هندسة تسخير مع LangChain DeepAgents وLangSmith

هل تكافح من أجل جعل أنظمة الذكاء الاصطناعي موثوقة ومتسقة؟ تواجه العديد من الفرق نفس المشكلة. تعطي دراسة LLM القوية نتائج رائعة، لكن النموذج الأرخص غالبًا ما يفشل في نفس المهمة. وهذا يجعل من الصعب توسيع نطاق أنظمة الإنتاج. هندسة الحزام تقدم الحل. بدلاً من تغيير النموذج، يمكنك بناء نظام حوله. يمكنك استخدام المطالبات والأدوات والبرامج الوسيطة والتقييم لتوجيه النموذج نحو مخرجات موثوقة. في هذه المقالة، قمت ببناء وكيل تشفير موثوق للذكاء الاصطناعي باستخدام DeepAgents وLangSmith من LangChain. نحن أيضًا نختبر أدائها باستخدام المعايير القياسية.
ما هي هندسة الحزام؟
تركز هندسة Harness على بناء نظام منظم حول LLM لتحسين الموثوقية. بدلاً من تغيير النماذج، يمكنك التحكم في البيئات التي تعمل فيها. يتضمن الحزام موجه النظام، والأدوات أو واجهات برمجة التطبيقات، وإعداد الاختبار، والبرامج الوسيطة التي توجه سلوك النموذج. الهدف هو تحسين نجاح المهمة وإدارة التكاليف أثناء استخدام نفس النموذج الأساسي.
في هذه المقالة، نستخدم مكتبة DeepAgents الخاصة بـ LangChain. تعمل DeepAgents بمثابة أداة مساعدة للوكيل تتمتع بإمكانيات مدمجة مثل تخطيط المهام ونظام الملفات الظاهري في الذاكرة وإنشاء الوكيل الفرعي. ستساعد هذه الميزات في تنظيم سير عمل الوكيل وجعله أكثر موثوقية.
اقرأ أيضًا: دليل LangGraph وLangSmith لبناء وكلاء الذكاء الاصطناعي
التقييم والمقاييس
HumanEval هو معيار يضم 164 مشكلة بايثون مصنوعة يدويًا تُستخدم لتقييم الصحة الوظيفية؛ سوف نستخدم هذه البيانات لاختبار عوامل الذكاء الاصطناعي التي سنقوم ببنائها.
- تمرير @ 1 (نجاح اللقطة الأولى): النسبة المئوية للمسائل التي تم حلها بشكل صحيح بواسطة النموذج في محاولة واحدة. هذا هو المعيار الذهبي لأنظمة الإنتاج حيث يتوقع المستخدمون الإجابة الصحيحة دفعة واحدة.
- Pass@k (نجاح العينات المتعددة): احتمال أن تكون عينة واحدة على الأقل من العينات k صحيحة. يُستخدم هذا لقياس معرفة النموذج أو قوة الاستكشاف.
بناء وكيل ترميز باستخدام Harness Engineering
سنقوم ببناء وكيل ترميز وتقييمه وفقًا للمعايير والمقاييس التي سنحددها. سيتم تنفيذ الوكيل باستخدام مكتبة DeepAgents بواسطة LangChain واستخدام الأفكار الكامنة وراء هندسة التسخير لبناء نظام الذكاء الاصطناعي.
المتطلبات المسبقة (مفاتيح واجهة برمجة التطبيقات)
- قم بزيارة لوحة تحكم LangSmith وانقر على زر “إمكانية المراقبة”. ثم سترى هذه الشاشة. الآن، انقر فوق خيار “إنشاء مفتاح API” واحتفظ بمفتاح LangSmith في متناول يدك.
- سنحتاج أيضًا إلى مفتاح OpenAI API، وسنستخدم نموذج gpt-4.1-mini باعتباره عقل النظام. يمكنك الحصول على مفتاح API من هذا الرابط.
