
قام باحث الذكاء الاصطناعي أندريه كارباثي بتطوير أداة تعليمية microGPT والذي يوفر سهولة الوصول إلى تقنية GPT وفقًا لنتائج بحثه. يستخدم المشروع 243 سطرًا من كود Python الذي لا يحتاج إلى أي تبعية خارجية ليُظهر للمستخدمين المبادئ الرياضية الأساسية التي تحكم عمليات نموذج اللغة الكبيرة لأنه يزيل جميع الميزات المعقدة لأنظمة التعلم العميق الحديثة.
دعونا نتعمق في الكود ونكتشف كيف تمكن من تحقيق مثل هذا العمل الفذ الرائع بهذه الطريقة الاقتصادية.
ما الذي يجعل MicroGPT ثوريًا؟
تعتمد معظم دروس GPT اليوم على PyTorch أو TensorFlow أو JAX التي تعمل كأطر عمل قوية، ولكنها تخفي الأسس الرياضية من خلال واجهتها سهلة الاستخدام. يأخذ microGPT الخاص بـ Karpathy النهج المعاكس لأنه يبني جميع وظائفه من خلال وحدات Python المدمجة التي تتضمن أدوات البرمجة الأساسية.
الكود لا يحتوي على ما يلي:
- لا يتضمن الكود PyTorch ولا TensorFlow.
- لا يحتوي الكود على NumPy أو أي مكتبات رقمية أخرى.
- لا يستخدم النظام تسريع GPU أو أي تقنيات تحسين.
- لا يحتوي الكود على أطر عمل مخفية أو أنظمة غير مكشوفة.
يحتوي الكود على ما يلي:
- يستخدم النظام Python الخالص لإنشاء Autograd الذي يقوم بالتمايز التلقائي.
- يشتمل النظام على بنية GPT-2 الكاملة التي تتميز باهتمام متعدد الرؤوس.
- لقد تم تطوير مُحسِّن Adam من خلال المبادئ الأولى.
- يوفر النظام نظام تدريب واستدلال كامل.
- يقوم النظام بإنشاء نص تشغيلي يقوم بإنشاء مخرجات نصية فعلية.
يعمل هذا النظام كنموذج لغوي كامل يستخدم بيانات التدريب الفعلية لإنشاء محتوى مكتوب منطقي. لقد تم تصميم النظام لإعطاء الأولوية للفهم بدلاً من سرعة المعالجة السريعة.
فهم المكونات الأساسية
محرك Autograd: بناء الانتشار العكسي
يعمل التمايز التلقائي باعتباره المكون الأساسي لجميع أطر الشبكات العصبية لأنه يمكّن أجهزة الكمبيوتر من حساب التدرجات تلقائيًا. قام Karpathy بتطوير نسخة أساسية من PyTorch autograd والتي أطلق عليها اسم micrograd والتي تتضمن فئة قيمة واحدة فقط. يستخدم الحساب كائنات القيمة لتتبع كل رقم يتكون من مكونين.
- القيمة الرقمية الفعلية (البيانات)
- التدرج فيما يتعلق بالخسارة (غراد)
- العملية التي أنشأتها (الجمع، الضرب، الخ)
- كيفية الانتشار العكسي من خلال تلك العملية
تقوم كائنات القيمة بإنشاء رسم بياني حسابي عند الاستخدام أ + ب عملية أو أ * ب عملية. يقوم النظام بحساب جميع التدرجات من خلال تطبيق قاعدة السلسلة عند التنفيذ loss.backward() يأمر. يؤدي تطبيق PyTorch هذا وظائفه الأساسية دون أي من إمكانيات التحسين ووحدة معالجة الرسومات.
# Let there be an Autograd to apply the chain rule recursively across a computation graph
class Value:
"""Stores a single scalar value and its gradient, as a node in a computation graph."""
