
8 أشياء يجب القيام بها مع مكتبة MarkItDown من Microsoft

تبدأ معظم مشاريع الذكاء الاصطناعي بعمل روتيني مزعج: تنظيف الملفات الفوضوية. يجب تحويل ملفات PDF ومستندات Word وPPT والصور والصوت وجداول البيانات إلى نص نظيف قبل أن تصبح مفيدة. أخيرًا، قام برنامج MarkItDown من Microsoft بإصلاح هذه المشكلة. في هذا الدليل، سأوضح لك كيفية تثبيته، وتحويل كل أنواع الملفات الرئيسية إلى Markdown، وتشغيل OCR على الصور، ونسخ الصوت، واستخراج المحتوى من ملفات ZIP، وإنشاء خطوط أنابيب أكثر نظافة لسير عمل LLM الخاص بك باستخدام بضعة أسطر فقط من التعليمات البرمجية.
لماذا يعتبر MarkItDown مهمًا؟
قبل أن ننتقل إلى الأمثلة العملية، من المفيد أن نفهم كيف يقوم MarkItDown بتحويل الملفات المختلفة إلى Markdown نظيف. لا تتعامل المكتبة مع كل التنسيقات بنفس الطريقة. وبدلاً من ذلك، فإنه يستخدم عملية ذكية من خطوتين.
أولاً، يتم تحليل كل نوع ملف باستخدام الأداة المناسبة له. تمر مستندات Word عبر الماموث، وأوراق Excel عبر الباندا، وشرائح PowerPoint عبر python-pptx. يتم تحويل كل منهم إلى HTML منظم.
ثانيًا، يتم تنظيف HTML وتحويله إلى Markdown باستخدام BeautifulSoup. وهذا يضمن أن الإخراج النهائي يحافظ على العناوين والقوائم والجداول والبنية المنطقية سليمة.
يمكنك إضافة الصورة هنا لجعل التدفق واضحًا:
يتبع MarkItDown هذا المسار في كل مرة تقوم فيها بإجراء تحويل، بغض النظر عن مدى فوضى المستند الأصلي.
اقرأ المزيد عنها في مقالتنا السابقة حول كيفية استخدام MarkItDown MCP لتحويل المستندات إلى عمليات تخفيض السعر؟
تثبيت وإعداد MarkItDown من Microsoft
يلزم وجود بيئة Python والنقطة للبدء. ستحتاج أيضًا إلى مفتاح AI API مفتوح في حال كنت تنوي معالجة الصور أو الصوت.
في أي محطة، سيقوم الأمر التالي بتثبيت مكتبة MarkItDown Python:
!pip install markitdown(all) من الأفضل إنشاء بيئة افتراضية لمنع التعارض مع المشاريع الأخرى.
# Create a virtual environment
python -m venv venv
# Activate it (Windows)
venv\Scripts\activate
# Activate it (Mac/Linux)
source venv/bin/activate بعد التثبيت، قم باستيراد المكتبة في بايثون لاختبارها. أنت الآن جاهز لتحويل الملفات إلى Markdown
8 أشياء يجب القيام بها مع مكتبة MarkItDown من Microsoft
يدعم MarkItDown معظم التنسيقات. هذه هي الأمثلة على استخدام استخدامه في الملفات الشائعة.
المهمة 1: تحويل مستندات MS Word
تتضمن مستندات Word عادةً الرؤوس والنص الغامق والقوائم. يحتفظ MarkItDown بهذا التنسيق أثناء التحويل.
