10 معايير للذكاء الاصطناعي يجب أن يعرفها كل مطور في عام 2026

مع مرور الأيام، هناك معايير أكثر من أي وقت مضى. ومن الصعب تتبع كل هيلاسواج أو DS-1000 الذي يخرج. أيضا، لماذا هم حتى؟ مجموعة من الأسماء ذات المظهر الرائع تم وضعها فوق معيار لجعلها تبدو أكثر روعة… ليس حقًا.
بخلاف التسمية المبهجة التي تم تقديمها لهذه المعايير، فإنها تخدم غرضًا عمليًا ودقيقًا للغاية. يقوم كل منهم باختبار النموذج عبر مجموعة من الاختبارات، لمعرفة مدى جودة أداء النموذج وفقًا للمعايير المثالية. عادة ما تكون هذه المعايير هي مدى نجاحها مقارنة بالإنسان العادي.
ستساعدك هذه المقالة في معرفة ما هي هذه المعايير، وأي منها يستخدم لاختبار أي نوع من النماذج، ومتى؟
المخابرات العامة: هل تستطيع فعلاً أن تفكر؟
تختبر هذه المعايير مدى نجاح نماذج الذكاء الاصطناعي في محاكاة قدرة البشر على التفكير.
1. MMLU – فهم لغة المهام المتعددة
MMLU هو “اختبار الذكاء العام” الأساسي لنماذج اللغة. يحتوي على آلاف الأسئلة متعددة الاختيارات في 60 موضوعًا، مع أربعة خيارات لكل سؤال، تغطي مجالات مثل الطب والقانون والرياضيات وعلوم الكمبيوتر.
إنها ليست مثالية، ولكنها عالمية. إذا تخطى النموذج MMLU، يسأل الناس على الفور لماذا ؟ هذا وحده يخبرك بمدى أهمية ذلك.
تستخدم في: نماذج اللغات ذات الأغراض العامة (GPT، كلود، جيميني، لاما، ميسترال)
ورق: https://arxiv.org/abs/2009.03300
2. HLE – الاختبار الأخير للإنسانية
HLE موجود للإجابة على سؤال بسيط: هل تستطيع النماذج التعامل مع الاستدلال على مستوى الخبراء دون الاعتماد على الحفظ؟
يجمع المعيار بين الأسئلة الصعبة للغاية في الرياضيات والعلوم الطبيعية والعلوم الإنسانية. تتم تصفية هذه الأسئلة عمدًا لتجنب الحقائق القابلة للبحث على الويب وتسرب التدريب الشائع.
قد يكون تكوين سؤال المعيار مشابهًا لـ MMLU، ولكن على عكس MMLU HLE تم تصميمه لاختبار LLMs إلى أقصى درجة، وهو ما تم توضيحه في مقياس الأداء هذا:
عندما بدأت النماذج الحدودية في تشبع المعايير القديمة، سرعان ما أصبحت HLE هي النقطة المرجعية الجديدة لـ دفع الحدود!
تستخدم في: نماذج الاستدلال الحدودي وماجستير القانون في مجال البحث (GPT-4، Claude Opus 4.5، Gemini Ultra)
ورق: https://arxiv.org/abs/2501.14249
الاستدلال الرياضي: هل يمكنه الاستدلال من الناحية الإجرائية؟
المنطق هو ما يجعل البشر مميزين، أي أن الذاكرة والتعلم يتم استخدامهما للاستدلال. تختبر هذه المعايير مدى النجاح عندما يتم تنفيذ أعمال الاستدلال بواسطة LLMs.
3. GSM8K — الرياضيات المدرسية (8000 مسألة)
يختبر GSM8K ما إذا كان النموذج يمكنه حل المسائل الكلامية خطوة بخطوة، وليس فقط إخراج الإجابات. فكر في سلسلة الأفكار، ولكن بدلاً من التقييم بناءً على النتيجة النهائية، يتم فحص السلسلة بأكملها.
انها بسيطة! ولكنها فعالة للغاية، ومن الصعب تزييفها. ولهذا السبب يظهر في كل تقييم يركز على الاستدلال تقريبًا.
تستخدم في: نماذج اللغة التي تركز على الاستدلال ونماذج سلسلة الأفكار (GPT-5، PaLM، LLaMA)
ورق: https://arxiv.org/abs/2110.14168
4. MATH – مجموعة بيانات الرياضيات لحل المشكلات المتقدمة
هذا المعيار يرفع السقف. تأتي المشكلات من الرياضيات بأسلوب المنافسة وتتطلب التجريد والتلاعب الرمزي وسلاسل التفكير الطويلة.
تساعد الصعوبة المتأصلة في المشكلات الرياضية في اختبار قدرات النموذج. يتم عرض النماذج التي تحقق نتائج جيدة على GSM8K ولكنها تنهار على MATH على الفور.
