كيف تنظم مشروع علوم البيانات الخاص بك في عام 2026؟

هل شعرت يومًا بالضياع وسط المجلدات الفوضوية والعديد من النصوص البرمجية والتعليمات البرمجية غير المنظمة؟ هذه الفوضى لا تؤدي إلا إلى إبطاءك وتقوية رحلة علم البيانات. إن سير العمل المنظم وهياكل المشاريع ليست مجرد أشياء لطيفة، لأنها تؤثر على إمكانية التكرار والتعاون وفهم ما يحدث في المشروع. في هذه المدونة، سنستكشف أفضل الممارسات بالإضافة إلى إلقاء نظرة على نموذج مشروع لتوجيه مشاريعك القادمة. دون مزيد من اللغط، دعونا نلقي نظرة على بعض الأطر المهمة والممارسات الشائعة وكيفية تحسينها.
أطر سير عمل علوم البيانات الشائعة لهيكل المشروع
توفر أطر علم البيانات طريقة منظمة لتحديد هيكل مشروع واضح لعلم البيانات والحفاظ عليه، وتوجيه الفرق من تعريف المشكلة إلى النشر مع تحسين إمكانية التكرار والتعاون.
كريسب-DM
CRISP-DM هو اختصار للعملية عبر الصناعة لاستخراج البيانات. ويتبع هيكل تكراري دوري بما في ذلك:
- فهم الأعمال
- فهم البيانات
- إعداد البيانات
- النمذجة
- تقييم
- النشر
يمكن استخدام إطار العمل هذا كمعيار عبر مجالات متعددة، على الرغم من أن ترتيب خطواته يمكن أن يكون مرنًا ويمكنك الرجوع للخلف بالإضافة إلى عكس التدفق أحادي الاتجاه. سنلقي نظرة على مشروع يستخدم هذا الإطار لاحقًا في هذه المدونة.
نظام التشغيلهمينيسوتا
إطار شعبي آخر في عالم علم البيانات. الفكرة هنا هي تقسيم المشكلات المعقدة إلى 5 خطوات وحلها خطوة بخطوة، الخطوات الخمس لـ OSEMN (تنطق رائعة) هي:
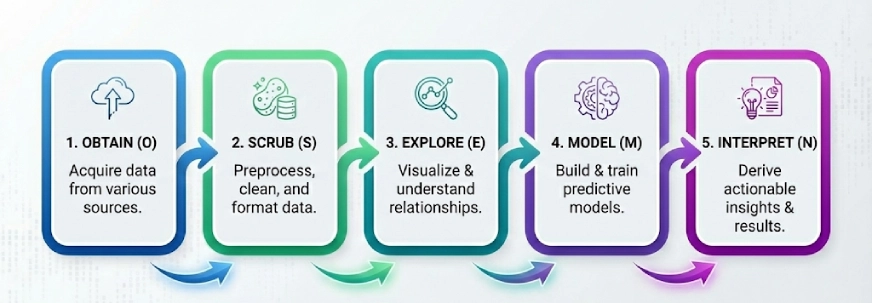
- يحصل على
- فرك
- يستكشف
- نموذج
- يفسر
ملحوظة: الحرف “N” في “OSEMN” هو الحرف N في iNterpret.
نحن نتبع هذه الخطوات المنطقية الخمس “للحصول على” البيانات، أو “تنقيتها” أو معالجتها مسبقًا، ثم “استكشافها” باستخدام التمثيلات المرئية وفهم العلاقات بين البيانات، ثم نقوم “بنمذجة” البيانات لاستخدام المدخلات للتنبؤ بالمخرجات. وأخيرًا، نقوم “بتفسير” النتائج وإيجاد رؤى قابلة للتنفيذ.
كي دي دي
يتكون KDD أو اكتشاف المعرفة في قواعد البيانات من عمليات متعددة تهدف إلى تحويل البيانات الأولية إلى اكتشاف المعرفة. فيما يلي الخطوات في هذا الإطار:

- اختيار
- المعالجة المسبقة
- تحويل
- استخراج البيانات
- التفسير/التقييم
من الجدير بالذكر أن الأشخاص يشيرون إلى KDD باسم “استخراج البيانات”، لكن “استخراج البيانات” هو الخطوة المحددة حيث يتم استخدام الخوارزميات للعثور على الأنماط. حيث أن KDD يغطي دورة الحياة بأكملها من البداية إلى النهاية.
