ما هي سلسلة الفكر (CoT) التي تحث؟

الفكرة الأساسية وراء سلسلة التفكير (CoT) هي تشجيع نموذج الذكاء الاصطناعي على التفكير خطوة بخطوة قبل تقديم إجابة. في حين أن المفهوم في حد ذاته ليس جديدًا وهو في الأساس طريقة منظمة لمطالبة النماذج بشرح أسبابها، إلا أنه يظل ذا أهمية كبيرة اليوم. زاد الاهتمام بـ CoT مرة أخرى بعد أن أصدرت OpenAI معاينة لنموذج o1 الخاص بها، والذي جدد التركيز على مناهج الاستدلال أولاً. في هذه المقالة، سأشرح ما هو CoT، واستكشف التقنيات المختلفة المتاحة للجمهور، واختبر ما إذا كانت هذه الأساليب تعمل بالفعل على تحسين أداء نماذج الذكاء الاصطناعي الحديثة. دعونا نتعمق.
البحث وراء سلسلة من الأفكار المشجعة
على مدى العامين الماضيين، تم نشر العديد من الأوراق البحثية حول هذا الموضوع. ما لفت انتباهي مؤخرًا هو هذا المستودع الذي يجمع الأبحاث الرئيسية المتعلقة بسلسلة الفكر (CoT).
يتم توضيح تقنيات التفكير المختلفة خطوة بخطوة التي تمت مناقشتها في هذه الأوراق في الصورة أدناه. لقد أتى جزء كبير من هذا العمل المؤثر مباشرةً من مجموعات بحثية في DeepMind وPrinston.
تم تقديم فكرة COT لأول مرة بواسطة DeepMind في عام 2022. ومنذ ذلك الحين، استكشفت الأبحاث الأحدث تقنيات أكثر تقدمًا، مثل الجمع بين شجرة الأفكار (ToT) وبحث Monte Carlo، بالإضافة إلى استخدام CoT دون أي مطالبة أولية، والتي يشار إليها عادةً باسم CoT بدون إطلاق.
النتيجة الأساسية للماجستير في القانون: كيف يتم قياس أداء النموذج
قبل أن نتحدث عن تحسين نماذج اللغات الكبيرة (LLMs)، نحتاج أولاً إلى طريقة لقياس مدى جودة أدائها اليوم. ويسمى هذا القياس الأولي النتيجة الأساسية. يساعدنا خط الأساس على فهم القدرات الحالية للنموذج ويوفر نقطة مرجعية لتقييم أي تقنيات تحسين، مثل المطالبة بسلسلة الأفكار.
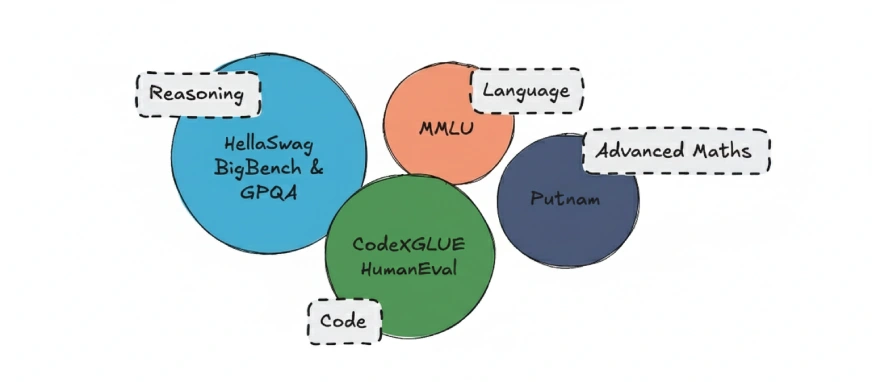
عادة ما يتم تقييم LLMs باستخدام معايير موحدة. بعض منها شائعة الاستخدام تشمل:
- MMLU: اختبارات فهم اللغة
- بيج بينش: يقيم القدرات المنطقية
- هيلا سواج: يقيس المنطق المنطقي
ومع ذلك، لا ينبغي أن تؤخذ جميع الدرجات المرجعية في ظاهرها. يبلغ عمر العديد من مجموعات بيانات التقييم الشائعة عدة سنوات وقد تعاني من تلوث البيانات، مما يعني أن النماذج ربما تكون قد شاهدت أجزاء من بيانات الاختبار بشكل غير مباشر أثناء التدريب. يمكن أن يؤدي هذا إلى تضخيم النتائج المبلغ عنها وإعطاء صورة مضللة لأداء النموذج الحقيقي.