def __init__(self, data, children=(), local_grads=()):
self.data = data # scalar value of this node calculated during forward pass
self.grad = 0 # derivative of the loss w.r.t. this node, calculated in backward pass
self._children = children # children of this node in the computation graph
self._local_grads = local_grads # local derivative of this node w.r.t. its children
def __add__(self, other):
other = other if isinstance(other, Value) else Value(other)
return Value(self.data + other.data, (self, other), (1, 1))
def __mul__(self, other):
other = other if isinstance(other, Value) else Value(other)
return Value(self.data * other.data, (self, other), (other.data, self.data))
def __pow__(self, other):
return Value(self.data**other, (self,), (other * self.data**(other - 1),))
def log(self):
return Value(math.log(self.data), (self,), (1 / self.data,))
def exp(self):
return Value(math.exp(self.data), (self,), (math.exp(self.data),))
def relu(self):
return Value(max(0, self.data), (self,), (float(self.data > 0),))
def __neg__(self):
return self * -1
def __radd__(self, other):
return self + other
def __sub__(self, other):
return self + (-other)
def __rsub__(self, other):
return other + (-self)
def __rmul__(self, other):
return self * other
def __truediv__(self, other):
return self * other**-1
def __rtruediv__(self, other):
return other * self**-1بنية GPT: إزالة الغموض عن المحولات
يطبق النموذج بنية GPT-2 مبسطة مع جميع مكونات المحولات الأساسية:
- يستخدم النظام تضمينات الرمز المميز لإنشاء تمثيلات متجهة تقوم بتعيين كل حرف إلى المتجه المتعلم المقابل له.
- يستخدم النظام التضمين الموضعي لإظهار الموقع الدقيق لكل رمز مميز في التسلسل.
- يمكّن الاهتمام الذاتي متعدد الرؤوس جميع المواضع من عرض المواضع السابقة أثناء دمج تدفقات مختلفة من البيانات.
- تتم معالجة المعلومات التي يتم حضورها من خلال شبكات التغذية الأمامية التي تستخدم التحويلات المستفادة لتحليل البيانات.
يستخدم التنفيذ تنشيط ReLU² (مربع ReLU) بدلاً من GeLU، ويزيل مصطلحات التحيز من النظام بأكمله، مما يجعل فهم الكود أسهل مع الحفاظ على عناصره الأساسية.
def gpt(token_id, pos_id, keys, values):
tok_emb = state_dict('wte')(token_id) # token embedding
pos_emb = state_dict('wpe')(pos_id) # position embedding
x = (t + p for t, p in zip(tok_emb, pos_emb)) # joint token and position embedding
x = rmsnorm(x)
for li in range(n_layer):
# 1) Multi-head attention block
x_residual = x
x = rmsnorm(x)
q = linear(x, state_dict(f'layer{li}.attn_wq'))
k = linear(x, state_dict(f'layer{li}.attn_wk'))
v = linear(x, state_dict(f'layer{li}.attn_wv'))
keys(li).append(k)
values(li).append(v)
x_attn = ()
for h in range(n_head):
hs = h * head_dim
q_h = q(hs:hs + head_dim)
k_h = (ki(hs:hs + head_dim) for ki in keys(li))
v_h = (vi(hs:hs + head_dim) for vi in values(li))
attn_logits = (
sum(q_h(j) * k_h
for t in range(len(k_h))
)
attn_weights = softmax(attn_logits)
head_out = (
sum(attn_weights
for j in range(head_dim)
)
x_attn.extend(head_out)
x = linear(x_attn, state_dict(f'layer{li}.attn_wo'))
x = (a + b for a, b in zip(x, x_residual))
# 2) MLP block
x_residual = x
x = rmsnorm(x)
x = linear(x, state_dict(f'layer{li}.mlp_fc1'))
x = (xi.relu() ** 2 for xi in x)
x = linear(x, state_dict(f'layer{li}.mlp_fc2'))
x = (a + b for a, b in zip(x, x_residual))
logits = linear(x, state_dict('lm_head'))
return logitsحلقة التدريب: التعلم في العمل
عملية التدريب واضحة ومباشرة:
- يقوم الكود بمعالجة كل مستند مجموعة بيانات عن طريق تحويل النص الخاص به أولاً إلى رموز معرف الشخصية.
- يقوم الكود بمعالجة كل مستند عن طريق تحويل النص الخاص به أولاً إلى رموز مميزة لمعرف الحرف ثم إرسال تلك الرموز المميزة من خلال النموذج للمعالجة.
- يقوم النظام باحتساب الخسارة من خلال قدرته على توقع الشخصية القادمة. يقوم النظام بإجراء الانتشار العكسي للحصول على قيم التدرج.
- يستخدم النظام مُحسِّن Adam لتنفيذ تحديثات المعلمات.
يتم تنفيذ مُحسِّن Adam نفسه من الصفر من خلال تصحيح التحيز المناسب وتتبع الزخم. توفر خوارزمية التحسين شفافية كاملة لأن جميع خطواتها مرئية دون أي عمليات مخفية.
