دليل لخط أنابيب RAG الآلي

أصبح الجيل المعزز للاسترجاع (RAG) هو الأسلوب الأمثل لبناء تطبيقات ذكاء اصطناعي موثوقة تعتمد على البيانات الخارجية، لأنه يساعد في التغلب على قيود LLM، ويقلل من الهلوسة، ويقدم استجابات على مستوى الخبراء ترتكز على مصادر موثوقة. مع تزايد الاهتمام بـ RAG، تزداد الحاجة إلى الأدوات التي تسهل استكشاف استراتيجيات RAG المختلفة واختبارها وتحسينها. يعد AutoRAG أحد الحلول الأحدث المصممة لهذا الغرض، حيث يعمل على أتمتة جزء كبير من سير عمل التطوير حتى تتمكن من تجربة التكوينات وتقييم خطوط الأنابيب وتحديد ما هو الأفضل لحالة الاستخدام الخاصة بك.
سنغطي في هذا الدليل كيفية عمل AutoRAG، وكيفية إنشاء تطبيق RAG شامل باستخدام هذه التقنية.
ما هو جيل الاسترجاع المعزز (RAG)؟
القطعتان الرئيسيتان من RAG هما المسترد والمولد. تشكل هذه القطع معًا خط أنابيب RAG الذي يسمح لك بالحصول على إجابات دقيقة للاستفسارات المعقدة. سوف يقرأ المولد السياق الذي وجده المسترد ويولد استجابة بناءً على ذلك.
RAG هو أسلوب يجمع بين عمليات البحث عن البيانات الخارجية والنماذج التوليدية لتحسين الدقة من خلال توفير مراجع موثوقة للإجابات التي تم إنشاؤها بواسطة النموذج. تتضمن بعض تطبيقات RAG روبوتات الدردشة ومساعدي المعرفة وحلول التحليلات وأنظمة الأسئلة والأجوبة الخاصة بالمؤسسات.
المكونات الرئيسية لـ RAG
هناك العديد من العناصر الأساسية التي تجعل RAG ناجحًا وتؤثر على قدرة RAG على توفير معلومات دقيقة. وتشمل هذه المسترد، ونموذج التضمين، والمولد.
- المسترد: الخطوة الأولى في RAG هي فهرسة المستندات باستخدام المسترد، ثم سيقوم المسترد بالبحث في الفهرس عن أجزاء المستندات ذات الصلة. طريقة البحث في
- نموذج التضمين: يمكن أن تعتمد الفهارس على تشابه أجزاء المستندات من خلال طرق مختلفة مثل بحث التشابه أو تضمين المتجهات أو الاسترجاع المختلط.
- مولد (ماجستير): يجب أن يعتمد المولد على سياق دقيق من أجل إنتاج استجابة دقيقة. ولهذا السبب من الضروري استخدام أفضل نسخة ممكنة من السياق من أجل توليد استجابة دقيقة.
ما هو AutoRAG ومتى يتم استخدامه
AutoRAG هو إطار عمل يسمح لك بإنشاء خطوط أنابيب RAG المتعددة وتقييمها وتحسينها بسرعة. فهو يساعد المطورين على اختبار خيارات التصميم المتعددة بسرعة دون الحاجة إلى كتابة نصوص تقييم مخصصة. عندما ترغب الفرق في مقارنة طرق الاسترجاع المختلفة، أو نماذج التضمين، أو استراتيجيات التقطيع، أو الأجيال، فإنها تستخدم AutoRAG.
باستخدام AutoRAG، يمكن للمطورين التكرار بسرعة من خلال العديد من تكوينات RAG المختلفة لأنه يقوم تلقائيًا بتشغيل الاختبارات ويوفر تقييمًا لدقة الاسترجاع وأفضل تكوين لإنشاء خطوط الأنابيب. عندما تحتاج إلى تقييم منهجي أو ترغب في اختبار عدد كبير من تكوينات خطوط الأنابيب، يجب عليك استخدام AutoRAG.
ما هي المشاكل التي يحلها AutoRAG؟
يعالج AutoRAG العديد من التحديات التي تجعل تطوير RAG يستغرق وقتًا طويلاً. ومع تزايد تعقيد مشاريع RAG، أصبحت هذه التحديات أكثر أهمية.
- استكشاف خطوط الأنابيب: فهو يتيح إجراء التجارب عبر مجموعة متنوعة من مقاييس التشابه وأحجام القطع ونماذج التضمين والمستردات بدون تعليمات برمجية يدوية.
- تقييم: يتضمن AutoRAG مقاييس التقييم التي تتضمن دقة الاسترجاع، وصحة الاقتباس، وجودة الإجابة، مما يجعل من السهل تقييم فعالية مسارات RAG.