ولمعالجة هذه المشكلة، ظهرت جهود تقييم جديدة. على سبيل المثال، أصدرت Hugging Face لوحة صدارة LLM محدثة تعتمد على مجموعات اختبار أحدث وأقل تلوثًا. في هذه المعايير الأحدث، سجلت معظم النماذج درجات أقل بشكل ملحوظ مما كانت عليه في مجموعات البيانات القديمة، مما يسلط الضوء على مدى حساسية التقييمات لقياس الجودة.
ولهذا السبب فإن فهم كيفية تقييم LLMs لا يقل أهمية عن النظر إلى الدرجات نفسها. في العديد من بيئات العالم الحقيقي، تختار المؤسسات بناء مجموعات تقييم داخلية خاصة مصممة خصيصًا لحالات الاستخدام الخاصة بها، والتي غالبًا ما توفر خط أساس أكثر موثوقية وذات معنى من المعايير العامة وحدها.
اقرأ أيضًا: 14 معيارًا مشهورًا لـ LLM يجب معرفتها في عام 2026
عرض رفيع المستوى لسلسلة الفكر (CoT)
تم تقديم سلسلة الفكر من قبل فريق Brain في DeepMind في ورقتهم البحثية لعام 2022 سلسلة الأفكار التي تحث على التفكير في النماذج اللغوية الكبيرة.
في حين أن فكرة الاستدلال خطوة بخطوة ليست جديدة، فقد اكتسبت CoT اهتمامًا متجددًا بعد إصدار نموذج O1 الخاص بـ OpenAI، والذي أعاد التركيز على مناهج الاستدلال أولاً. استكشفت ورقة DeepMind كيف يمكن للمطالبات المصممة بعناية أن تشجع نماذج اللغة الكبيرة على التفكير بشكل أكثر وضوحًا قبل تقديم إجابة.
سلسلة الأفكار هي تقنية تحفيزية تعمل على تنشيط القدرة المنطقية الكامنة في النموذج من خلال تشجيعه على تقسيم المشكلة إلى خطوات منطقية أصغر بدلاً من الإجابة مباشرة. وهذا يجعله مفيدًا بشكل خاص للمهام التي تتطلب تفكيرًا متعدد الخطوات، مثل الرياضيات والمنطق والفهم المنطقي.
في الوقت الذي تم فيه تقديم هذا البحث، كانت معظم أساليب التحفيز تعتمد بشكل أساسي على التحفيز مرة واحدة أو عدة مرات دون توجيه عملية الاستدلال الخاصة بالنموذج بشكل واضح.
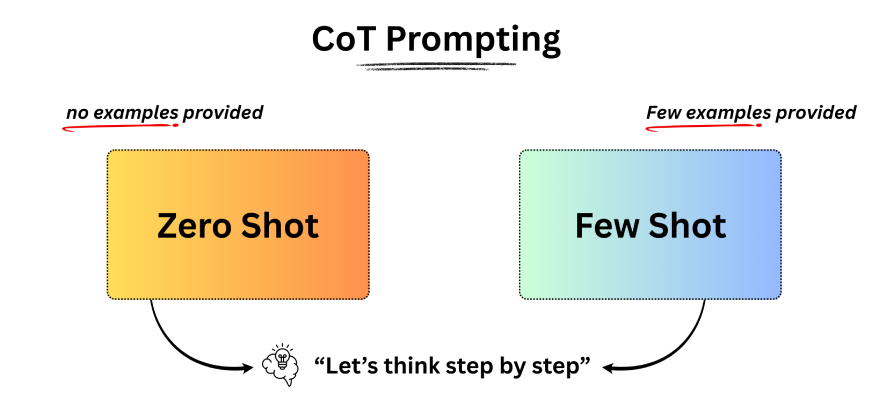
فهم المطالبة بالطلقة الصفرية
تعني المطالبة الصفرية مطالبة النموذج بأداء مهمة دون تقديم أي أمثلة أو سياق مسبق. على سبيل المثال، يمكنك فتح ChatGPT أو نموذج تفكير آخر وطرح سؤال مباشرةً. يعتمد النموذج بشكل كامل على معرفته الحالية لتوليد إجابة.