# Repeat in sequence
num_steps = 500 # number of training steps
for step in range(num_steps):
# Take single document, tokenize it, surround it with BOS special token on both sides
doc = docs(step % len(docs))
tokens = (BOS) + (uchars.index(ch) for ch in doc) + (BOS)
n = min(block_size, len(tokens) - 1)
# Forward the token sequence through the model, building up the computation graph all the way to the loss.
keys, values = (() for _ in range(n_layer)), (() for _ in range(n_layer))
losses = ()
for pos_id in range(n):
token_id, target_id = tokens(pos_id), tokens(pos_id + 1)
logits = gpt(token_id, pos_id, keys, values)
probs = softmax(logits)
loss_t = -probs(target_id).log()
losses.append(loss_t)
loss = (1 / n) * sum(losses) # final average loss over the document sequence. May yours be low.
# Backward the loss, calculating the gradients with respect to all model parameters.
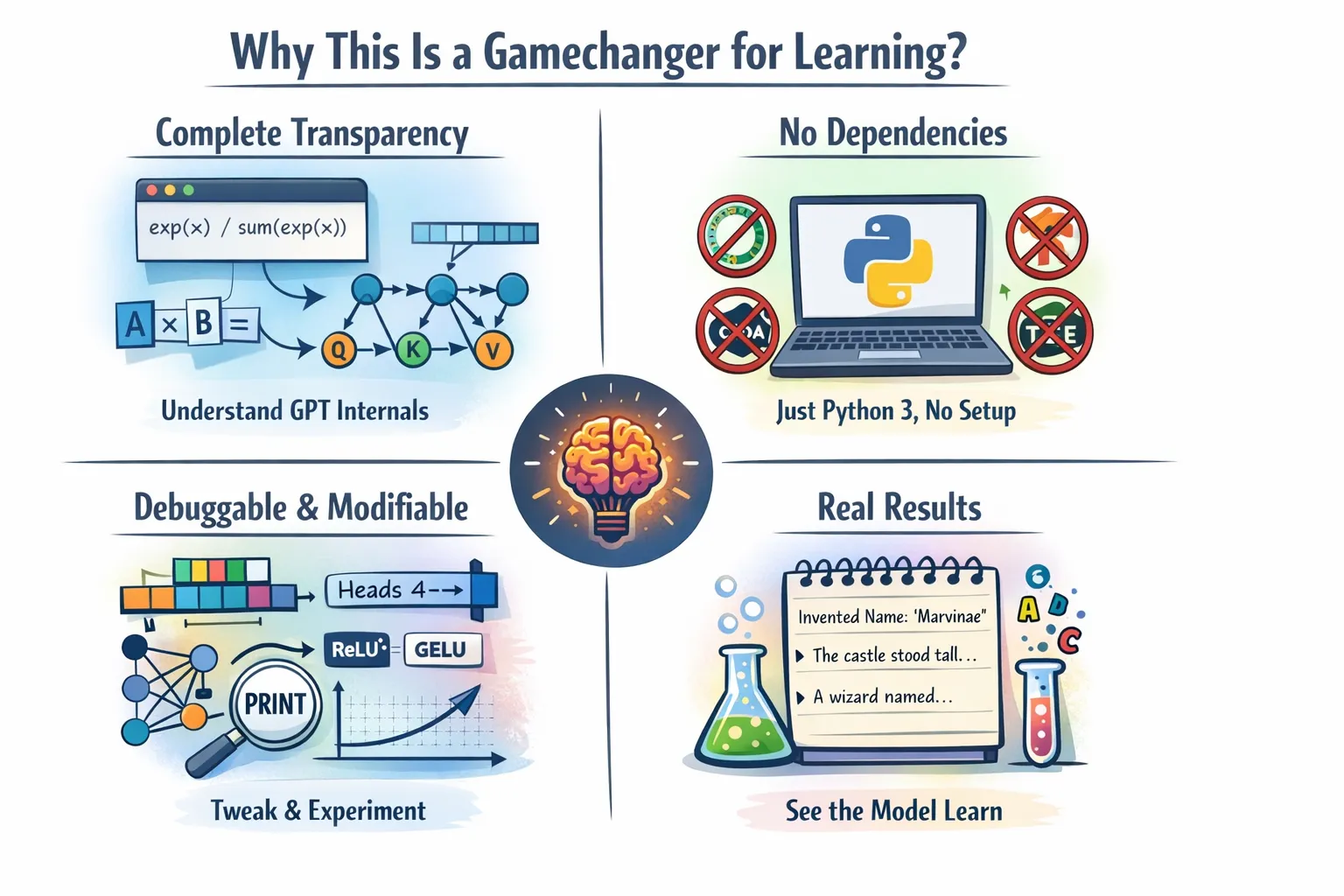
loss.backward()ما الذي يجعل هذا يغير قواعد اللعبة للتعلم؟
يعتبر هذا التنفيذ ذهبًا تربويًا لعدة أسباب:
الشفافية الكاملة
يتم تنفيذ آلاف الأسطر من كود C++ وCUDA المحسّن عند استخدام model.forward() وظيفة في PyTorch. تظهر المجموعة الكاملة من الحسابات الرياضية في كود بايثون الذي يمكنك قراءته. هل تريد أن تعرف بالضبط كيف يعمل softmax؟ كيف يتم حساب درجات الاهتمام؟ كيف تتدفق التدرجات من خلال مضاعفات المصفوفة؟ تظهر كل التفاصيل بطريقة شفافة في الكود.