- تحسين: يحدد AutoRAG التكوينات الأكثر فعالية، والتي تمكن الفرق من اتخاذ أفضل قرار ممكن لتكوين بياناتهم وحالة الاستخدام.
التحضير للبناء: المتطلبات الأساسية والإعداد
قم بإعداد بيئة تطوير مناسبة لاستخدام AutoRAG لتطوير تطبيق يعتمد على RAG. هذا يعني أنك ستحتاج إلى إنشاء Python والتبعيات والبيانات ومعرفة بيانات الاعتماد التي تحتاجها من LLM أو موفر نموذج التضمين.
يجب أن يكون لديك بيئة Python محددة جيدًا بالإضافة إلى العديد من التبعيات الإضافية لتتمكن من تشغيل AutoRAG بنجاح. إذا كانت لديك بيئة غير نظيفة أو غير محددة بشكل صحيح، فقد تواجه تعارضات داخل تبعياتك، ولن تعمل تجاربك مع RAG بسلاسة.
- إعداد بايثون
python3 -m venv autorag-venv
source autorag-venv/bin/activate
python -m pip install --upgrade pip- بايثون 3.10 أو أعلى
- بيئة افتراضية باستخدام venv أو conda
- نقطة لتثبيت الحزمة
- التبعيات الأساسية
قم بتثبيت الحزم التالية كما هو مطلوب بواسطة AutoRAG:
pip install AutoRAG pandas langchain sentence-transformers faiss-cpu - autorag
- الباندا
- محولات الجملة
- Faiss-CPU أو واجهة خلفية أخرى لمتجر متجه
- langchain أو langchain-community لتكاملات LLM
- تصدير LLM / مفاتيح التضمين
export OPENAI_API_KEY="sk-..." إذا كنت تستخدم موفري خدمات آخرين، فقم بتعيينهم env فار بالمثل.
بناء تطبيق RAG باستخدام AutoRAG
لإنشاء تطبيق يعتمد على RAG باستخدام AutoRAG وقاعدة المعرفة، اتبع الخطوات الرئيسية التالية.
- الفهرسة والتضمين: سيتم تحويل كل جزء من المعلومات إلى تضمين وتخزينه في قاعدة بيانات متجهة.
- الاسترجاع وتجربة خطوط الأنابيب: قم بإنشاء مجموعة تقييم ضمان الجودة إذا لزم الأمر، ثم قم بتشغيل AutoRAG لتجربة خطوط أنابيب RAG المختلفة لتحديد أي منها ينتج أفضل النتائج.
- النشر: استخدم خط أنابيب RAG الناتج للرد على استفسارات المستخدم.
استيعاب البيانات والمعالجة المسبقة
أولاً، سنقوم بتحميل المستندات الأولية:
import json
import os
from pathlib import Path
import PyPDF2
def parse_pdf(pdf_path="data/raw_docs/attention.pdf", out_path="data/parsed.jsonl"):
os.makedirs("data", exist_ok=True)
with open(pdf_path, "rb") as f, open(out_path, "w", encoding="utf-8") as fout:
reader = PyPDF2.PdfReader(f)
for i, page in enumerate(reader.pages):
text = page.extract_text() or ""
fout.write(json.dumps({
"doc_id": "attention.pdf",
"page": i + 1,
"content": text,
"source": "attention.pdf",
"title": "Attention Is All You Need"
}) + "\n")
print("Parsed PDF → data/parsed.jsonl")
parse_pdf()سيتم استخدام الطريقة التالية لتقسيم المستندات وتقطيعها:
import json
def chunk_text(text, chunk_size=600, overlap=60):
words = text.split()
i = 0
chunks = ()
while i < len(words):
chunk = words(i:i + chunk_size)
chunks.append(" ".join(chunk))
if i + chunk_size >= len(words):
break
i += chunk_size - overlap
return chunks
def create_corpus(parsed="data/parsed.jsonl", out="data/corpus.jsonl"):
with open(parsed, "r") as fin, open(out, "w") as fout:
for line in fin:
row = json.loads(line)
chs = chunk_text(row("content"))
for idx, c in enumerate(chs):
fout.write(json.dumps({
"id": f"{row('doc_id')}_p{row('page')}_c{idx}",
"doc_id": row("doc_id"),
"page": row("page"),
"chunk_id": idx,
"content": c,
"source": row("source"),
"title": row("title")
}) + "\n")
print("Created corpus → data/corpus.jsonl")
create_corpus()التعليمة البرمجية التالية تطبيع البيانات التعريفية:
import json
def normalize_metadata(path="data/corpus.jsonl"):
rows = ()
with open(path) as fin:
for line in fin:
obj = json.loads(line)
obj.setdefault("source", "attention.pdf")
obj.setdefault("title", "Attention Is All You Need")
rows.append(obj)
with open(path, "w") as fout:
for r in rows:
fout.write(json.dumps(r) + "\n")
print("Metadata normalized.")