في هذا الإعداد، لا يتضمن الموجه أي أمثلة، ومع ذلك لا يزال بإمكان LLM فهم المهمة وتقديم استجابة ذات معنى. تعكس هذه القدرة قدرة النموذج على إطلاق النار على الصفر. ثم يطرح سؤال طبيعي: هل يمكننا تحسين الأداء الصفري؟ الجواب هو نعم، من خلال تقنية تسمى ضبط التعليمات. العثور على المزيد حوله هنا.
يتضمن ضبط التعليمات تدريب النموذج ليس فقط على النص الخام ولكن أيضًا على مجموعات البيانات المنسقة كتعليمات واستجابات مقابلة. وهذا يساعد النموذج على تعلم كيفية اتباع التعليمات بشكل أكثر فعالية، حتى بالنسبة للمهام التي لم يسبق له رؤيتها بوضوح من قبل. ونتيجة لذلك، فإن النماذج التي تم ضبطها وفقًا للتعليمات تؤدي أداءً أفضل بكثير في إعدادات اللقطة الصفرية.
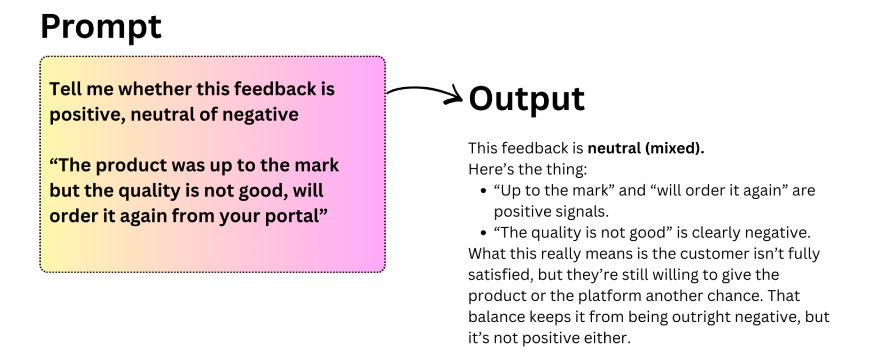
يعزز التعلم المعزز من الملاحظات البشرية (RLHF) هذه العملية من خلال مواءمة مخرجات النموذج مع التفضيلات البشرية. بعبارات بسيطة، يقوم ضبط التعليمات بتعليم النموذج كيفية الاستجابة للتعليمات، بينما يعلمه RLHF كيفية الاستجابة بطرق يجدها البشر مفيدة ومناسبة.
تستخدم النماذج الشائعة مثل ChatGPT وClaude وMistral وPhi-3 مزيجًا من ضبط التعليمات وRLHF. ومع ذلك، لا تزال هناك حالات قد لا تكون فيها المطالبة بالطلقة الصفرية كافية. في مثل هذه المواقف، قد يؤدي تقديم بعض الأمثلة في الموجه، المعروف باسم المطالبة بعدد قليل من اللقطات، إلى نتائج أفضل.
اقرأ أيضًا: Base LLM مقابل Instruction-Tuned LLM
فهم مطالبة قليل من الطلقات
تكون المطالبة بالطلقات القليلة مفيدة عندما تؤدي المطالبة بالطلقة الصفرية إلى نتائج غير متناسقة. في هذا النهج، يتم إعطاء النموذج عددًا صغيرًا من الأمثلة ضمن الموجه لتوجيه سلوكه. يتيح ذلك التعلم في السياق، حيث يستنتج النموذج الأنماط من الأمثلة ويطبقها على المدخلات الجديدة. البحث الذي أجراه كابلان وآخرون. (2020) و توفيرون وآخرون. (2023) يوضح أن هذه القدرة تظهر على شكل مقياس نماذج.
