ما هي نماذج اللغة العودية (RLM)؟

نماذج اللغات الكبيرة رائعة. يمكننا جميعا أن نتفق على ذلك. لقد كانت حجر الزاوية في الصناعة الحديثة وتؤثر بشكل متزايد على المزيد والمزيد من المجالات.
مع الترقيات والتحسينات المستمرة لبنية وقدرات نماذج اللغة، قد يعتقد المرء – هذا كل شيء! للأسف… لقد احتل التطور الأخير تحت اسم RLM أو نماذج اللغة العودية مركز الصدارة الآن.
ما هذا؟ كيف ترتبط بـ LLMs؟ وكيف يمكن أن يدفع حدود الذكاء الاصطناعي؟ سنكتشف في هذه المقالة ما الذي يشرح هذه التكنولوجيا الحديثة بطريقة يسهل الوصول إليها. لنبدأ بمراجعة المشكلات التي تعاني منها LLMs الحالية.
مشكلة أساسية
LLMs لها حدود معمارية. يطلق عليه نافذة الرمز المميز. هذا هو الحد الأقصى لعدد الرموز المميزة التي يمكن للنموذج قراءتها فعليًا في تمريرة أمامية واحدة، ويتم تحديدها بواسطة التضمينات الموضعية للمحول + الذاكرة. إذا كان الإدخال أطول من هذا الحد، فلن يتمكن النموذج من معالجته. إنه مثل محاولة تحميل ملف بحجم 5 جيجابايت إلى برنامج بسعة 500 ميجابايت من ذاكرة الوصول العشوائي. يؤدي إلى الفائض! فيما يلي النوافذ الرمزية لبعض النماذج الشائعة:
| نموذج | نافذة الرمز الأقصى |
| جوجل الجوزاء (الأحدث) | 1,000,000 |
| OpenAI GPT-5 (الأحدث) | 400000 |
| كلود الأنثروبي (الأحدث) | 200000 |
عادة، كلما كان الرقم أكبر، كان الموديل أفضل… أم هو كذلك؟
تعفن السياق: الفشل الخفي قبل الحد
وهنا المصيد. حتى عندما يتم إدخال مطالبة داخل نافذة الرمز المميز، تنخفض جودة النموذج بهدوء مع زيادة طول الإدخال. يصبح الانتباه منتشرًا، وتفقد المعلومات السابقة تأثيرها، ويبدأ النموذج في فقدان الروابط عبر الأجزاء البعيدة من النص. وتعرف هذه الظاهرة ب تعفن السياق.
لذا، على الرغم من أن النموذج قد يقبل من الناحية الفنية مليون رمز، إلا أنه لا يستطيع ذلك في كثير من الأحيان سبب بشكل موثوق عبر كل منهم. في الممارسة العملية، ينهار الأداء قبل وقت طويل من الوصول إلى نافذة الرمز المميز.
نافذة السياق
نافذة السياق هي مقدار المعلومات التي يمكن للنموذج استخدامها جيدًا قبل انهيار الأداء. يتغير هذا الرقم بناءً على مدى تعقيد المطالبة ونوع البيانات التي تتم معالجتها. ال فعال نافذة السياق الخاصة بـ LLM أصغر بكثير من نافذة الرمز المميز. وعلى عكس نافذة الرمز المميز، التي تكون محددة إلى حد ما، تتغير نافذة السياق مع تعقيد الموجه. ويتجلى ذلك من خلال الأداء الضعيف لطلاب LLM في نافذة الرموز المميزة الكبيرة في مهام الاستدلال، حيث يتطلب ذلك الاحتفاظ بجميع المعلومات التي يتم تغذيتها بشكل متزامن تقريبًا.
هذه مشكلة. من المرغوب فيه نوافذ السياق الطويلة وبالتالي نوافذ الرمز المميز، ولكن فقدان السياق (بسبب طولها) أمر لا مفر منه… أو على الأقل ذلك كان.
نماذج اللغة العودية: للإنقاذ
على الرغم من الاسم، فإن RLMs ليست فئة نموذجية جديدة مثل LLM وVLM وSLM وما إلى ذلك. استراتيجية الاستدلال. حل لمشكلة تعفن السياق في المطالبات الطويلة. تتعامل RLMs مع المطالبات الطويلة كجزء من بيئة خارجية وتسمح لـ LLM بفحص نفسها وتفكيكها واستدعاء نفسها بشكل متكرر عبر مقتطفات من الموجه.