المنشآت
!git clone https://github.com/openai/human-eval.git
!sed -i '/evaluate_functional_correctness/d' human-eval/setup.py
!pip install -qU ./human-eval deepagents langchain-openai التهيئة
import os
from google.colab import userdata
os.environ('LANGCHAIN_TRACING_V2') = 'true'
os.environ('LANGSMITH_API_KEY') = userdata.get('LANGSMITH_API_KEY')
os.environ('LANGSMITH_PROJECT') = 'DeepAgent'
os.environ('OPENAI_API_KEY') = userdata.get('OPENAI_API_KEY')تعريف المطالبات
from langsmith import Client
from langchain_core.prompts import ChatPromptTemplate
ls = Client()
PROMPTS = {
"coding-agent-1": (
"You are a Python coding assistant.\n"
"Given a function signature and docstring, complete the implementation.\n"
"Return ONLY the completed Python function — no prose, no markdown fences."
),
"coding-agent-2": (
"You are a Python coding assistant with a self-verification discipline.\n"
"Steps you MUST follow:\n"
"1. Read the docstring and edge cases carefully.\n"
"2. Write the implementation.\n"
"3. Mentally run the provided examples against your code.\n"
"4. If any example fails, rewrite and repeat step 3.\n"
"Return ONLY the completed Python function. No prose, no markdown fences."
),
"coding-agent-3": (
"You are an expert Python engineer. Think step-by-step before coding.\n"
"\nProcess:\n"
"\n"
" - Restate what the function must do in one sentence.\n"
" - List corner cases (empty inputs, negatives, large values).\n"
" - Choose the simplest correct algorithm.\n"
" \n"
"Then output the completed Python function verbatim — no markdown, no explanation."
),
}
for name, text in PROMPTS.items():
prompt = ChatPromptTemplate.from_messages(
(("system", text), ("human", "{input}"))
)
ls.push_prompt(name, object=prompt)
print(f"pushed: {name}")الإخراج:
pushed: coding-agent-1
pushed: coding-agent-2
pushed: coding-agent-3
لقد قمنا بتحديد المطالبات وإرسالها إلى LangSmith. يمكنك التحقق من ذلك في قسم المطالبات في لوحة تحكم LangSmith:
تعريف وكيلنا الأول
from deepagents import create_deep_agent
from langchain.chat_models import init_chat_model
PROMPT = "coding-agent-1"
pulled = ls.pull_prompt(PROMPT)
system_prompt = pulled.messages(0).prompt.template
print(f"Loaded prompt: {PROMPT}")
print(system_prompt(:120), "...")
model = init_chat_model("openai:gpt-5-mini")
# Creating the DeepAgent
agent = create_deep_agent(
model=model,
system_prompt=system_prompt,
)
print("\nAgent ready")يجب أن يكون الوكيل جاهزًا للاستخدام، فهو يستخدم موجه “coding-agent-1” الذي تم تعريفه مسبقًا.
اختبار الوكيل
# Download the HumanEval benchmark dataset (164 Python coding problems)
!wget -q https://github.com/openai/human-eval/raw/master/data/HumanEval.jsonl.gz -O HumanEval.jsonl.gz
# Import required libraries
import gzip
import json
# Function to read the HumanEval dataset
def read_problems(path="HumanEval.jsonl.gz"):
problems = {}
try:
with gzip.open(path, "rt") as f:
for line in f:
p = json.loads(line)
problems(p("task_id")) = p
except FileNotFoundError:
print("Dataset file not found.")
return problems
# Load all problems
problems = read_problems()
# Extract task IDs
task_ids = list(problems.keys())
# Print total number of problems
print(f"Total problems: {len(task_ids)}")
# Optional: inspect the first problem
example = problems(task_ids(0))
print("\nExample Task ID:", example("task_id"))
print("\nPrompt:\n", example("prompt"))
print("\nCanonical Solution:\n", example("canonical_solution"))إجمالي المشاكل: 164
لدينا الآن 164 مشكلة ترميزية يمكننا استخدامها لاختبار النظام.
توليد الكود مع الوكيل
import re
def extract_code(text: str, prompt: str) -> str:
"""Return just the completed function, stripping any markdown wrapping."""