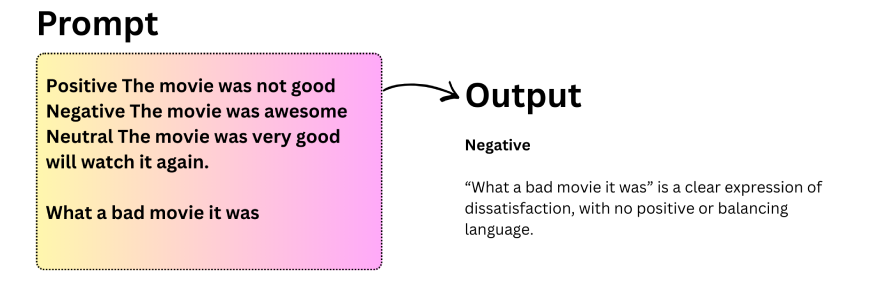
الملاحظات الرئيسية حول المطالبة بالطلقات القليلة:
- يمكن أن تقوم LLMs بالتعميم بشكل جيد حتى عندما تكون تسميات الأمثلة عشوائية.
- تظل النماذج قوية في مواجهة التغييرات أو التشوهات في تنسيق الإدخال.
- غالبًا ما تعمل المطالبة بعدد قليل من الطلقات على تحسين الدقة مقارنةً بالمطالبة بدون طلقة.
- يواجه صعوبة في أداء المهام التي تتطلب تفكيرًا متعدد الخطوات، مثل العمليات الحسابية المعقدة.
عندما لا يكون التحفيز الصفري والقليل من التحفيز كافيين، تكون هناك حاجة إلى تقنيات أكثر تقدمًا مثل تحفيز سلسلة الأفكار للتعامل مع مهام التفكير الأعمق.
فهم سلسلة الفكر (CoT)
يتيح تحفيز سلسلة الأفكار (CoT) التفكير المعقد من خلال تشجيع النموذج على إنشاء خطوات تفكير متوسطة قبل الوصول إلى إجابة نهائية. من خلال تقسيم المشكلات إلى خطوات منطقية أصغر، يساعد CoT طلاب LLM على التعامل مع المهام التي تتطلب تفكيرًا متعدد الخطوات. ويمكن أيضًا دمجها مع عدد قليل من اللقطات للحصول على أداء أفضل.
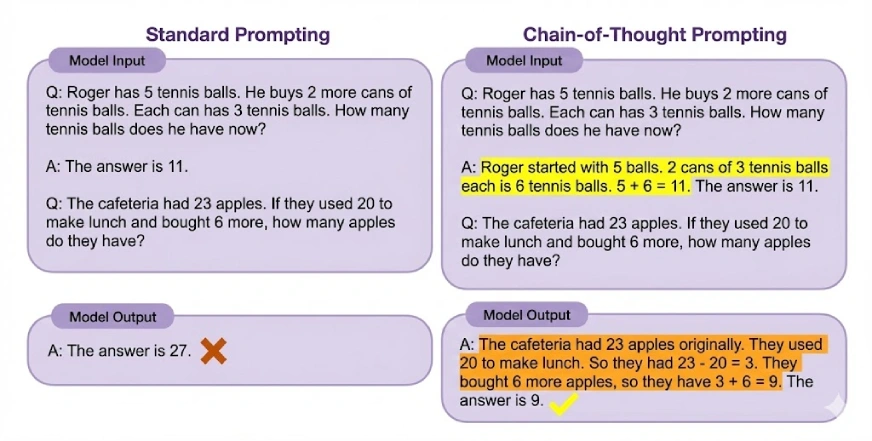
دعونا نجرب سلسلة الأفكار المحفزة:
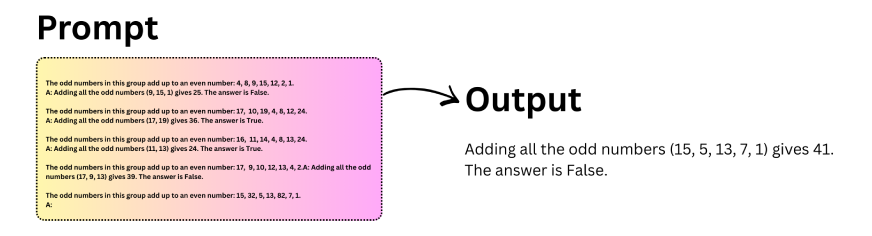
البديل المستخدم على نطاق واسع لهذا النهج هو سلسلة الفكر الصفرية. بدلاً من تقديم الأمثلة، يمكنك ببساطة إضافة تعليمات قصيرة مثل “دعونا نفكر خطوة بخطوة” إلى الموجه. غالبًا ما يكون هذا التغيير البسيط كافيًا لتحفيز التفكير المنظم في النموذج.