مذكور
يركز هذا الإطار أكثر على تطوير النموذج. يأتي SEMMA من الخطوات المنطقية في الإطار وهي:
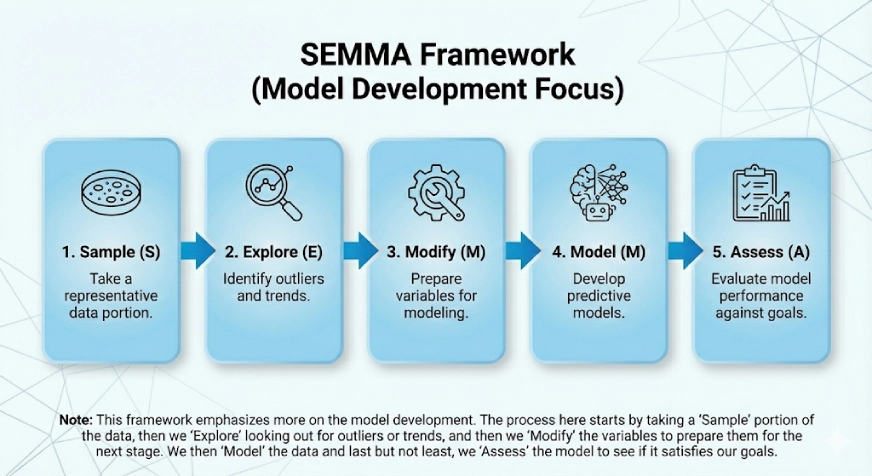
- عينة
- يستكشف
- يُعدِّل
- نموذج
- يٌقيِّم
تبدأ العملية هنا بأخذ جزء “عينة” من البيانات، ثم “استكشاف” البحث عن القيم المتطرفة أو الاتجاهات، ثم “تعديل” المتغيرات لإعدادها للمرحلة التالية. نقوم بعد ذلك “بنمذجة” البيانات وأخيرًا وليس آخرًا، نقوم “بتقييم” النموذج لمعرفة ما إذا كان يلبي أهدافنا.
الممارسات الشائعة التي تحتاج إلى تحسين
يعد تحسين هذه الممارسات أمرًا بالغ الأهمية للحفاظ على بنية مشروع علوم البيانات نظيفة وقابلة للتطوير، خاصة مع نمو المشاريع من حيث الحجم والتعقيد.
1. مشكلة “المسارات”
غالبًا ما يقوم الأشخاص بترميز المسارات المطلقة مثل pd.read_csv(“C:/Users/Name/Downloads/data.csv”). يعد هذا أمرًا جيدًا أثناء اختبار الأشياء على Jupyter Notebook، ولكن عند استخدامه في المشروع الفعلي، فإنه يكسر الكود لأي شخص آخر.
الإصلاح: استخدم دائمًا المسارات النسبية بمساعدة المكتبات مثل “os” أو “pathlib”. وبدلاً من ذلك، يمكنك اختيار إضافة المسارات في ملف التكوين (على سبيل المثال: DATA_DIR=/home/ubuntu/path).
2. دفتر جوبيتر المزدحم
في بعض الأحيان يستخدم الأشخاص دفتر Jupyter Notebook واحدًا يحتوي على أكثر من 100 خلية تحتوي على الواردات وEDA والتنظيف والنمذجة والتصور. وهذا من شأنه أن يجعل من المستحيل اختبار أو التحكم في الإصدار.
الإصلاح: استخدم Jupyter Notebooks للاستكشاف فقط والتزم بنصوص Python للأتمتة. بمجرد أن تعمل وظيفة التنظيف، قم بإضافتها إلى ملف src/processing.py ومن ثم يمكنك استيرادها إلى دفتر الملاحظات. وهذا يضيف نمطية وإمكانية إعادة الاستخدام ويجعل أيضًا اختبار الكمبيوتر الدفتري وفهمه أسهل كثيرًا.
