد يدعي أنه يتجاوز الحدود، والبعض يفعل ذلك بالفعل. وكانت المختبرات الصينية على وجه الخصوص تتحرك بسرعة، مع نماذج مثل GLM 4.6، وKimi K2 Thinking، وQwen 3 Next، وERNIE-4.5-VL والمزيد. لذلك عندما أسقط DeepSeek الإصدار 3.2، لم يكن السؤال الواضح هو “هل هذا هو الملك الجديد؟” السؤال الحقيقي كان:
هل يدفع هذا التحديث بالفعل عالم المصادر المفتوحة إلى الأمام، أم أنه مجرد نموذج آخر في هذا المزيج؟
للإجابة على ذلك، دعونا نستعرض القصة وراء الإصدار 3.2، وما الذي تغير، ولماذا يهتم الناس به.
ما هو ديب سيك V3.2؟
DeepSeek V3.2 هو نسخة مطورة من DeepSeek-V3.2-Exp الذي تم إصداره في أكتوبر. لقد تم تصميمه لدفع الاستدلال وفهم السياق الطويل وسير عمل الوكيل إلى أبعد من الإصدارات السابقة. على عكس العديد من النماذج المفتوحة التي تقوم ببساطة بقياس المعلمات، يقدم الإصدار 3.2 تغييرات معمارية ومرحلة تعلم معززة أثقل بكثير لتحسين كيفية تفكير النموذج، وليس فقط ما يخرجه.
أصدر DeepSeek أيضًا نوعين مختلفين:
- الإصدار 3.2 (قياسي): الإصدار العملي وسهل النشر والمناسب للدردشة والبرمجة والأدوات وأحمال العمل اليومية.
- V3.2 خاص: إصدار عالي الحوسبة ومزود بالاستدلال وينتج سلاسل فكرية أطول ويتفوق في الرياضيات على مستوى الأولمبياد والبرمجة التنافسية.
الأداء والمعايير لبرنامج DeepSeek V3.2
يأتي DeepSeek V3.2 مزودًا ببعض أقوى النتائج المعيارية التي رأيناها من الوضع مفتوح المصدر.
- في اختبارات الرياضيات الثقيلة مثل AIME 2025 وHMMT 2025، حصل الإصدار Speciale على درجات 96% و99.2%، وهو ما يطابق أو يتفوق على نماذج مثل GPT-5 High وClaude 4.5.
- تصنيف Codeforces الخاص بها والذي يبلغ 2701 يضعها بقوة في منطقة البرمجة التنافسية، في حين أن متغير التفكير لا يزال يقدم 2386 قويًا.
- في مهام الوكلاء، تحتفظ DeepSeek بنسبة 73% في SWE Verified و80% في τ² Bench، حتى لو كانت أفضل النماذج المغلقة تتقدم في بعض الفئات.
الفكرة الكبرى: “القشط” الأكثر ذكاءً
تعاني معظم نماذج الذكاء الاصطناعي القوية من مشكلة شائعة: عندما يصبح المستند أطول، يصبح تشغيل النموذج أبطأ بكثير وأكثر تكلفة. وذلك لأن النماذج التقليدية تحاول مقارنة كل كلمة بكل كلمة أخرى لفهم السياق.
يحل DeepSeek-V3.2 هذه المشكلة عن طريق تقديم طريقة جديدة تسمى DeepSeek Sparse Attention (DSA). فكر في الأمر كباحث في مكتبة:
- الطريقة القديمة (الانتباه الشديد): يقرأ الباحث كل كتاب على الرف، صفحة بعد صفحة، فقط للإجابة على سؤال واحد. إنها شاملة ولكنها بطيئة ومرهقة بشكل لا يصدق.
- طريقة جديدة (DeepSeek-V3.2): يستخدم الباحث كتالوجًا رقميًا (The Lightning Indexer) للعثور على الصفحات الدقيقة التي تهمك على الفور، و فقط يقرأ تلك الصفحات. إنها دقيقة تمامًا، ولكنها أسرع بكثير.
