مقارنة شاملة للمطورين

غالبًا ما يعمل مطورو الذكاء الاصطناعي والتعلم الآلي مع مجموعات البيانات المحلية أثناء المعالجة المسبقة للبيانات. تجعل الميزات الهندسية وبناء النماذج الأولية هذا الأمر سهلاً دون الحاجة إلى تحميل خادم كامل. المقارنة الأكثر شيوعًا هي بين SQLite، وهي قاعدة بيانات بدون خادم تم إصدارها في عام 2000 وتستخدم على نطاق واسع للمعاملات خفيفة الوزن، وDuckDB، التي تم تقديمها في عام 2019 باعتبارها SQLite للتحليلات، والتي تركز على الاستعلامات التحليلية السريعة أثناء العملية. وفي حين أن كليهما مدمجان، فإن أهدافهما تختلف. في هذه المقالة، سنقوم بمقارنة DuckDB وSQLite لمساعدتك في اختيار الأداة المناسبة لكل مرحلة من مراحل سير عمل الذكاء الاصطناعي لديك.
ما هو سكليتي؟
SQLite هو محرك قاعدة بيانات مستقل بدون خادم. يقوم بإنشاء زر مباشرة من ملف القرص. إنه ذو تكوين صفري وله مساحة منخفضة. يتم تخزين كافة قاعدة البيانات في ملف واحد هو.sqlite ويتم تضمين جميع الجداول والفهارس في هذا الملف. المحرك نفسه عبارة عن مكتبة C مضمنة في تطبيقك.
SQLite هي قاعدة بيانات متوافقة مع ACID، على الرغم من أنها بسيطة. وهذا يجعلها يمكن الاعتماد عليها في المعاملات وسلامة البيانات.
تشمل الميزات الرئيسية ما يلي:
- التخزين الموجه نحو الصف: يتم تخزين البيانات صفًا تلو الآخر. وهذا يجعل تحديث أو استرداد صف فردي فعالاً للغاية.
- قاعدة بيانات ذات ملف واحد: قاعدة البيانات بأكملها في ملف واحد. وهذا يتيح إمكانية نسخها أو نقلها بسهولة.
- لا توجد عملية خادم: تتم القراءة والكتابة المباشرة لملف قاعدة البيانات لتطبيقك. ليست هناك حاجة لخادم منفصل.
- دعم SQL واسع النطاق: يعتمد على معظم SQL-2 ويدعم أشياء مثل الصلات ووظائف النوافذ والفهارس.
يتم اختيار SQLite بشكل متكرر في تطبيقات الهاتف المحمول وإنترنت الأشياء، بالإضافة إلى تطبيقات الويب الصغيرة. إنه مضيء عندما تحتاج إلى حل مباشر لتخزين البيانات المنظمة محليًا، وعندما تحتاج إلى العديد من عمليات القراءة والكتابة القصيرة.
ما هو دك دي بي؟
DuckDB هي قاعدة بيانات قيد المعالجة لتحليلات البيانات. يستغرق الأمر قوة قاعدة بيانات SQL للتطبيقات المضمنة. سيتم تنفيذ الاستعلامات التحليلية المعقدة بشكل فعال بدون خادم. غالبًا ما يكون هذا التركيز التحليلي هو أساس المقارنة بين DuckDB وSQLite.
الميزات المهمة لـ DuckDB هي:
- تنسيق التخزين العمودي: يقوم DuckDB بتخزين أعمدة البيانات. في هذا التنسيق، يكون قادرًا على مسح مجموعات البيانات الضخمة ودمجها بمعدل أكبر بكثير. يقرأ فقط الأعمدة التي يتطلبها.
- تنفيذ الاستعلام المتجه: تم تصميم DuckDB لإجراء العمليات الحسابية على شكل أجزاء أو نواقل، وليس في صف واحد. تتضمن هذه الطريقة تطبيق قدرات وحدة المعالجة المركزية الحالية للحساب بمعدل أكبر.
- الاستعلام المباشر عن الملفات: يمكن لـ DuckDB الاستعلام عن ملفات Parquet وCSV وArrow مباشرة. ليست هناك حاجة لوضعها في قاعدة البيانات.
- التكامل العميق لعلم البيانات: وهو متوافق مع Pandas وNumPy وR. ويمكن طرح أسئلة على DataFrame مثل جداول قاعدة البيانات.
يمكن استخدام DuckDB لمعالجة تحليل البيانات التفاعلية بسرعة في دفاتر ملاحظات Jupyter وتسريع سير عمل Pandas. يتطلب الأمر قدرات مستودع البيانات في حزمة صغيرة ومحلية.