from markitdown import MarkItDown
md = MarkItDown()
res = md.convert("/content/test-sample.docx")
print(res.text_content) الإخراج:
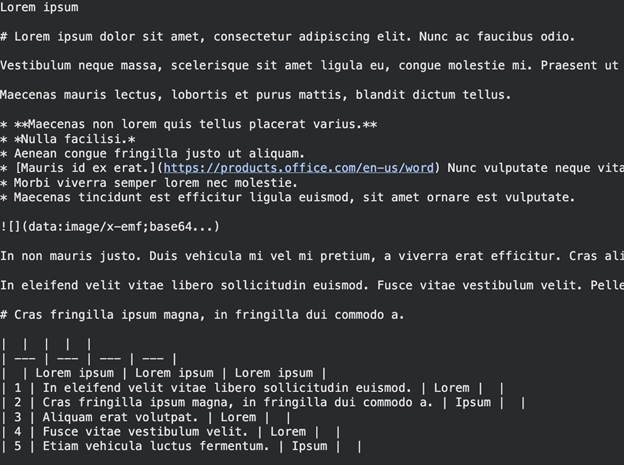
سوف تجد نص تخفيض السعر. يتم تحديد العناوين بواسطة الحروف # والقوائم بواسطة *. يساعد هذا النوع من البنية حاملي الماجستير في القانون على فهم بنية ورقتك.
بيانات Excel مطلوبة بانتظام من قبل محللي البيانات. إنها أداة لتحويل المستندات يمكنها تحويل جداول البيانات إلى جداول Markdown نظيفة.
from markitdown import MarkItDown
md = MarkItDown()
result = md.convert("/content/file_example_XLS_10.xls")
print(result.text_content) الإخراج:
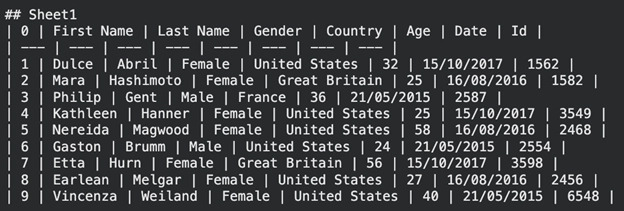
يتم تقديم المعلومات في شكل جدول Markdown. ليس من الصعب تفسير هذا التنسيق من قبل البشر ونماذج الذكاء الاصطناعي.
المهمة 3: تحويل شرائح PowerPoint إلى Clean Markdown
تحتوي مجموعات الشرائح على ملخصات مفيدة. يمكن استخراج هذا النص لإنشاء بيانات لاستخدامها في مهام تلخيص LLM.
from markitdown import MarkItDown
md = MarkItDown()
result = md.convert("/content/file-sample.pptx")
print(result.text_content) الإخراج:
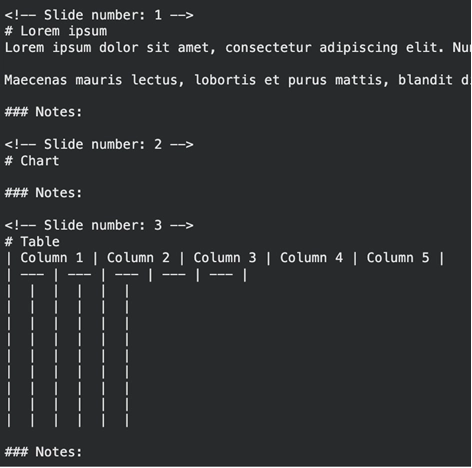
تلتقط الأداة النقاط التعدادية وعناوين الشرائح، مفصولة برقم الشريحة. فهو يتجاهل ميزات التخطيط المعقدة التي تتسبب في ضياع محللي النص.
المهمة 4: تحليل ملفات PDF إلى تخفيض منظم
من الصعب جدًا فك تشفير ملف PDF. MarkItDown يجعل هذه العملية أسهل.
from markitdown import MarkItDown
md = MarkItDown()
result = md.convert("/content/1706.03762.pdf")
print(result.text_content) الإخراج:
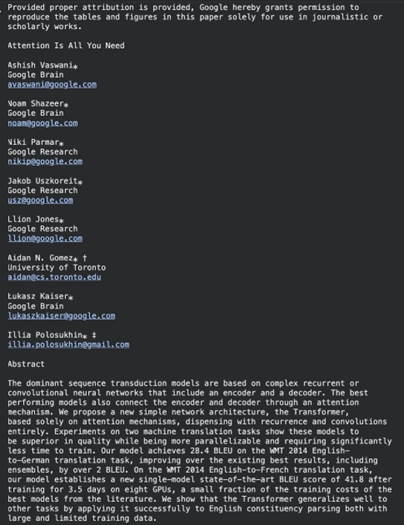
يقوم باستخراج النص بالتنسيق حسب القسم. يمكن أيضًا دمج المكتبة مع أدوات التعرف الضوئي على الحروف عند استخدام ملفات PDF المعقدة للمستندات الممسوحة ضوئيًا.