normalize_metadata()الفهرسة / التضمين + إعداد التخزين
الآن، سنستخدم نموذج التضمين:
import json
import numpy as np
import faiss
from sentence_transformers import SentenceTransformer
import os
def build_faiss_index(corpus="data/corpus.jsonl", index_dir="data/faiss_index"):
os.makedirs(index_dir, exist_ok=True)
texts, ids = (), ()
with open(corpus) as f:
for line in f:
row = json.loads(line)
texts.append(row("content"))
ids.append(row("id"))
model = SentenceTransformer("all-MiniLM-L6-v2")
embeddings = model.encode(texts, convert_to_numpy=True)
faiss.normalize_L2(embeddings)
index = faiss.IndexFlatIP(embeddings.shape(1))
index.add(embeddings)
faiss.write_index(index, f"{index_dir}/index.faiss")
json.dump(ids, open(f"{index_dir}/ids.json", "w"))
print("Stored FAISS index at", index_dir)
build_faiss_index()تخزين المتجهات أو إعداد قاعدة البيانات:
vectordb: faiss_local
index_dir: data/faiss_index
embedding_module: sentence_transformers/all-MiniLM-L6-v2الاسترجاع وتجربة خط أنابيب RAG باستخدام AutoRAG
أولاً، سنقوم بإنشاء مجموعة بيانات تقييم ضمان الجودة:
import pandas as pd
from autorag.data.qa.schema import Raw, Corpus
from autorag.data.qa.sample import random_single_hop
from autorag.data.qa.query.llama_gen_query import factoid_query_gen
from autorag.data.qa.generation_gt.llama_index_gen_gt import make_basic_gen_gt
from llama_index.llms.openai import OpenAI
def create_qa():
raw_df = pd.read_parquet("data/parsed.parquet")
corpus_df = pd.read_parquet("data/corpus.parquet")
raw_inst = Raw(raw_df)
corpus_inst = Corpus(corpus_df, raw_inst)
llm = OpenAI()
sampled = corpus_inst.sample(random_single_hop, n=140)
sampled = sampled.make_retrieval_gt_contents()
sampled = sampled.batch_apply(factoid_query_gen, llm=llm)
sampled = sampled.batch_apply(make_basic_gen_gt, llm=llm)
sampled.to_parquet("data/qa.parquet", index=False)
print("Created data/qa.parquet")
create_qa()تشغيل تقييم AutoRAG:
التكوينات/default_rag_config.yaml
node_lines:
- node_line_name: retrieve_node_line
nodes:
- node_type: semantic_retrieval
top_k: 3
modules:
- module_type: vectordb
vectordb: faiss_local
index_dir: data/faiss_index
embedding_module: sentence_transformers/all-MiniLM-L6-v2
- node_line_name: post_retrieve_node_line
nodes:
- node_type: prompt_maker
modules:
- module_type: fstring
prompt: |
Use the passages to answer the question.
Question: {query}
Passages: {retrieved_contents}
Answer:
- node_type: generator
modules:
- module_type: openai_llm
llm: gpt-4o-mini
batch: 8استخدم الكود التالي لتشغيل المقيم:
from autorag.evaluator import Evaluator
evaluator = Evaluator(
qa_data_path="data/qa.parquet",
corpus_data_path="data/corpus.parquet"
)
evaluator.start_trial("configs/default_rag_config.yaml")تشغيل RAG:
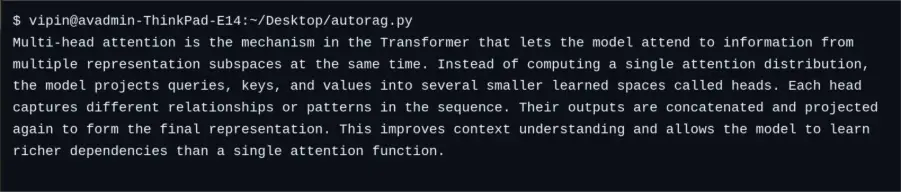
استعلام المستخدم: “ما هو الاهتمام متعدد الرؤوس في نموذج المحولات؟”
أفضل الممارسات والتوصيات
يتطلب إنشاء تطبيق RAG قوي تخطيطًا دقيقًا. فيما يلي بعض أفضل الممارسات:
- احتفظ بالنص الأصلي مع التضمينات: يجب عليك دائمًا الاحتفاظ بمحتوى inode لأي جزء أو إشارة إلى محتوى inode جنبًا إلى جنب مع التضمينات الخاصة بمقطع المحتوى هذا – لا تعتمد فقط على التضمينات.