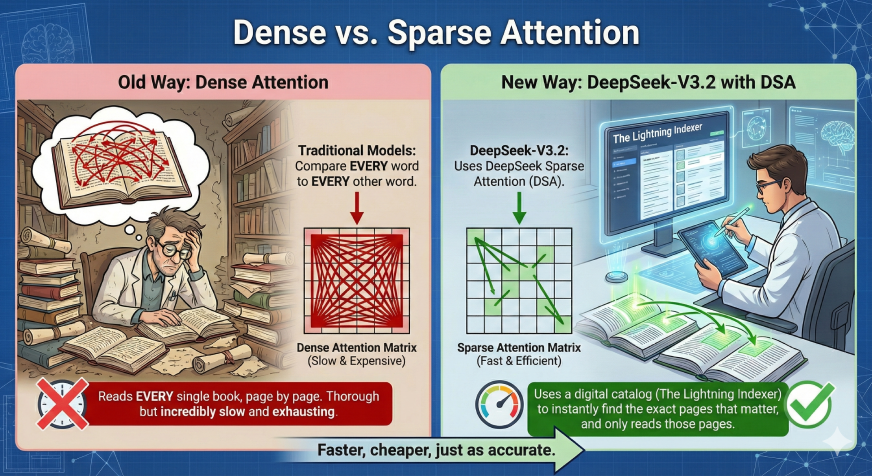
بنية DeepSeek V3.2
الابتكار الأساسي هو DSA (DeepSeek Sparse Attention)، والذي يتكون من خطوتين رئيسيتين:
1. مُفهرس البرق (الكشاف)
قبل أن يحاول الذكاء الاصطناعي فهم النص، تقوم أداة خفيفة الوزن وفائقة السرعة تسمى “Lightning Indexer” بمسح المحتوى. فهو يمنح كل معلومة “درجة الأهمية”. ويسأل: “هل هذه المعلومة مفيدة لما نقوم به الآن؟”
2. محدد Top-k (الفلتر)
بدلاً من تغذية كل شيء في دماغ الذكاء الاصطناعي، يختار النظام فقط أجزاء المعلومات “Top-k” (أعلى الدرجات). يتجاهل الذكاء الاصطناعي الزغب غير ذي الصلة ويركز قوته الحاسوبية بشكل صارم على البيانات المهمة.
هل يعمل فعلا؟
قد تقلق من أن “القشط” يجعل الذكاء الاصطناعي غير دقيق. ووفقا للبيانات، فإنه لا.
- نفس الذكاء: يعمل DeepSeek-V3.2 تمامًا مثل سابقه (DeepSeek-V3.1-Terminus) في الاختبارات القياسية ومخططات التفضيلات البشرية (ChatbotArena).
- أفضل في المهام الطويلة: والمثير للدهشة أنه حصل بالفعل على درجات أعلى في بعض المهام الاستدلالية التي تتضمن مستندات طويلة جدًا.
- تمرين: لقد تم تعليمه القيام بذلك من خلال مشاهدة عمل النموذج الأقدم والأبطأ أولاً (الإحماء الكثيف) ثم التدرب بمفرده لاختيار المعلومات الصحيحة (التدريب المتناثر).
ماذا يعني هذا بالنسبة للمستخدمين؟
فيما يلي عرض القيمة “ما الذي يمكن أن يفعله للآخرين”:
- تعزيز السرعة الهائل: نظرًا لأن النموذج لا يعيق نفسه في معالجة الكلمات غير ذات الصلة، فإنه يعمل بشكل أسرع بشكل ملحوظ، خاصة عند التعامل مع المستندات الطويلة (مثل العقود القانونية أو الكتب).
- تكلفة أقل: يتطلب طاقة حاسوبية أقل (ساعات وحدة معالجة الرسومات) للحصول على نفس النتيجة. وهذا يجعل تشغيل الذكاء الاصطناعي المتطور أكثر سهولة.
- إتقان السياق الطويل: يمكن للمستخدمين تغذيته بكميات هائلة من البيانات (ما يصل إلى 128000 رمزًا مميزًا) دون أن يتباطأ النظام إلى حد الزحف أو التعطل، مما يجعله مثاليًا لتحليل مجموعات البيانات الكبيرة أو القصص الطويلة.
يحتفظ DeepSeek الآن بسياق التفكير الداخلي الخاص به أثناء استخدام الأدوات بدلاً من إعادة تشغيل عملية التفكير بعد كل خطوة، مما يجعل إكمال المهام المعقدة أسرع وأكثر كفاءة بشكل ملحوظ.
- في السابق، في كل مرة يستخدم فيها الذكاء الاصطناعي أداة (مثل تشغيل التعليمات البرمجية)، كان ينسى خطته ويضطر إلى “إعادة التفكير” في المشكلة من الصفر. كان هذا بطيئًا ومهدرًا.
- الآن، يحافظ الذكاء الاصطناعي على عملية التفكير نشطة أثناء استخدام الأدوات. فهو يتذكر سبب قيامه بالمهمة وليس من الضروري البدء من جديد بعد كل خطوة.