text = re.sub(r"```python\s*", "", text)
text = re.sub(r"```\s*", "", text)
if text.strip().startswith("def "):
return text.strip()
return prompt + text
def solve(problem: dict) -> str:
result = agent.invoke(
{"messages": ({"role": "user", "content": problem("prompt")})},
config={
"metadata": {
"task_id": problem("task_id"),
"prompt_name": PROMPT,
}
},
)
raw = result("messages")(-1).content
return extract_code(raw, problem("prompt"))
# Test the system on the first problem before running the full evaluation
sample = problems(task_ids(0))
code = solve(sample)
print(code)الإخراج:
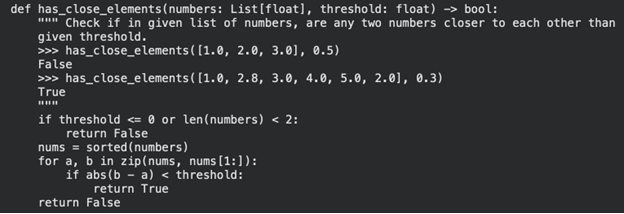
عظيم! لدينا نظام عمل. دعونا نختبرها على 5 مشاكل في البرمجة الآن!
import pandas as pd
# Calculate pass@1 and average latency
passed = sum(r("passed") for r in results)
pass_at_1 = passed / len(results)
avg_latency = sum(r("latency_s") for r in results) / len(results)
print(f"Results : pass@1 = {pass_at_1:.2%} ({passed}/{len(results)})")
print(f"Avg latency = {avg_latency:.1f}s")
# Convert results to DataFrame for easier inspection
df = pd.DataFrame(results)
print(df(("task_id", "passed", "latency_s")).to_string(index=False))
# Print failed tasks for debugging
print("\n── Failures ──")
for _, row in df(~df("passed")).iterrows():
print(f"\n{'─'*60}")
print(f"TASK: {row('task_id')}")
print(row("code")(:400)) # Show first 400 chars of codeالإخراج:
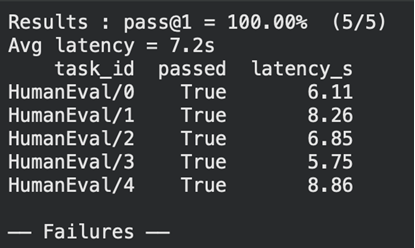
عظيم! لقد أجرينا الاختبارات بنجاح ويمكننا رؤية زمن الوصول لكل منها أيضًا. لنفتح LangSmith لرؤية استخدام الرمز المميز والتكلفة والتفاصيل الأخرى.
افتح LangSmith -> انتقل إلى قسم التتبع -> افتح مشروع DeepAgent:
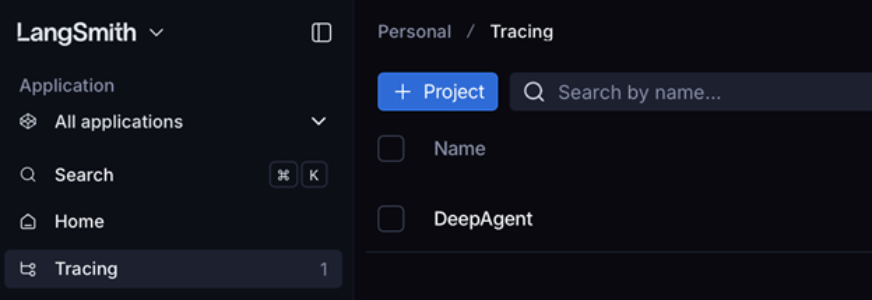
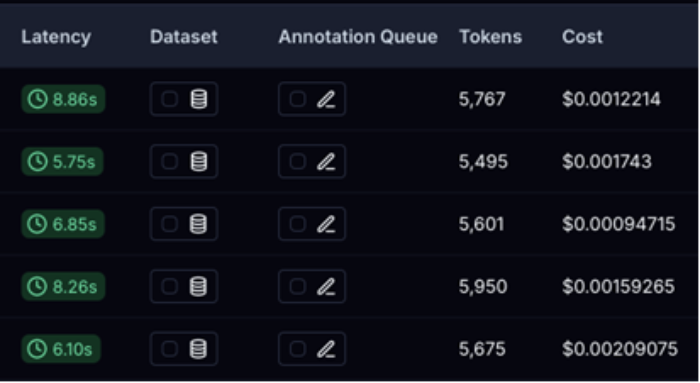
سيكون هذا مفيدًا لمقارنة نتائجنا مع الوكيل الجديد الذي سنقوم ببنائه.