3. قم بإصدار الكود وليس البيانات
يمكن أن يواجه Git صعوبة في التعامل مع ملفات CSV الكبيرة. غالبًا ما يقوم الأشخاص بدفع البيانات إلى GitHub، الأمر الذي قد يستغرق الكثير من الوقت ويسبب أيضًا مضاعفات أخرى.
الإصلاح: اذكر واستخدم التحكم في إصدار البيانات (DVC باختصار). إنه مثل Git ولكن للبيانات.
4. عدم توفير الملف التمهيدي للمشروع
يمكن أن يحتوي المستودع على تعليمات برمجية رائعة ولكن بدون تعليمات حول كيفية تثبيت التبعيات أو تشغيل البرامج النصية يمكن أن يكون فوضويًا.
الإصلاح: تأكد من أنك تقوم دائمًا بصياغة ملف README.md جيد يحتوي على معلومات حول كيفية إعداد البيئة، وأين وكيفية الحصول على البيانات، وكيفية تشغيل النموذج والبرامج النصية المهمة الأخرى.
بناء نظام للتنبؤ بتقلبات العملاء (مشروع نموذجي)
الآن باستخدام إطار عمل CRISP-DM، قمت بإنشاء نموذج لمشروع يسمى “نظام التنبؤ باضطراب العملاء”، فلنفهم العملية برمتها والخطوات من خلال إلقاء نظرة أفضل عليها.
إليك رابط GitHub للمستودع.
ملحوظة: هذا مشروع نموذجي وتم تصميمه لفهم كيفية تنفيذ إطار العمل واتباع الإجراء القياسي.
تطبيق CRISP-DM خطوة بخطوة
- فهم الأعمال: هنا علينا أن نحدد ما نحاول حله بالفعل. في حالتنا، يتم تحديد العملاء الذين من المحتمل أن يتراجعوا عن العمل. لقد وضعنا أهدافًا واضحة للنظام، وهي الدقة بنسبة 85%+ والتذكر بنسبة 80%+، وهدف العمل هنا هو الاحتفاظ بالعملاء.
- فهم البيانات في حالتنا، مجموعة بيانات Telco Customer Churn. علينا أن ننظر إلى الإحصائيات الوصفية، ونتحقق من جودة البيانات، ونبحث عن القيم المفقودة (نفكر أيضًا في كيفية التعامل معها)، وعلينا أيضًا أن نرى كيفية توزيع المتغير المستهدف، وأخيرًا نحتاج أيضًا إلى استكشاف الارتباطات بين المتغيرات لمعرفة الميزات المهمة.
- إعداد البيانات: قد تستغرق هذه الخطوة بعض الوقت ولكن يجب تنفيذها بعناية. نقوم هنا بتطهير البيانات الفوضوية، والتعامل مع القيم المفقودة والقيم المتطرفة، وإنشاء ميزات جديدة إذا لزم الأمر، وترميز المتغيرات الفئوية، وتقسيم مجموعة البيانات إلى تدريب (70%)، والتحقق (15%)، والاختبار (15%)، وأخيرًا تطبيع الميزات لنماذجنا.
- النمذجة: في هذه الخطوة الحاسمة، نبدأ بنموذج بسيط أو خط أساسي (الانحدار اللوجستي في حالتنا)، ثم نجرب نماذج أخرى مثل Random Forest وXGBoost لتحقيق أهداف أعمالنا. نقوم بعد ذلك بضبط المعلمات الفائقة.
- تقييم: هنا نكتشف النموذج الذي يعمل بشكل أفضل بالنسبة لنا ويلبي أهداف أعمالنا. في حالتنا نحن بحاجة إلى إلقاء نظرة على الدقة، والاستدعاء، ودرجات F1، ومنحنيات ROC-AUC ومصفوفة الارتباك. تساعدنا هذه الخطوة في اختيار النموذج النهائي لهدفنا.