الاختلافات الرئيسية
أولاً، إليك جدول ملخص يقارن بين SQLite وDuckDB في الجوانب المهمة.
| وجه | سكليتي (منذ عام 2000) | دك دي بي (منذ 2019) |
| الغرض الأساسي | قاعدة بيانات OLTP المضمنة (المعاملات) | قاعدة بيانات OLAP المضمنة (التحليلات) |
| نموذج التخزين | يستند إلى الصف (يخزن الصفوف بأكملها معًا) | عمودي (يخزن الأعمدة معًا) |
| تنفيذ الاستعلام | معالجة الصفوف التكرارية في كل مرة | معالجة الدفعات الموجهة |
| أداء | ممتاز للمعاملات الصغيرة والمتكررة | ممتاز للاستعلامات التحليلية بشأن البيانات الكبيرة |
| حجم البيانات | الأمثل لمجموعات البيانات الصغيرة والمتوسطة | يتعامل مع مجموعات البيانات الكبيرة والتي نفدت الذاكرة |
| التزامن | قارئ متعدد وكاتب واحد (عبر الأقفال) | متعدد القارئ، كاتب واحد؛ تنفيذ الاستعلام الموازي |
| استخدام الذاكرة | الحد الأدنى من مساحة الذاكرة بشكل افتراضي | يعزز الذاكرة للسرعة. يمكن استخدام المزيد من ذاكرة الوصول العشوائي |
| ميزات SQL | SQL أساسية قوية مع بعض الحدود | دعم SQL واسع للتحليلات المتقدمة |
| الفهارس | غالبًا ما تكون هناك حاجة إلى فهارس B-tree | يعتمد على فحص الأعمدة؛ الفهرسة أقل شيوعًا |
| اندماج | مدعوم بكل اللغات تقريبًا | التكامل الأصلي مع Pandas وArrow وNumPy |
| تنسيقات الملفات | ملف خاص؛ يمكن استيراد/تصدير ملفات CSV | يمكن الاستعلام مباشرة عن Parquet وCSV وJSON وArrow |
| المعاملات | متوافقة تماما مع حمض | ACID في عملية واحدة |
| التوازي | تنفيذ استعلام ذو ترابط واحد | تنفيذ متعدد الخيوط لاستعلام واحد |
| حالات الاستخدام النموذجية | تطبيقات الهاتف المحمول، وأجهزة إنترنت الأشياء، وتخزين التطبيقات المحلية | دفاتر ملاحظات علوم البيانات، وتجارب تعلم الآلة المحلية |
| رخصة | المجال العام | ترخيص معهد ماساتشوستس للتكنولوجيا (مفتوح المصدر) |
يكشف هذا الجدول أن SQLite يركز على الموثوقية وعمليات المعاملات. تم تحسين DuckDB لدعم الاستعلامات التحليلية السريعة حول البيانات الضخمة. والآن سنناقش كل واحد منهم.
التدريب العملي على لغة بايثون: من النظرية إلى التطبيق
سنرى كيفية الاستفادة من قاعدتي البيانات في بايثون. إنها بيئة تطوير مفتوحة المصدر للذكاء الاصطناعي.
باستخدام سكليتي
هذا تمثيل سهل لـ SQLite Python. يجب علينا تطوير جدول وإدخال البيانات وتنفيذ الاستعلام.
import sqlite3
# Connect to a SQLite database file
conn = sqlite3.connect("example.db")
cur = conn.cursor()
# Create a table
cur.execute(
"""
CREATE TABLE users (
id INTEGER PRIMARY KEY,
name TEXT,
age INTEGER
);
"""
)
# Insert records into the table
cur.execute(
"INSERT INTO users (name, age) VALUES (?, ?);",
("Alice", 30)
)
cur.execute(
"INSERT INTO users (name, age) VALUES (?, ?);",
("Bob", 35)
)
conn.commit()
# Query the table
for row in cur.execute(
"SELECT name, age FROM users WHERE age > 30;"
):
print(row)
# Expected output: ('Bob', 35)
conn.close()الإخراج:
يتم الاحتفاظ بقاعدة البيانات في هذه الحالة في ملف example.db ملف. لقد أنشأنا جدولًا وأضفنا صفين إليه وقمنا بتنفيذ استعلام بسيط. يتيح لك SQLite تحميل البيانات في الجداول ثم الاستعلام عنها. إذا كان لديك ملف CSV، فيجب عليك استيراد المعلومات أولاً.