وهذا يجعل نافذة السياق أكبر عدة مرات من المعتاد. ويفعل ذلك بطريقة مماثلة:
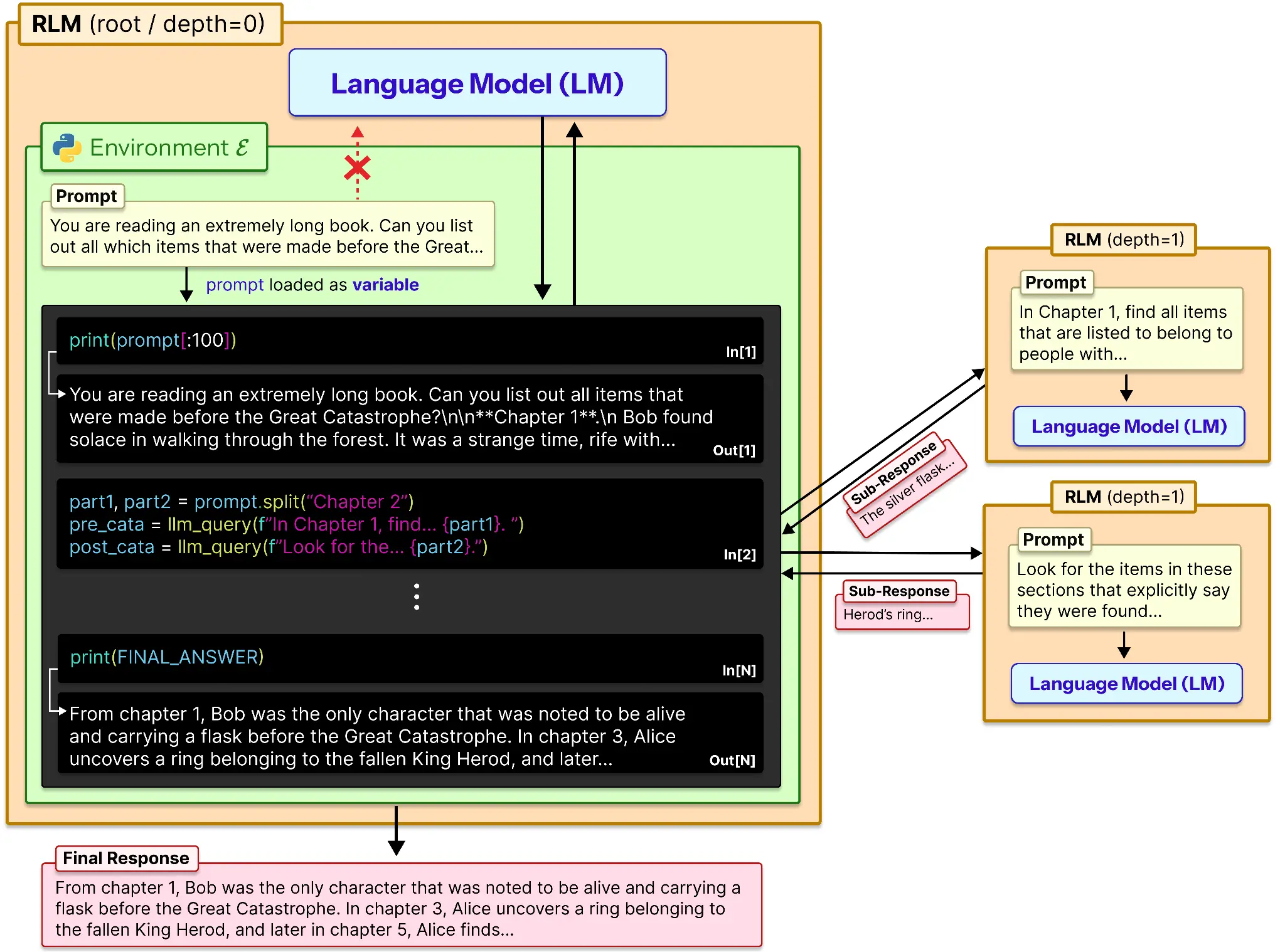
من الناحية النظرية، توفر RLM ذاكرة خارجية LLM وطريقة للعمل عليها. وهنا كيف يعمل:
- يتم تحميل المطالبة في متغير.
- يتم ربط هذا المتغير اعتمادًا على الذاكرة أو الرقم المشفر.
- يتم إرسال هذه البيانات إلى LLM ويتم حفظ مخرجاتها للرجوع إليها.