- قطعة بشكل معقول: يتم التقطيع بطريقة تحافظ على المعنى عند حدود القطع عند معالجتها؛ لذلك، يجب عليك استخدام نفس الرمز المميز ونفس الحجم لجميع أجزاء المحتوى (على سبيل المثال، 300 إلى 512 رمزًا مميزًا) والحفاظ على تداخل القطع (على سبيل المثال، 50 رمزًا متداخلاً).
- تضمينات ذاكرة التخزين المؤقت: قم بتخزين عمليات التضمين المتماثلة لكل المحتوى مؤقتًا عند إرسال استعلام متكرر أو عند معالجة كميات كبيرة من المحتوى.
- مراقبة الجودة: مراقبة أداء الاسترجاع والتوليد باستخدام المقاييس القياسية؛ على سبيل المثال: يوفر AutoRAG مقاييس قياسية لتقييم الاسترجاع F1 والاستدعاء والإجابة الصحيحة؛ يمكنك استخدام هذه المقاييس لتحديد أي مشاكل تتعلق بأداء نظام RAG الخاص بك.
- قم بتأمين مفاتيحك: حماية مفاتيح API الخاصة بك أو الرموز المميزة للنموذج؛ لا تقم بترميز المفاتيح الخاصة بك في التطبيق الخاص بك؛ بدلاً من ذلك، استخدم متغيرات البيئة أو الخزائن الآمنة.
باتباع الإرشادات المذكورة أعلاه، ستكون فرق التطوير قادرة على إنشاء تطبيقات RAG قوية وموثوقة تستفيد من أتمتة AutoRAG وتحقق نتائج عالية الجودة.
خاتمة
يتكون تصميم تطبيق RAG من مكونات متعددة بين تقنيات معالجة البيانات واسترجاعها. يمكّن AutoRAG المطورين من أتمتة المرحلة التجريبية وعمليات التقييم لتسهيل إنشاء تطبيقات RAG. باستخدام AutoRAG، يمكن للمطورين تجربة تصميمات خطوط الأنابيب المختلفة بسرعة وإطلاق تطبيق RAG فائق الجودة استنادًا إلى بيانات قاطعة.
باتباع الإرشادات الواردة في هذه الوثيقة، سيتمكن المستخدمون من إنتاج تطبيق يمكن الاعتماد عليه ودقيق وجاهز للاستخدام مع تنفيذ الأساليب المثلى. باستخدام قدرات التحسين الخاصة بـ AutoRAG ودمج أفضل الممارسات الراسخة، تتمتع الفرق بفرصة أكبر لإنشاء تجربة الذكاء الاصطناعي الأكثر فائدة مع تقليل الحاجة إلى التكوين اليدوي الذي يستغرق وقتًا طويلاً.
الأسئلة المتداولة
A. يقوم AutoRAG بأتمتة استكشاف خطوط أنابيب RAG وتقييمها وتحسينها. فهو يساعد المطورين على تحديد أفضل تكوين لمهام الاسترجاع والإنشاء.
ج: لا، يعمل AutoRAG مع مجموعات البيانات الصغيرة والكبيرة. ومع ذلك، يؤدي المزيد من البيانات إلى تحسين دقة التقييم وأداء الاسترجاع.
ج: يعتمد الاختيار على حالة الاستخدام الخاصة بك. توفر النماذج خفيفة الوزن مثل MiniLM السرعة، بينما توفر النماذج مثل BGE أو Jina دقة دلالية أعلى.
![]()
مرحبًا! أنا Vipin، متحمس لعلم البيانات والتعلم الآلي ولدي أساس قوي في تحليل البيانات وخوارزميات التعلم الآلي والبرمجة. لدي خبرة عملية في بناء النماذج وإدارة البيانات الفوضوية وحل مشكلات العالم الحقيقي. هدفي هو تطبيق الرؤى المستندة إلى البيانات لإنشاء حلول عملية تؤدي إلى تحقيق النتائج. أنا حريص على المساهمة بمهاراتي في بيئة تعاونية مع الاستمرار في التعلم والنمو في مجالات علوم البيانات والتعلم الآلي والبرمجة اللغوية العصبية.
قم بتسجيل الدخول لمواصلة القراءة والاستمتاع بالمحتوى الذي ينظمه الخبراء.
Source link