باستخدام دك دي بي
ومع ذلك، فقد حان الوقت لتكرار هذا الخيار مع DuckDB. يجب علينا أيضًا أن نلفت انتباهك إلى وسائل الراحة الخاصة بعلم البيانات.
import duckdb
import pandas as pd
# Connect to an in-memory DuckDB database
conn = duckdb.connect()
# Create a table and insert data
conn.execute(
"""
CREATE TABLE users (
id INTEGER,
name VARCHAR,
age INTEGER
);
"""
)
conn.execute(
"INSERT INTO users VALUES (1, 'Alice', 30), (2, 'Bob', 35);"
)
# Run a query on the table
result = conn.execute(
"SELECT name, age FROM users WHERE age > 30;"
).fetchall()
print(result) # Expected output: (('Bob', 35))الإخراج:
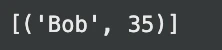
الاستخدام البسيط يشبه الاستخدام الأساسي. ومع ذلك، يمكن أيضًا الاستعلام عن البيانات الخارجية بواسطة DuckDB.
لنقم بإنشاء مجموعة بيانات عشوائية للاستعلام:
import pandas as pd
import numpy as np
# Generate random sales data
np.random.seed(42)
num_entries = 1000
data = {
"category": np.random.choice(
("Electronics", "Clothing", "Home Goods", "Books"),
num_entries
),
"price": np.round(
np.random.uniform(10, 500, num_entries),
2
),
"region": np.random.choice(
("EUROPE", "AMERICA", "ASIA"),
num_entries
),
"sales_date": (
pd.to_datetime("2023-01-01")
+ pd.to_timedelta(
np.random.randint(0, 365, num_entries),
unit="D"
)
)
}
sales_df = pd.DataFrame(data)
# Save to sales_data.csv
sales_df.to_csv("sales_data.csv", index=False)
print("Generated 'sales_data.csv' with 1000 entries.")
print(sales_df.head())الإخراج:
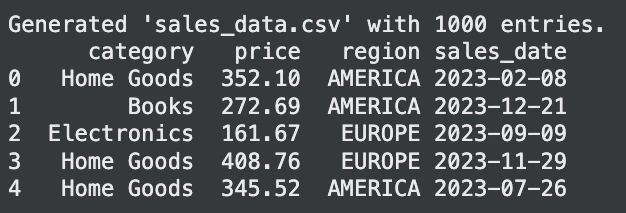
الآن لنستفسر عن هذا الجدول:
# Assume 'sales_data.csv' exists
# Example 1: Querying a CSV file directly
avg_prices = conn.execute(
"""
SELECT
category,
AVG(price) AS avg_price
FROM 'sales_data.csv'
WHERE region = 'EUROPE'
GROUP BY category;
"""
).fetchdf() # Returns a Pandas DataFrame
print(avg_prices.head())
# Example 2: Querying a Pandas DataFrame directly
df = pd.DataFrame({
"id": range(1000),
"value": range(1000)
})
result = conn.execute(
"SELECT COUNT(*) FROM df WHERE value % 2 = 0;"
).fetchone()
print(result) # Expected output: (500,)الإخراج:
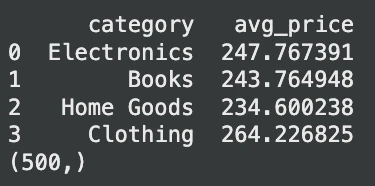
في هذه الحالة، يقرأ DuckDB ملف CSV بسرعة. لا توجد خطوة مهمة مطلوبة. كما أنه قادر على الاستعلام عن Pandas DataFrame. تعمل هذه المرونة على إزالة الكثير من تعليمات تحميل البيانات وتبسيط خطوط أنابيب الذكاء الاصطناعي.
الهندسة المعمارية: لماذا يؤدون بشكل مختلف
تتعلق الاختلافات في أداء SQLite وDuckDB بمحركات التخزين والاستعلام الخاصة بهما.
- نموذج التخزين: سكليتي يعتمد على الصف. يقوم بتجميع كافة البيانات الخاصة بصف واحد فيه. يعد هذا أمرًا جيدًا جدًا لتحديث سجل واحد. ومع ذلك، فهو ليس سريعًا في التحليلات. على افتراض أنك تحتاج فقط إلى عمود واحد، فلا يزال يتعين على SQLite قراءة جميع بيانات كل صف. DuckDB موجه نحو العمود. فهو يضع جميع قيم عمود واحد في عمود واحد. هذا مثالي للتحليلات. استعلام مثل
SELECT AVG(age)يقرأ فقط عمر العمود الذي هو أسرع بكثير. - تنفيذ الاستعلام: SQLite استعلام واحد لكل صف. يعد هذا فعالاً في استخدام الذاكرة عندما يتعلق الأمر بالاستعلامات الصغيرة. يعتمد DuckDB على التنفيذ الموجه. إنه يعمل مع البيانات على دفعات كبيرة. تستخدم هذه التقنية وحدات المعالجة المركزية الحالية لإجراء عمليات تسريع كبيرة لعمليات الفحص والربط الكبيرة. كما أنه قادر على تنفيذ العديد من سلاسل العمليات لتنفيذ استعلام واحد في المرة الواحدة.