لا تبعيات، لا متاعب التثبيت
يعمل النظام دون الحاجة إلى أي تبعيات مع تقديم إجراءات التثبيت المباشرة.
لا توجد بيئات كوندا، ولا توجد مجموعة أدوات CUDA، ولا يوجد تعارض في الإصدار. فقط بيثون 3 والفضول. يمكنك إنشاء نظام تدريب GPT فعال عن طريق نسخ الكود في ملف وتشغيله. وهذا يزيل كل حاجز بينك وبين التفاهم.
قابلة للتصحيح والتعديل
يمكنك اختبار النظام عن طريق ضبط عدد مرات الانتباه. تحتاج إلى استبدال ReLU² بوظيفة تنشيط أخرى. يتيح لك النظام إضافة طبقات إضافية. يمكنك النظام من تغيير جدول معدل التعلم من خلال إعداداته. النص بأكمله يمكن قراءته وفهمه من قبل جميع القراء. يمكّنك النظام من وضع بيانات الطباعة في أي مكان خلال البرنامج لمراقبة القيم الدقيقة التي تتدفق عبر الرسم البياني الحسابي.
نتائج حقيقية
إن المحتوى التعليمي لهذه المادة يجعلها مناسبة لأغراض التعلم على الرغم من قصورها الرقابي. يوضح النموذج قدرته على التدريب بنجاح مع إنتاج مخرجات نصية مفهومة. يتعلم النظام كيفية إنشاء أسماء واقعية بعد تدريبه على قاعدة بيانات الأسماء. يستخدم قسم الاستدلال أخذ العينات المستندة إلى درجة الحرارة لإظهار كيفية قيام النموذج بإنشاء محتوى إبداعي.
الشروع في العمل: تشغيل GPT الخاص بك
جمال هذا المشروع هو بساطته. يتطلب المشروع منك تنزيل الكود من مستودع GitHub أو موقع Karpathy وحفظه باسم microgpt.py. يمكنك استخدام الأمر التالي للتنفيذ.
python microgpt.py ويوضح عملية تنزيل بيانات التدريب أثناء تدريب النموذج وإنشاء مخرجات نصية. لا يحتاج النظام إلى بيئات افتراضية ولا إلى عمليات تثبيت النقاط ولا إلى ملفات التكوين. يعمل النظام من خلال لغة Python غير الملوثة التي تؤدي مهام التعلم الآلي غير المغشوشة.
إذا كنت مهتمًا بالكود الكامل، فارجع إلى مستودع Github الخاص بـ Andrej Kaparthy.
الأداء والقيود العملية
يُظهر التنفيذ الحالي تنفيذًا بطيئًا لأن النظام المطبق يستغرق وقتًا طويلاً لإكمال مهامه. تتطلب عملية التدريب على وحدة المعالجة المركزية باستخدام Python النقي ما يلي:
- يقوم النظام بتنفيذ العمليات في وقت واحد
- يقوم النظام بإجراء العمليات الحسابية دون دعم GPU
- يستخدم النظام رياضيات بايثون خالصة بدلاً من المكتبات الرقمية المتقدمة
يتطلب النموذج الذي يتدرب في ثوانٍ باستخدام PyTorch ثلاث ساعات لإكمال عملية التدريب. يعمل النظام بأكمله كبيئة اختبار تفتقر إلى رمز الإنتاج الفعلي.
يعطي الكود التعليمي الأولوية للوضوح لأغراض التعلم بدلاً من تحقيق التنفيذ السريع. إن عملية تعلم قيادة نظام ناقل الحركة اليدوي تصبح مثل تعلم قيادة نظام ناقل حركة أوتوماتيكي. تمكنك هذه العملية من الشعور بكل تغيير في التروس مع اكتساب المعرفة الكاملة حول نظام النقل.