المهمة 5: إنشاء نص من الصور باستخدام التعرف الضوئي على الحروف
تستطيع مكتبة MarkItDown Python وصف الصور في حالة ربطها بـ LLM متعدد الوسائط. يتضمن هذا ترتيبًا مع عميل شركة ذات مسؤولية محدودة.
from markitdown import MarkItDown
from openai import OpenAI
from google.colab import userdata
client = OpenAI(api_key=userdata.get('OPENAI_KEY'))
md = MarkItDown(llm_client=client, llm_model="gpt-4o-mini")
result = md.convert("/content/Screenshot 2025-12-03 at 5.46.29 PM.png")
print(result.text_content) الإخراج:

سينتج النموذج تعليقًا وصفيًا أو نصًا مرئيًا في الصورة.
المهمة 6: نسخ الملفات الصوتية إلى تخفيض السعر
يمكنك حتى تحويل الملفات الصوتية إلى نص. لديها هذه الميزة عن طريق نسخ الكلام.
from markitdown import MarkItDown
from openai import OpenAI
md = MarkItDown(llm_client=client, llm_model="gpt-4o-mini")
result = md.convert("/content/speech.mp3")
print(result.text_content) الإخراج:

نسخة نصية من الملف الصوتي بتنسيق Markdown.
المهمة 7: معالجة ملفات متعددة داخل أرشيفات ZIP
يمكن لـ MarkItDown التعامل مع الأرشيفات بأكملها في وقت واحد، إذا كان لديك ملف ZIP من المستندات.
from markitdown import MarkItDown
md = MarkItDown()
result = md.convert("/content/test-sample.zip")
print(result.text_content) الإخراج:
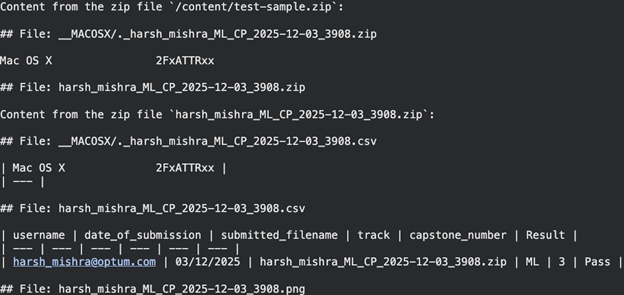
يقوم التطبيق بتوحيد محتويات جميع الملفات المدعومة داخل ملف ZIP في مخرجات Markdown واحدة. كما أنه يستخرج محتوى ملف CSV ويحوله إلى Markdown.
المهمة 8: التعامل مع تنسيقات HTML والنصية
من السهل تحويل صفحات الويب وملفات البيانات مثل ملفات CSV إلى Markdown.
from markitdown import MarkItDown
md = MarkItDown()
result = md.convert("/content/sample1.html")
print(result.text_content) الإخراج:
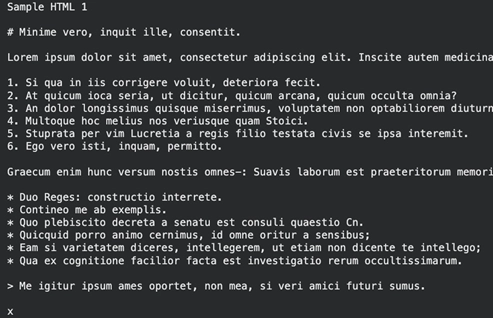
معالجة ملفات متعددة داخل أرشيفات ZIP
Clean Markdown الذي يحافظ على الروابط والرؤوس من HTML.