- وبالمثل تتم معالجة جميع أجزاء الموجه بشكل فردي ويتم تسجيل مخرجاتها.
- يتم استخدام قائمة المخرجات هذه لإنتاج الاستجابة النهائية للنموذج.
يمكن استخدام نموذج فرعي مثل o3-mini أو أي نموذج آخر مفيد لمساعدة النموذج على التلخيص أو التفكير محليًا في موجه فرعي.
أليس هذا…التقطيع؟
للوهلة الأولى، قد يبدو هذا وكأنه تقطيع ممجد. لكن الأمر مختلف جذريًا. يُجبر التقطيع التقليدي النموذج على نسيان القطع السابقة أثناء تقدمه. تحافظ RLM على كل شيء على قيد الحياة خارج النموذج وتسمح لـ LLM بإعادة النظر بشكل انتقائي في أي جزء عند الحاجة. إنها لا تلخص الذاكرة، بل تبحر فيها.
ما هي المشاكل التي يحلها RLM أخيرًا؟
يفتح RLM الأشياء التي يفشل فيها LLMs العاديون باستمرار في:
- التفكير في البيانات الضخمة: بدلاً من نسيان الأجزاء السابقة، يمكن للنموذج إعادة النظر في أي قسم من المدخلات الضخمة.
- التوليف متعدد المستندات: فهو يسحب الأدلة من مصادر متفرقة دون تجاوز حدود السياق.
- المهام كثيفة المعلومات: يعمل حتى عندما تعتمد الإجابات على كل سطر من الإدخال تقريبًا.
- مخرجات منظمة طويلة: يبني النتائج خارج نافذة الرمز المميز ويجمعها معًا بشكل نظيف.
باختصار: يتيح RLM لطلاب LLM التعامل مع الحجم والكثافة والبنية التي تكسر المطالبات التقليدية.
المقايضات
مع كل ما يحله RLM، هناك بعض الجوانب السلبية له أيضًا:
| القيد | تأثير |
| عدم التطابق الفوري عبر النماذج | يؤدي موجه RLM نفسه إلى سلوك غير مستقر ومكالمات متكررة مفرطة |
| يتطلب قدرة ترميز قوية | تفشل النماذج الأضعف في التعامل مع السياق بشكل موثوق في REPL |
| استنفاد رمز الإخراج | تتجاوز سلاسل الاستدلال الطويلة حدود المخرجات وتقتطع المسارات |
| لا توجد مكالمات فرعية غير متزامنة | العودية التسلسلية تزيد بشكل كبير من الكمون |
باختصار: تقوم RLM بتداول السرعة الأولية والاستقرار من أجل الحجم والعمق.
خاتمة
يُستخدم توسيع نطاق LLMs ليعني المزيد من المعلمات ونوافذ رمزية أكبر. تقدم RLM محورًا ثالثًا: بنية الاستدلال. بدلًا من بناء أدمغة أكبر، نقوم بتعليم النماذج كيفية استخدام الذاكرة خارج أدمغتها، تمامًا كما يفعل البشر.
إنها نظرة شمولية. إنه ليس أكثر مما كان عليه من قبل كالمعتاد. بالأحرى نهج جديد في الأساليب التقليدية للتشغيل النموذجي.
الأسئلة المتداولة
ج: إنهم يتغلبون على حدود نافذة الرمز المميز وتعفن السياق، مما يسمح لطلاب LLM بالتفكير بشكل موثوق عبر المطالبات الطويلة للغاية وكثيفة المعلومات.
ج: لا، تعد RLMs بمثابة إستراتيجية استدلال تتيح لـ LLMs التفاعل مع المطالبات الطويلة خارجيًا والاستعلام بشكل متكرر عن أجزاء أصغر.
أ. التقطيع التقليدي ينسى الأجزاء السابقة. تحتفظ RLM بالموجه الكامل خارج النموذج وتعيد زيارة أي قسم عند الحاجة.
![]()
أنا متخصص في مراجعة وتحسين الأبحاث المستندة إلى الذكاء الاصطناعي والوثائق الفنية والمحتوى المتعلق بتقنيات الذكاء الاصطناعي الناشئة. تشمل خبرتي التدريب على نماذج الذكاء الاصطناعي، وتحليل البيانات، واسترجاع المعلومات، مما يسمح لي بصياغة محتوى دقيق تقنيًا ويمكن الوصول إليه.
قم بتسجيل الدخول لمواصلة القراءة والاستمتاع بالمحتوى الذي ينظمه الخبراء.
Source link