- الذاكرة والسلوك على القرص: تم تصميم SQLite لاستخدام الحد الأدنى من الذاكرة. يقرأ من القرص حسب الحاجة. يستخدم DuckDB الذاكرة لتحسين السرعة. يمكنه تنفيذ بيانات أكبر من ذاكرة الوصول العشوائي المتوفرة في التنفيذ خارج المركز. وهذا يعني أن DuckDB يمكن أن يستهلك ذاكرة وصول عشوائي إضافية، ولكنه أسرع بكثير في المهمة التحليلية. لقد ثبت أن استعلامات التجميع في DuckDB أسرع بمعدل 10 إلى 100 مرة من SQLite.
الحكم: متى يجب استخدام DuckDB مقابل SQLite
يعد هذا دليلًا جيدًا يجب اتباعه في مشاريع الذكاء الاصطناعي والتعلم الآلي.
| وجه | استخدم SQLite متى | استخدم DuckDB متى |
|---|---|---|
| الغرض الأساسي | أنت بحاجة إلى قاعدة بيانات معاملات خفيفة الوزن | أنت بحاجة إلى تحليلات محلية سريعة |
| حجم البيانات | انخفاض حجم البيانات، حيث يصل إلى بضع مئات من ميغابايت | مجموعات البيانات المتوسطة إلى الكبيرة |
| نوع عبء العمل | الإدراجات والتحديثات وعمليات البحث البسيطة | التجميعات والصلات وعمليات فحص الجداول الكبيرة |
| احتياجات المعاملات | تحديثات صغيرة متكررة مع سلامة المعاملات | قراءة الاستعلامات التحليلية الثقيلة |
| التعامل مع الملفات | البيانات المخزنة داخل قاعدة البيانات | الاستعلام عن ملفات CSV أو Parquet مباشرة |
| التركيز على الأداء | الحد الأدنى من البصمة والبساطة | أداء تحليلي عالي السرعة |
| اندماج | تطبيقات الهاتف المحمول، الأنظمة المدمجة، إنترنت الأشياء | تسريع التحليل القائم على الباندا |
| التنفيذ الموازي | ليست أولوية | يستخدم نوى وحدة المعالجة المركزية المتعددة |
| حالة الاستخدام النموذجي | حالة التطبيق والتخزين الخفيف | استكشاف البيانات المحلية والتحليلات |
خاتمة
تعد كل من SQLite وDuckDB قاعدتي بيانات مضمنتين قويتين. SQLite عبارة عن أداة جيدة جدًا لتخزين البيانات وخفيفة الوزن وأداة معاملات سهلة. ومع ذلك، يمكن لـ DuckDB تسريع معالجة البيانات والنماذج الأولية لمطوري الذكاء الاصطناعي الذين يعملون بالبيانات الضخمة بشكل كبير. وذلك لأنه عندما تدرك الاختلافات بينهما، ستعرف الأداة المناسبة لاستخدامها في المهام المختلفة. في حالة تحليل البيانات وعمليات التعلم الآلي المعاصرة، يمكن لـ DuckDB توفير الكثير من الوقت مع فائدة كبيرة في الأداء.
الأسئلة المتداولة
ج: لا، فهي ذات استخدامات أخرى. يتم استخدام DuckDB للوصول إلى التحليلات السريعة (OLAP)، في حين يتم استخدام SQLite للدخول في معاملات موثوقة. اختر وفقا لحجم العمل الخاص بك.
ج: عادةً ما يكون SQLite أكثر ملاءمة لتطبيقات الويب التي تحتوي على عدد كبير من عمليات القراءة والكتابة الصغيرة المتصلة، لأنه يحتوي على نموذج معاملات سليم ووضع WAL.
ج: نعم، مع معظم المهام واسعة النطاق، مثل عمليات التجميع والانضمام، يمكن أن تكون DuckDB أسرع بكثير من Pandas نظرًا لمحركها المتوازي والمتجه.
![]()
هارش ميشرا هو مهندس الذكاء الاصطناعي والتعلم الآلي الذي يقضي وقتًا أطول في التحدث إلى نماذج اللغات الكبيرة مقارنة بالبشر الفعليين. شغوف بـ GenAI وNLP وجعل الآلات أكثر ذكاءً (لذلك لا يحل محله بعد). عندما لا يقوم بتحسين النماذج، فمن المحتمل أنه يقوم بتحسين تناول القهوة. 🚀☕
قم بتسجيل الدخول لمواصلة القراءة والاستمتاع بالمحتوى الذي ينظمه الخبراء.
Source link