نصائح متقدمة واستكشاف الأخطاء وإصلاحها
ضع النصائح التالية في الاعتبار للحصول على أفضل النتائج من أداة تحويل المستندات هذه:
حدد 77 كلمة أخرى لتشغيل Humanizer.
- تحسين الإخراج: يمكن استخدام العلامة -o في سطر الأوامر للحفظ في ملف.
- الملفات الكبيرة: قد تستغرق معالجة الملفات الكبيرة وقتًا طويلاً. تأكد من توفير سعة ذاكرة كافية في جهازك.
- أخطاء واجهة برمجة التطبيقات: مشكلة مفتاح واجهة برمجة التطبيقات والإنترنت: في حالة حدوث مشكلات في تحويل الصورة/الصوت، تحقق من مفتاح واجهة برمجة التطبيقات والاتصال بالإنترنت.
- التنسيقات المدعومة: اكتشاف الفشل: راجع صفحة مشكلات GitHub. المجتمع منخرط وداعم.
المضي قدمًا إلى أبعد من ذلك: بناء خط أنابيب للذكاء الاصطناعي
يعمل MarkItDown كأساس قوي لسير عمل الذكاء الاصطناعي. يمكنك دمجها مع أدوات مثل LangChain لإنشاء تطبيقات ذكاء اصطناعي قوية. البيانات عالية الجودة مهمة عند تدريب LLMs. تساعدك أدوات Microsoft مفتوحة المصدر في الحفاظ على بيانات الإدخال النظيفة، مما يؤدي إلى استجابات ذكاء اصطناعي أكثر دقة وموثوقية.
خاتمة
تعد مكتبة MarkItDown Python بمثابة طفرة في إعداد البيانات. يمكّنك من تحويل الملفات إلى Markdown بأقل قدر من الجهد. يقوم بمعالجة النصوص البسيطة إلى الوسائط المتعددة. تعمل أدوات Microsoft مفتوحة المصدر أيضًا على تحسين تجربة المطور. هذه أداة لتحويل المستندات ويجب أن تكون ضمن مجموعة الأدوات الخاصة بك في حالة تعاملك مع حاملي شهادات LLM. جرب الأمثلة أعلاه. انضم إلى المجتمع على جيثب. بيانات جاهزة بشكل طبيعي لسير عمل LLM في أقصر وقت ممكن.
الأسئلة المتداولة
أ. نعم. تحتفظ Microsoft بها كمكتبة مفتوحة المصدر، ويمكنك تثبيتها مجانًا باستخدام النقطة.
ج: إنه يدعم ملفات PDF النصية بشكل أفضل ولكنه قادر على العمل مع الصور الممسوحة ضوئيًا بشرط أن تقوم بإعداده مع عميل LLM للقيام بالتعرف الضوئي على الحروف.
ج: لا، يتطلب MarkItDown مفتاح واجهة برمجة التطبيقات (API) فقط لتحويلات الصور والصوت. يقوم بتحويل الملفات النصية محليًا دون أي مفتاح API.
ج: تثبيت المكتبة أيضًا يعني وجود أداة سطر أوامر متاحة لإدراج تحويلات سريعة للملفات.
ج: يمكنه دعم عناوين URL لملفات PDF وDocx وPPTX وXLSX والصور والصوت وHTML وCSV وJSON وZIP وYouTube.
![]()
هارش ميشرا هو مهندس الذكاء الاصطناعي والتعلم الآلي الذي يقضي وقتًا أطول في التحدث إلى نماذج اللغات الكبيرة مقارنة بالبشر الفعليين. شغوف بـ GenAI وNLP وجعل الآلات أكثر ذكاءً (لذلك لا يحل محله بعد). عندما لا يقوم بتحسين النماذج، فمن المحتمل أنه يقوم بتحسين تناول القهوة. 🚀☕
قم بتسجيل الدخول لمواصلة القراءة والاستمتاع بالمحتوى الذي ينظمه الخبراء.
Source link