التعمق في الأفكار التجريبية
تتطلب عملية تنفيذ الكود أن تتعلم لغة البرمجة أولاً. تبدأ التجارب بعد تحقيق فهم التعليمات البرمجية:
- تعديل البنية: أضف المزيد من الطبقات، وقم بتغيير أبعاد التضمين، وقم بتجربة رؤوس انتباه مختلفة
- جرب مجموعات بيانات مختلفة: تدرب على مقتطفات التعليمات البرمجية أو كلمات الأغاني أو أي نص يثير اهتمامك
- تنفيذ الميزات الجديدة: أضف التسرب أو جداول معدل التعلم أو خطط التطبيع المختلفة
- تصحيح تدفق التدرج: أضف التسجيل لترى كيف تتغير التدرجات أثناء التدريب
- تحسين الأداء: اختبر النظام باستخدام تطبيق NumPy وتنفيذ التوجيه الأساسي مع الحفاظ على أداء النظام
يتيح هيكل الكود للمستخدمين إجراء التجارب دون صعوبة. ستكشف تجاربك عن المبادئ الأساسية التي تحكم وظائف المحولات.
خاتمة
تطبيق GPT المكون من 243 سطرًا باسم microGPT يعمل هذا البرنامج، الذي طوره Andrej Karpathy، على أنه أكثر من مجرد خوارزمية لأنه يوضح التميز النهائي في البرمجة. يوضح النظام أن فهم المحولات لا يتطلب سوى بضعة أسطر من كود الإطار الأساسي. يوضح النظام أنه يمكن للمستخدمين فهم كيفية عمل الانتباه دون الحاجة إلى أجهزة GPU عالية التكلفة. يحتاج المستخدمون فقط إلى بناء المكونات بشكل أساسي لتطوير نظام نمذجة اللغة الخاص بهم.
إن الجمع بين فضولك وبرمجة Python وقدرتك على فهم 243 سطرًا من التعليمات البرمجية التعليمية يخلق متطلباتك للتعلم الناجح. يعد هذا التنفيذ بمثابة هدية فعلية لثلاث مجموعات مختلفة من الأشخاص: الطلاب والمهندسين والباحثين الذين يرغبون في التعرف على الشبكات العصبية. يوفر لك النظام الرؤية الأكثر دقة لبنية المحولات المتاحة في جميع المواقع.
قم بتنزيل الملف، واقرأ الكود، وقم بإجراء تغييرات أو حتى قم بتفكيك العملية بأكملها وابدأ نسختك الخاصة. سيعلمك النظام كيفية تشغيل GPT من خلال قاعدة كود Python النقية، والتي ستتعلمها سطرًا واحدًا في كل مرة.
الأسئلة المتداولة
ج: إنه تطبيق Python GPT خالص يعرض الرياضيات الأساسية والهندسة المعمارية، مما يساعد المتعلمين على فهم المحولات دون الاعتماد على أطر عمل ثقيلة مثل PyTorch.
ج: يقوم بتطبيق autograd وبنية GPT ومُحسِّن Adam بالكامل في Python، موضحًا كيفية عمل التدريب والانتشار العكسي خطوة بخطوة.
ج: إنه يعمل على لغة Python النقية بدون وحدات معالجة الرسومات أو المكتبات المحسنة، مع إعطاء الأولوية للوضوح والتعليم على السرعة وأداء الإنتاج.
![]()
متدرب في علوم البيانات في Analytics Vidhya
أعمل حاليًا كمتدرب في علوم البيانات في Analytics Vidhya، حيث أركز على بناء حلول تعتمد على البيانات وتطبيق تقنيات الذكاء الاصطناعي/التعلم الآلي لحل مشكلات الأعمال الواقعية. يتيح لي عملي استكشاف التحليلات المتقدمة والتعلم الآلي وتطبيقات الذكاء الاصطناعي التي تمكن المؤسسات من اتخاذ قرارات أكثر ذكاءً وقائمة على الأدلة.
مع أساس قوي في علوم الكمبيوتر، وتطوير البرمجيات، وتحليلات البيانات، أنا متحمس للاستفادة من الذكاء الاصطناعي لإنشاء حلول مؤثرة وقابلة للتطوير تعمل على سد الفجوة بين التكنولوجيا والأعمال.
📩 كما يمكنكم التواصل معي على (البريد الإلكتروني محمي)
قم بتسجيل الدخول لمواصلة القراءة والاستمتاع بالمحتوى الذي ينظمه الخبراء.