تستخدم في: التفكير المتقدم والماجستير في الرياضيات (Minerva، GPT-4، DeepSeek-Math)
ورق: https://arxiv.org/abs/2103.03874
هندسة البرمجيات: هل يمكن أن تحل محل المبرمجين البشريين؟
أنا فقط أمزح. تختبر هذه المعايير مدى جودة LLM في إنشاء تعليمات برمجية خالية من الأخطاء.
5. HumanEval – معيار التقييم البشري لإنشاء الأكواد البرمجية
HumanEval هو معيار الترميز الأكثر استشهادًا به في الوجود. يقوم بتصنيف النماذج بناءً على مدى جودة كتابتها لوظائف Python التي تجتاز اختبارات الوحدة المخفية. لا يوجد تسجيل شخصي. إما أن يعمل الكود أو لا يعمل.
إذا رأيت درجة الترميز في بطاقة نموذجية، فهذا دائمًا ما يكون واحدًا منها.
تستخدم في: نماذج توليد التعليمات البرمجية (OpenAI Codex، CodeLLaMA، DeepSeek-Coder)
ورق: https://arxiv.org/abs/2107.03374
6. SWE-Bench – معيار هندسة البرمجيات
تختبر SWE-Bench هندسة العالم الحقيقي، وليس مشاكل الألعاب.
يتم إعطاء النماذج مشكلات فعلية في GitHub ويجب إنشاء تصحيحات تعمل على إصلاحها داخل المستودعات الحقيقية. هذا المعيار مهم لأنه يعكس كيف يريد الناس بالفعل استخدام نماذج البرمجة.
تستخدم في: هندسة البرمجيات ونماذج الترميز الوكيل (Devin، SWE-Agent، AutoGPT)
ورق: https://arxiv.org/abs/2310.06770
القدرة على المحادثة: هل يمكنها التصرف بطريقة إنسانية؟
تختبر هذه المعايير ما إذا كانت النماذج قادرة على العمل عبر دورات متعددة، ومدى نجاحها مقارنة بالإنسان.
7. MT-Bench – معيار متعدد المنعطفات
يقوم MT-Bench بتقييم كيفية تصرف النماذج عبر دورات محادثة متعددة. فهو يختبر التماسك، والاحتفاظ بالتعليمات، واتساق الاستدلال، والإسهاب.
يتم إنتاج النتائج باستخدام LLM-as-a-قاضي، مما جعل MT-Bench قابلاً للتطوير بدرجة كافية ليصبح معيارًا افتراضيًا للدردشة.
تستخدم في: نماذج المحادثة الموجهة نحو الدردشة (ChatGPT، Claude، Gemini)
ورق: https://arxiv.org/abs/2306.05685
8. Chatbot Arena – معيار التفضيل البشري
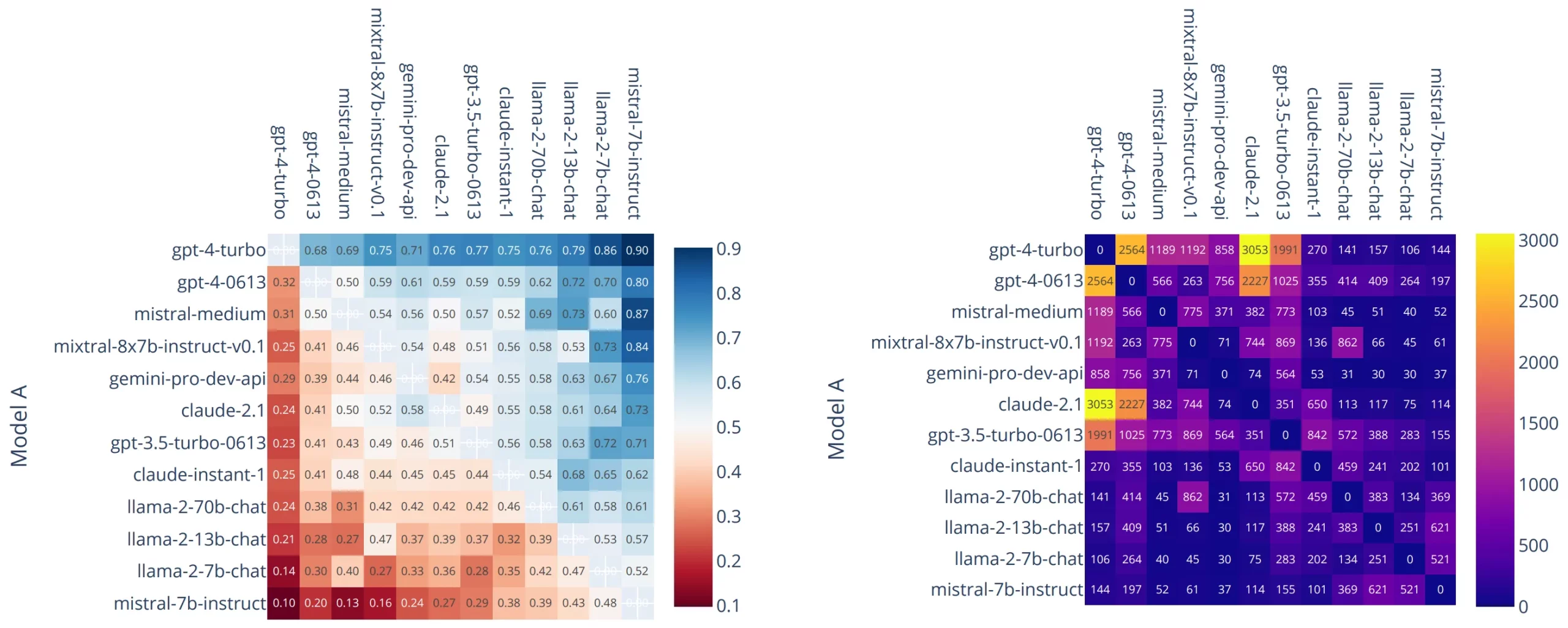
تتجنب Chatbot Arena المقاييس وتسمح للبشر باتخاذ القرار.
