تشغيل نماذج الذكاء الاصطناعي الكبيرة على أجهزة محدودة

لقد قمت للتو بتنزيل أحدث نموذج معلمة 4 مليار. لقد ضربت’يجري‘. بعد فترة من الوقت، يتعطل مثيل Google Colab. يبدو مألوفا؟ حسنًا، لا بد أن يحدث هذا إذا لم ننتبه إلى VRAM المطلوبة وما هي VRAM التي نقدمها للنموذج. التكميم هو شيء يمكن أن يساعدك في معالجة هذه المشكلة، وهذا هو بالضبط ما سنغطيه في هذه المدونة؛ سوف نتعلم أيضًا كيفية حساب متطلبات VRAM للنموذج، والتعرف على تقنيات التكميم المتعددة والبدائل للتعامل مع هذه النماذج اللغوية الكبيرة حقًا.
المعلمات مقابل حجم النموذج
يعد عدد المعلمات ضروريًا لقياس أثر النموذج ولكن يجب ألا ننسى دقة أوزان النموذج (ملحوظة: أوزان النموذج هي المعلمات). هناك طريقة بسيطة لتقدير VRAM للنموذج وهي {No. المعلمات × الدقة (بالبايت)}.
مثال: إذا كان لدينا نموذج بمعلمات 300 مليون وتم تخزين الأوزان بدقة 32 بت. هذا يعني أن هناك (300 × 10^6) * (4 بايت) = 1.2 جيجابايت. لذلك سيحتاج هذا الطراز تقريبًا إلى 1.5 جيجابايت من VRAM.
ملحوظة: 1 بايت = 8 بت
ما هو نموذج التكميم؟
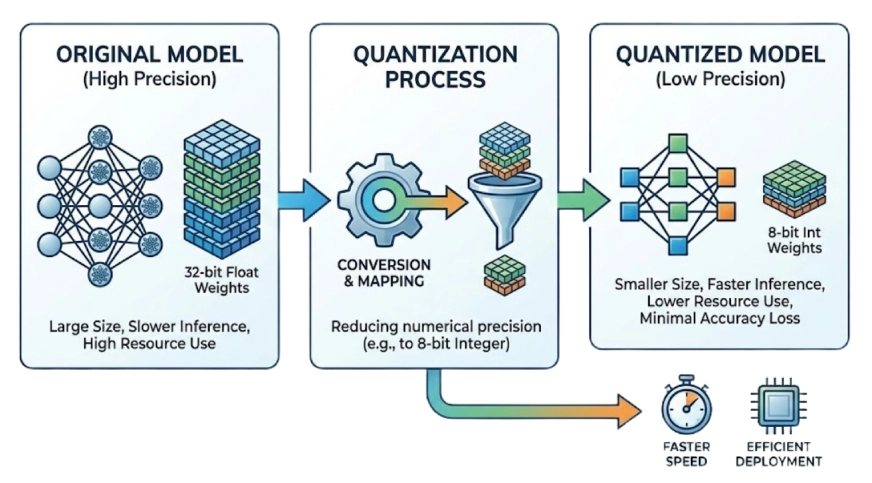
يقلل التكميم من دقة أوزان النموذج بينما يهدف إلى الحفاظ على الأداء كما هو تقريبًا. يمكن أن يؤدي هذا عادةً إلى تقليص حجم النموذج بمقدار 2× أو أكثر. بالطبع يتأثر أداء النموذج ولكن ليس كثيرًا إذا قمنا بالتكميم الصحيح واختبرنا النتائج.
على سبيل المثال: الأرقام عالية الدقة (مثل الأعداد الصحيحة ذات 32 بت) إلى المجموعات ذات الدقة الأقل (مثل الأعداد الصحيحة ذات 4 بت).
- نصف الدقة (BF16/FP16): يقلل الذاكرة بنسبة 50% مع فقدان ما يقرب من الصفر في الدقة.
- التكميم العميق (INT8/INT4): تخفيضات 75% أو أكثر. هذه هي الطريقة التي يمكننا من خلالها ملاءمة النماذج الكبيرة مع الأجهزة الاستهلاكية.