- النشر: هذا هو المكان الذي نبدأ فيه فعليًا باستخدام النموذج. يمكننا هنا استخدام FastAPI أو أي بدائل أخرى، ووضعها في حاوية مع Docker من أجل قابلية التوسع، ومراقبة الإعداد لأغراض التتبع.
من الواضح أن استخدام عملية خطوة بخطوة يساعد في توفير مسار واضح للمشروع، وأيضًا أثناء تطوير المشروع، يمكنك الاستفادة من أدوات تتبع التقدم ويمكن أن تساعد عناصر التحكم في إصدار GitHub بالتأكيد. يحتاج إعداد البيانات إلى رعاية معقدة لأنه لن يحتاج إلى العديد من المراجعات إذا تم إجراؤه بشكل صحيح، وإذا ظهرت أي مشكلة بعد النشر، فيمكن إصلاحها من خلال العودة إلى مرحلة النمذجة.
خاتمة
كما ذكرنا في بداية المدونة، فإن سير العمل وهياكل المشروعات المنظمة ليست أمرًا رائعًا فحسب، بل إنها ضرورية. باستخدام CRISP-DM، أو OSEMN، أو KDD، أو SEMMA، تحافظ العملية خطوة بخطوة على وضوح المشروعات وقابليتها للتكرار. لا تنس أيضًا استخدام المسارات النسبية، والاحتفاظ بدفاتر Jupyter للاستكشاف، وصياغة ملف README.md جيد دائمًا. تذكر دائمًا أن التطوير هو عملية متكررة وأن وجود إطار منظم واضح لمشاريعك سيسهل رحلتك.
الأسئلة المتداولة
أ. تعني إمكانية التكرار في علم البيانات القدرة على الحصول على نفس النتائج باستخدام نفس مجموعة البيانات والتعليمات البرمجية وإعدادات التكوين. يضمن المشروع القابل للتكرار إمكانية التحقق من التجارب وتصحيح أخطائها وتحسينها بمرور الوقت. كما أنه يجعل التعاون أسهل، حيث يمكن لأعضاء الفريق الآخرين تشغيل المشروع دون أي تناقضات ناجمة عن البيئة أو اختلافات البيانات.
أ. يحدث انحراف النموذج عندما يتدهور أداء نموذج التعلم الآلي بسبب تغير بيانات العالم الحقيقي بمرور الوقت. يمكن أن يحدث هذا بسبب التغيرات في سلوك المستخدم أو ظروف السوق أو توزيع البيانات. تعد مراقبة انحراف النماذج أمرًا ضروريًا في أنظمة الإنتاج لضمان بقاء النماذج دقيقة وموثوقة ومتوافقة مع أهداف العمل.
أ. تعمل البيئة الافتراضية على عزل تبعيات المشروع وتمنع التعارضات بين إصدارات المكتبة المختلفة. نظرًا لأن مشاريع علوم البيانات تعتمد غالبًا على إصدارات محددة من حزم Python، فإن استخدام البيئات الافتراضية يضمن نتائج متسقة عبر الأجهزة وبمرور الوقت. يعد هذا أمرًا بالغ الأهمية لإمكانية التكرار والنشر والتعاون في سير عمل علوم البيانات في العالم الحقيقي.
أ. مسار البيانات عبارة عن سلسلة من الخطوات التلقائية التي تنقل البيانات من المصادر الأولية إلى تنسيق جاهز للنموذج. يتضمن عادةً استيعاب البيانات وتنظيفها وتحويلها وتخزينها.
![]()
شغوف بالتكنولوجيا والابتكار، خريج معهد فيلور للتكنولوجيا. أعمل حاليًا كمتدرب في علوم البيانات، مع التركيز على علوم البيانات. مهتم بشدة بالتعلم العميق والذكاء الاصطناعي التوليدي، ومتلهف لاستكشاف التقنيات المتطورة لحل المشكلات المعقدة وإنشاء حلول مؤثرة.
قم بتسجيل الدخول لمواصلة القراءة والاستمتاع بالمحتوى الذي ينظمه الخبراء.
Source link