تتم مقارنة النماذج وجهاً لوجه في معارك مجهولة، ويصوت المستخدمون على الرد الذي يفضلونه. يتم الحفاظ على التصنيف باستخدام نتائج Elo.
على الرغم من الضجيج، فإن هذا المعيار يحمل أهمية كبيرة لأنه يعكس تفضيل المستخدم الحقيقي على نطاق واسع.
تستخدم في: جميع نماذج الدردشة الرئيسية لتقييم التفضيلات البشرية (ChatGPT، Claude، Gemini، Grok)
ورق: https://arxiv.org/abs/2403.04132
استرجاع المعلومات: هل يمكنه كتابة مدونة؟
أو بشكل أكثر تحديدا: هل يمكن العثور على المعلومات الصحيحة عندما يكون ذلك مهمًا؟
9. BEIR – استرجاع المعلومات المعيارية
BEIR هو المعيار القياسي لتقييم نماذج الاسترجاع والتضمين.
فهو يجمع مجموعات بيانات متعددة عبر مجالات مثل ضمان الجودة والتحقق من الحقائق والاسترجاع العلمي، مما يجعله المرجع الافتراضي لخطوط أنابيب RAG.
تستخدم في: نماذج الاسترجاع ونماذج التضمين (OpenAI text-embedding-3, BERT, E5, GTE)
ورق: https://arxiv.org/abs/2104.08663
10. إبرة في كومة قش – اختبار استدعاء السياق الطويل
يختبر هذا المعيار ما إذا كانت نماذج السياق الطويل في الواقع أم لا يستخدم سياقهم.
هناك حقيقة صغيرة ولكن حاسمة مدفونة عميقا داخل وثيقة طويلة. يجب أن يسترده النموذج بشكل صحيح. مع نمو نوافذ السياق، أصبح هذا هو التحقق من السلامة.
تستخدم في: نماذج اللغة ذات السياق الطويل (كلود 3، GPT-4.1، جيميني 2.5)
الريبو المرجعي: https://github.com/gkamradt/LLMTest_NeedleInAHaystack
معايير محسنة
هذه ليست سوى المعايير الأكثر شيوعًا المستخدمة لتقييم LLMs. هناك الكثير من حيث أتوا، وحتى هذه قد تم استبدالها بمتغيرات مجموعة بيانات محسنة مثل MMLU-Pro، وGSM16K وما إلى ذلك. ولكن نظرًا لأن لديك الآن فهمًا سليمًا لما تمثله هذه المعايير، فسيكون الالتفاف حول التحسينات أمرًا سهلاً.
يجب استخدام المعلومات المذكورة أعلاه كمرجع لمعايير LLM الأكثر استخدامًا.
الأسئلة المتداولة
ج: إنهم يقيسون مدى جودة أداء النماذج في مهام مثل التفكير والترميز والاسترجاع مقارنة بالبشر.
ج: إنه معيار ذكاء عام يختبر نماذج اللغة في موضوعات مثل الرياضيات والقانون والطب والتاريخ.
ج. إنه يختبر ما إذا كانت النماذج يمكنها إصلاح مشكلات GitHub الحقيقية عن طريق إنشاء تصحيحات التعليمات البرمجية الصحيحة.
![]()
أنا متخصص في مراجعة وتحسين الأبحاث المستندة إلى الذكاء الاصطناعي والوثائق الفنية والمحتوى المتعلق بتقنيات الذكاء الاصطناعي الناشئة. تشمل خبرتي التدريب على نماذج الذكاء الاصطناعي، وتحليل البيانات، واسترجاع المعلومات، مما يسمح لي بصياغة محتوى دقيق تقنيًا ويمكن الوصول إليه.
قم بتسجيل الدخول لمواصلة القراءة والاستمتاع بالمحتوى الذي ينظمه الخبراء.
Source link