نموذج التكميم في العمل
في هذا القسم، نهدف إلى إجراء عملية التكميم بمساعدة PyTorch باستخدام مثيل Google Colab. سنقوم بإجراء الاستدلال باستخدام Mistral-3 (14B) عن طريق تحديد كمية النموذج وتحميله من خلال محولات HuggingFace.
ملحوظة: يحتاج هذا النموذج إلى 14 × 10
المتطلبات المسبقة
- سنطلب المساعدة من Hugging Face وGoogle colab في هذا العرض التوضيحي. وسوف نستخدم نموذج Gemma-3 وهو نموذج مسور. تأكد من حصولك على الإذن من هنا بعد تسجيل الدخول.
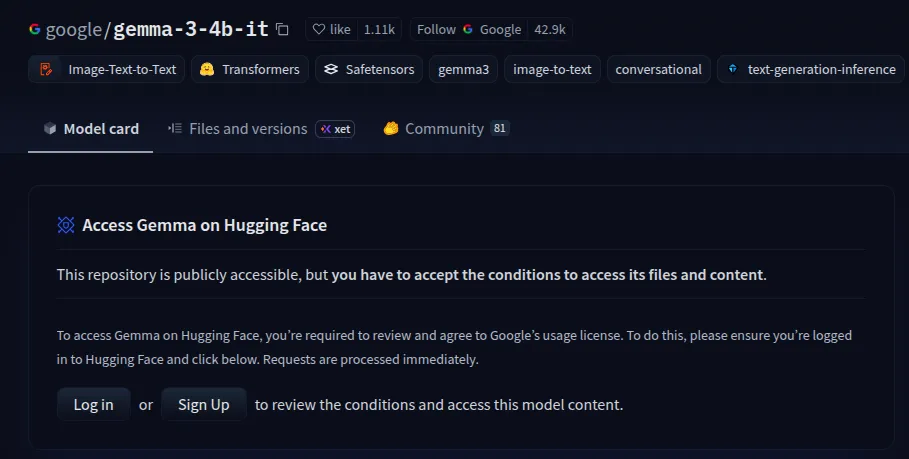
- قم بإنشاء رمز Hugging Face المميز الذي سنستخدمه لاحقًا من هنا.
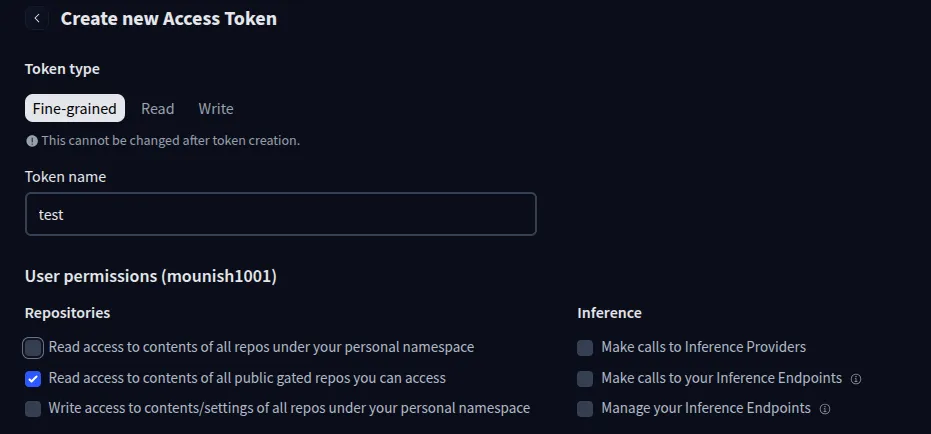
ملحوظة: تأكد من تحديد خيار “قراءة الوصول إلى محتويات جميع مستودعات البوابات العامة التي يمكنك الوصول إليها”.
- مثيل Google Colab مع وحدة معالجة الرسومات T4:
تأكد من تغيير نوع وقت التشغيل إلى T4 GPU في دفتر ملاحظات Colab الجديد.
نماذج التكميم لbfloat16
المنشآت
!pip install -U transformers accelerate أدخل رمز الوجه المعانق الخاص بك
!hf auth login الصق مفتاح Hugging Face عندما يُطلب منك ذلك.
ملحوظة: يمكنك كتابة “n” لإضافة رمز مميز كبيانات اعتماد git.