- فهو يقوم فقط بمسح “أفكاره” عند إرسال رسالة جديدة. وحتى ذلك الحين، سيظل يركز على الوظيفة الحالية.
نتيجة: النموذج أسرع وأرخص لأنه لا يهدر الطاقة في التفكير في نفس الشيء مرتين.
ملحوظة: يعمل هذا بشكل أفضل عندما يفصل النظام “مخرجات الأداة” عن “رسائل المستخدم”. إذا كان برنامجك يتعامل مع نتائج الأداة على أنها دردشة مستخدم، فلن تعمل هذه الميزة.
يمكنك قراءة المزيد عن DeepSeek V3.2 هنا. دعونا نرى كيفية أداء النموذج في القسم الوارد أدناه:
المهمة 1: إنشاء لعبة
قم بإنشاء واجهة مستخدم لطيفة وتفاعلية للعبة “Guess the Word” حيث يعرف اللاعب كلمة سرية ويقدم 3 أدلة قصيرة (بحد أقصى 10 أحرف لكل منها). يقوم الذكاء الاصطناعي بعد ذلك بثلاث محاولات لتخمين الكلمة. إذا خمن الذكاء الاصطناعي بشكل صحيح، فإنه يفوز؛ وإلا يفوز اللاعب.
رأيي:
أنشأ DeepSeek لعبة بديهية تحتوي على جميع الميزات المطلوبة. لقد وجدت أن هذا التنفيذ ممتاز، حيث يقدم تجربة مصقولة وجذابة تلبي جميع المتطلبات بشكل مثالي.
المهمة 2: التخطيط
أحتاج إلى التخطيط لرحلة مدتها 7 أيام إلى كيوتو باليابان في منتصف نوفمبر. يجب أن يركز خط سير الرحلة على الثقافة التقليدية، بما في ذلك المعابد والحدائق واحتفالات الشاي. ابحث عن أفضل وقت لرؤية أوراق الخريف، وقائمة من ثلاثة معابد يجب زيارتها لـ “موميجي” (أوراق الخريف)، وبيت شاي تقليدي عالي التصنيف يقدم خدمات صديقة للغة الإنجليزية. يمكنك أيضًا العثور على ريوكان (نزل ياباني تقليدي) تمت مراجعته جيدًا في منطقة جيون. تنظيم كافة المعلومات في خط سير واضح، يوما بعد يوم.
الإخراج:

العثور على الإخراج الكامل هنا .
رأيي:
تعد استجابة V3.2 ممتازة للمسافر الذي يريد خطة واضحة وقابلة للتنفيذ وذات وتيرة جيدة. إن تنسيقه وتدفقه الجغرافي المنطقي ونصائحه العملية المتكاملة تجعله جاهزًا للاستخدام بشكل مباشر تقريبًا. إنه يوضح التوليف القوي للمعلومات في سرد مقنع.
اقرأ أيضًا: دليل DeepSeek Math V2: الذكاء الاصطناعي الأكثر ذكاءً للرياضيات الحقيقية
خاتمة
لا يحاول DeepSeek V3.2 الفوز بالحجم، بل يفوز بالتفكير بشكل أكثر ذكاءً. بفضل الاهتمام المتناثر، والتكاليف المنخفضة، وقوة السياق الطويل، والتفكير الأفضل لاستخدام الأدوات، فإنه يوضح كيف يمكن للنماذج مفتوحة المصدر أن تظل قادرة على المنافسة دون ميزانيات ضخمة للأجهزة. قد لا يهيمن على كل المعايير، لكنه يحسن بشكل كبير كيف يمكن للمستخدمين الحقيقيين العمل مع الذكاء الاصطناعي اليوم. وهذا ما يجعلها تبرز في مجال مزدحم.
![]()
مرحبًا، أنا Nitika، منشئ محتوى ومسوق ماهر في مجال التكنولوجيا. الإبداع وتعلم أشياء جديدة أمر طبيعي بالنسبة لي. لدي خبرة في إنشاء استراتيجيات المحتوى المبنية على النتائج. أنا على دراية جيدة بإدارة تحسين محركات البحث وعمليات الكلمات الرئيسية وكتابة محتوى الويب والتواصل واستراتيجية المحتوى والتحرير والكتابة.
قم بتسجيل الدخول لمواصلة القراءة والاستمتاع بالمحتوى الذي ينظمه الخبراء.
[ad_2]
Source link