دعونا نفهم هذا بمساعدة مثال:
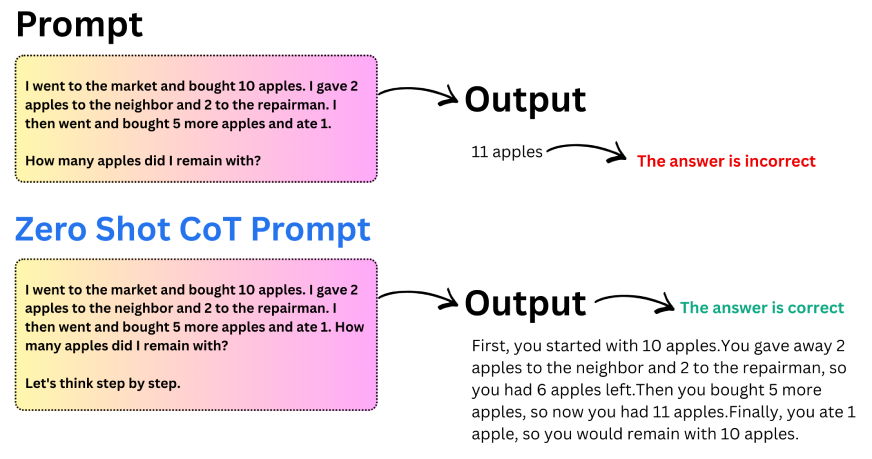
الوجبات الرئيسية من Zero-Shot CoT:
- يمكن أن تؤدي إضافة تعليمات استدلالية واحدة إلى تحسين الدقة بشكل كبير.
- تنتج النماذج إجابات أكثر تنظيماً ومنطقية.
- يُعد Zero-shot CoT مفيدًا عندما لا تتوفر أمثلة.
- إنه يعمل بشكل جيد بشكل خاص في مهام التفكير الحسابي والمنطقي.
توضح هذه التقنية البسيطة والقوية كيف يمكن للتغييرات الطفيفة في التحفيز أن تؤدي إلى تحسينات ذات معنى في التفكير النموذجي.
سلسلة التفكير التلقائية (Auto-CoT)
تتطلب سلسلة التفكير القياسية من البشر إنشاء أمثلة منطقية يدويًا، وهو ما يستغرق وقتًا طويلاً وعرضة للأخطاء. غالبًا ما واجهت المحاولات السابقة لأتمتة هذه العملية استدلالًا صاخبًا أو غير صحيح. يعالج Auto-CoT هذه المشكلة من خلال التأكيد على التنوع في الأمثلة المنطقية التي يولدها، مما يقلل من تأثير الأخطاء الفردية.
بدلاً من الاعتماد على المطالبات المكتوبة بعناية، يقوم Auto-CoT تلقائيًا باختيار الأسئلة التمثيلية من مجموعة بيانات وإنشاء سلاسل منطقية لها. وهذا يجعل النهج أكثر قابلية للتطوير وأقل اعتمادا على الجهد البشري.
يعمل Auto-CoT على مرحلتين:
- المرحلة 1 – التجميع: يتم تجميع الأسئلة من مجموعة البيانات في مجموعات بناءً على التشابه. وهذا يضمن التغطية عبر أنواع مختلفة من المشاكل.
- المرحلة الثانية – أخذ العينات: ويتم اختيار سؤال تمثيلي واحد من كل مجموعة، ويتم إنشاء سلسلة منطقية له. تُستخدم الأساليب الاستدلالية البسيطة، مثل تفضيل الأسئلة الأقصر، للحفاظ على جودة الاستدلال.