الواردات
from transformers import AutoProcessor, Gemma3ForConditionalGeneration
from PIL import Image
import requests
import torchجارٍ تحميل النموذج
import torch
desired_dtype = torch.bfloat16
torch.set_default_dtype(desired_dtype)
model_id = "google/gemma-3-4b-it"
model = Gemma3ForConditionalGeneration.from_pretrained(
model_id,
device_map="auto"
).eval()ملاحظة: سيؤدي تعيين dtype هنا إلى تكميم النموذج وتغيير الدقة الافتراضية لـ float32 إلى float16.
النظر في معلومات النموذج
- المعلمات وأنواعها في النموذج:
for name, param in model.named_parameters():
print(f"{name}: {param.dtype}")
breakالإخراج:
model.vision_tower.vision_model.embeddings.patch_embedding.weight: torch.bfloat16
ملحوظة: يمكنك إزالة الفاصل لرؤية جميع الطبقات، كما يمكنك أن ترى أن معلماتنا موجودة الآن في “bfloat16”
- البصمة النموذجية:
print("Footprint of the fp16 model in GBs: ", model.get_memory_footprint()/1e+9) الإخراج:
Footprint of the fp16 model in GBs: 8.600192738
ملحوظة: ستكون المساحة 17.200351684 جيجابايت إذا لم نقم بتحديد حجم النموذج، فمن المحتمل ألا يتم تشغيل هذا على مثيل Colab الذي أنشأناه.
تشغيل الاستدلال
processor = AutoProcessor.from_pretrained(model_id)
messages = (
{
"role": "system",
"content": ({"type": "text", "text": "You are a helpful assistant."})
},
{
"role": "user",
"content": ({"type": "text", "text": "Explain how a transformer works."})
}
)
inputs = processor.apply_chat_template(
messages,
add_generation_prompt=True,
tokenize=True,
return_dict=True,
return_tensors="pt"
).to(model.device)
input_len = inputs("input_ids").shape(-1)
with torch.inference_mode():
generation = model.generate(
**inputs,
max_new_tokens=100,
do_sample=False
)
generation = generation(0)(input_len:)
decoded = processor.decode(generation, skip_special_tokens=True)
print(decoded)الإخراج:
print(decoded)Okay, here’s a quick explanation of how a transformer works:
A transformer uses electromagnetic induction to change voltage levels.
Would you like me to delve into a specific aspect, like how
عظيم! لقد نجحنا في إجراء الاستدلال على النموذج الكمي وحصلنا على نتائج جيدة. الآن دعونا نحاول قياس النموذج إلى أبعد من ذلك.
نماذج التكميم إلى أبعد من ذلك
المنشآت
!pip install -U bitsandbytes ملحوظة: قم بتثبيت هذا مع عمليات التثبيت الأقدم إذا كنت قد بدأت مثيلاً جديدًا.
الواردات
from transformers import AutoProcessor, Gemma3ForConditionalGeneration, BitsAndBytesConfig
from PIL import Image
import requests
import torchجارٍ تحميل النموذج
model_id = "google/gemma-3-4b-it"
# Optimized 4-bit configuration
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.bfloat16,
bnb_4bit_quant_type="nf4",
bnb_4bit_use_double_quant=True # Quantizes the constants
)
model = Gemma3ForConditionalGeneration.from_pretrained(
model_id,
device_map="auto",
quantization_config=quantization_config,
torch_dtype=torch.bfloat16 # Crucial for Gemma stability
)ملحوظة: nf4 هو نوع بيانات لتكميم البتات المنخفضة عالي الكفاءة الذي نستخدمه. نحن نقوم بتكوين الحسابات تحت الغطاء في “bfloat16” للحصول على أداء جيد.