تعريف الوكيل الجديد
from deepagents import create_deep_agent
from langchain.agents.middleware import ModelCallLimitMiddleware
from langchain.chat_models import init_chat_model
SYSTEM_PROMPT = "coding-agent-3"
pulled = ls.pull_prompt(SYSTEM_PROMPT)
system_prompt = pulled.messages(0).prompt.template
# Build the agent
base_model = init_chat_model("openai:gpt-5-mini")
new_agent = create_deep_agent(
model=base_model,
system_prompt=system_prompt,
middleware=(
# Limit model calls to 2 per invocation
ModelCallLimitMiddleware(
run_limit=2,
exit_behavior="end",
),
),
)
def solve(problem: dict) -> str:
result = new_agent.invoke(
{"messages": ({"role": "user", "content": problem("prompt")})},
config={
"metadata": {
"task_id": problem("task_id"),
"prompt_name": SYSTEM_PROMPT,
}
},
)
raw = result("messages")(-1).content
return extract_code(raw, problem("prompt"))اختبار الوكيل الجديد
import time
from human_eval.execution import check_correctness
N_PROBLEMS = 5
TIMEOUT = 5 # seconds per test case
results = ()
for task_id in task_ids(:N_PROBLEMS):
problem = problems(task_id)
t0 = time.time()
# Solve the problem using the agent
code = solve(problem)
latency = time.time() - t0
# Check correctness of the generated code
outcome = check_correctness(problem, code, timeout=TIMEOUT)
results.append({
"task_id": task_id,
"passed": outcome("passed"),
"latency_s": round(latency, 2),
"code": code,
})
status = "PASS" if outcome("passed") else "FAIL"
print(f"{status} {task_id:30s} {latency:.1f}s")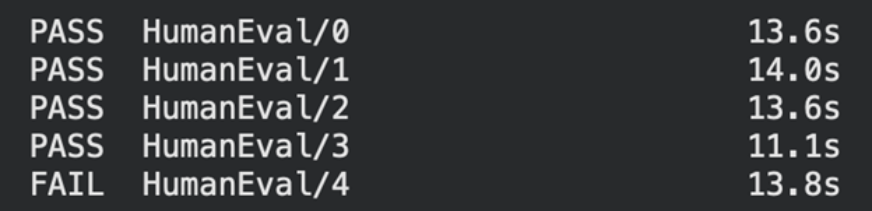
يمكننا أن نرى أن موجهنا 3 قد اجتاز 4 مشكلات ولكنه فشل في حل مشكلة ترميز واحدة.
خاتمة
هل هذا يعني أن موجهنا 1 كان أفضل؟ الإجابة ليست بهذه البساطة، علينا إجراء اختبارات pass@1 عدة مرات لاختبار اتساق الوكيل وبحجم اختبار أكبر بكثير من 5. وهذا يساعدنا في العثور على متوسط زمن الوصول والتكلفة والعامل الأكثر أهمية: موثوقية المهمة. كما أن العثور على البرامج الوسيطة المناسبة وتوصيلها يمكن أن يساعد النظام على الأداء وفقًا لاحتياجاتنا، فهناك برامج وسيطة موجودة لتوسيع قدرات الوكيل والتحكم في عدد استدعاءات النماذج واستدعاءات الأدوات وغير ذلك الكثير. من المهم تقييم الوكيل ومن المؤكد أن LangSmith يمكنه المساعدة في إمكانية التتبع وتخزين المطالبات وإظهار الأخطاء (إن وجدت) من الوكيل. من المهم ملاحظة أنه بينما تركز شركة Prompt Engineering على مدخل، تركز هندسة Harness على بيئة و قيود.
الأسئلة المتداولة
ج: البرامج الوسيطة هي برامج تعمل كجسر بين المكونات، مما يتيح الاتصال ويوسع قدرات الوكيل.
A. البدائل الشائعة لتتبع ومراقبة LLM تشمل Langfuse وArize Phoenix وما إلى ذلك.
ج. تشتمل معايير الصناعة على SWE-bench وBigCodeBench لقياس أداء البرمجة في العالم الحقيقي.
![]()
شغوف بالتكنولوجيا والابتكار، خريج معهد فيلور للتكنولوجيا. أعمل حاليًا كمتدرب في علوم البيانات، مع التركيز على علوم البيانات. مهتم بشدة بالتعلم العميق والذكاء الاصطناعي التوليدي، ومتلهف لاستكشاف التقنيات المتطورة لحل المشكلات المعقدة وإنشاء حلول مؤثرة.
قم بتسجيل الدخول لمواصلة القراءة والاستمتاع بالمحتوى الذي ينظمه الخبراء.
Source link