من خلال التركيز على التنوع والأتمتة، يتيح Auto-CoT إمكانية التوسع في سلسلة الأفكار دون الحاجة إلى أمثلة مصنوعة يدويًا.
اقرأ أيضًا: 17 تقنية تحفيزية لتحسين درجة الماجستير في القانون لديك
خاتمة
يؤدي تحفيز سلسلة الأفكار إلى تغيير كيفية عملنا مع نماذج اللغة الكبيرة من خلال تشجيع التفكير خطوة بخطوة بدلاً من الإجابات التي يتم تقديمها مرة واحدة. وهذا أمر مهم لأنه حتى طلاب الماجستير في القانون الأقوياء غالبًا ما يعانون من المهام التي تتطلب تفكيرًا متعدد الخطوات، على الرغم من امتلاكهم المعرفة اللازمة.
من خلال جعل عملية الاستدلال واضحة، تعمل سلسلة الأفكار على تحسين الأداء بشكل مستمر في مهام مثل الرياضيات والمنطق والاستدلال المنطقي. تعتمد سلسلة التفكير التلقائية على ذلك من خلال تقليل الجهد اليدوي، مما يجعل التفكير المنظم أسهل في القياس.
والخلاصة الأساسية بسيطة: فالاستدلال الأفضل لا يتطلب دائمًا نماذج أكبر أو إعادة تدريب. في كثير من الأحيان، يتعلق الأمر بتحفيز أفضل. تظل سلسلة الأفكار طريقة عملية وفعالة لتحسين الموثوقية في ماجستير إدارة الأعمال الحديثة.
الأسئلة المتداولة
ج: تحفيز سلسلة الأفكار هو أسلوب تطلب فيه من نموذج الذكاء الاصطناعي أن يشرح منطقه خطوة بخطوة قبل إعطاء الإجابة النهائية. وهذا يساعد النموذج على تقسيم المشكلات المعقدة إلى خطوات منطقية أصغر.
ج: في الإجابات بأسلوب TCS، يعني تحفيز سلسلة الأفكار كتابة خطوات وسيطة واضحة لإظهار كيفية الوصول إلى الحل. فهو يركز على التفكير المنطقي والتفسير المنظم والوضوح بدلاً من القفز مباشرة إلى الإجابة النهائية.
ج: يعد تحفيز سلسلة الأفكار فعالاً لأنه يرشد النموذج إلى التفكير خطوة بخطوة. وهذا يقلل من الأخطاء، ويحسن الدقة في المهام المعقدة، ويساعد النموذج على التعامل بشكل أفضل مع مسائل الرياضيات والمنطق والاستدلال متعدد الخطوات.
ج: تُظهر سلسلة الأفكار خطوات التفكير ضمن استجابة واحدة، بينما يؤدي تسلسل المطالبات إلى تقسيم المهمة إلى مطالبات متعددة. يركز CoT على التفكير الداخلي، في حين أن التسلسل الفوري يدير سير العمل عبر استدعاءات النماذج المتعددة.
ج: تتضمن الخطوات الأساسية في سلسلة الأفكار فهم المشكلة، وتقسيمها إلى أجزاء أصغر، والتفكير في كل خطوة بشكل منطقي، ثم دمج تلك الخطوات للوصول إلى إجابة نهائية ومبررة.
ج: يؤدي استخدام CoT إلى تحسين دقة الاستدلال وتقليل الأخطاء المنطقية وجعل استجابات الذكاء الاصطناعي أكثر شفافية. إنه يعمل بشكل جيد بشكل خاص مع المهام المعقدة مثل العمليات الحسابية والألغاز المنطقية ومسائل صنع القرار التي تتطلب خطوات تفكير متعددة.
![]()
هاكر النمو | الذكاء الاصطناعي التوليدي | ماجستير إدارة الأعمال | الخرق | ضبط دقيق | أكثر من 62 ألف متابع https://www.linkedin.com/in/harshit-ahluwalia/ https://www.linkedin.com/in/harshit-ahluwalia/ https://www.linkedin.com/in/harshit-ahluwalia/
قم بتسجيل الدخول لمواصلة القراءة والاستمتاع بالمحتوى الذي ينظمه الخبراء.
Source link