المعلمات وحجم النموذج
for name, param in model.named_parameters():
print(f'{name}: {param.dtype}')الإخراج:
model.vision_tower.vision_model.encoder.layers.2.layer_norm1.weight: torch.bfloat16
model.vision_tower.vision_model.encoder.layers.2.layer_norm1.bias: torch.bfloat16
model.vision_tower.vision_model.encoder.layers.2.self_attn.k_proj.weight: torch.uint8
model.vision_tower.vision_model.encoder.layers.2.self_attn.k_proj.bias: torch.bfloat16
model.vision_tower.vision_model.encoder.layers.2.self_attn.v_proj.weight: torch.uint8
model.vision_tower.vision_model.encoder.layers.2.self_attn.v_proj.bias: torch.bfloat16
model.vision_tower.vision_model.encoder.layers.2.self_attn.q_proj.weight: torch.uint8
model.vision_tower.vision_model.encoder.layers.2.self_attn.q_proj.bias: torch.bfloat16
model.vision_tower.vision_model.encoder.layers.2.self_attn.out_proj.weight: torch.uint8
model.vision_tower.vision_model.encoder.layers.2.self_attn.out_proj.bias: torch.bfloat16
model.vision_tower.vision_model.encoder.layers.2.layer_norm2.weight: torch.bfloat16
model.vision_tower.vision_model.encoder.layers.2.layer_norm2.bias: torch.bfloat16
model.vision_tower.vision_model.encoder.layers.2.mlp.fc1.weight: torch.uint8
لاحظت شيئا مثيرا للاهتمام؟ لا يتم تصغير كافة الطبقات. وذلك لأن تكميم البتات والبايتات في المحولات قام بتكميم المعلمات ثم أخذ وزنين 4 بت وحزمهما في حاوية torch.uint8 واحدة. البعض الآخر يتم كميته إلى “bfloat16‘.
print("Footprint of the model in GBs: ",
model.get_memory_footprint()/1e+9)الإخراج:
Footprint of the model in GBs: 3.170623202
عظيم! تم تقليل حجم النموذج بشكل كبير.
تشغيل الاستدلال
processor = AutoProcessor.from_pretrained(model_id)
messages = (
{
"role": "system",
"content": ({"type": "text", "text": "You are a helpful assistant."})
},
{
"role": "user",
"content": ({"type": "text", "text": "Explain how a transformer works in 60-80 words."})
}
)
inputs = processor.apply_chat_template(
messages,
add_generation_prompt=True,
tokenize=True,
return_dict=True,
return_tensors="pt"
).to(model.device)
input_len = inputs("input_ids").shape(-1)
with torch.inference_mode():
generation = model.generate(
**inputs,
max_new_tokens=100,
do_sample=False
)
generation = generation(0)(input_len:)
decoded = processor.decode(generation, skip_special_tokens=True)
print(decoded)الإخراج
print(decoded)Okay, here’s a breakdown of how a Transformer works in approximately 60-80 words:
Transformers are neural networks that excel at processing sequential data like text.
Essentially, the model simultaneously considers all input words, understanding their...
حسنًا، يختلف السياق الذي تم التقاطه بواسطة كلا النموذجين الكميين ولكننا لا نرى أي هلوسة ملحوظة في كلا الاستجابتين.
بدائل التكميم القياسي
فيما يلي بعض البدائل التي يمكنك استخدامها بدلاً من القياس الكمي القياسي:
- AWQ (تكميم الوزن المدرك للتنشيط): هذه الطريقة تحمي أهم الأوزان أثناء الضغط. في PyTorch، يمكننا تحميلها باستخدام AutoAWQForCausalLM (باستخدام مكتبة awq) ضمن طريقة from_pretrained الخاصة بـ Hugging Face لضمان دقة جيدة بأوزان 4 بت.
- GGUF (إطار التحديث المتدرج المعمم): تدعم محولات Hugging Face الآن GGUF أصلاً. باستخدام gguf، يمكنك إجراء تفريغ الطبقة، وتقسيم النموذج بين VRAM وذاكرة الوصول العشوائي للنظام لتشغيل نماذج ضخمة على أجهزة محدودة.
- كلورا: نعم، أنا أقترح تحسين النموذج الخاص بك. بدلاً من النضال من أجل تشغيل نموذج ضخم بقيمة 8 مليارات، يمكن أن يكون تحسين نموذج 3 مليارات على بياناتك المحددة أفضل. غالبًا ما يتفوق النموذج الخاص بالمجال على النموذج العام أثناء استخدام ذاكرة أقل بكثير.
اقرأ أيضًا: أفضل 15+ من موفري GPU السحابيين لعام 2026
خاتمة
في المرة القادمة التي تضغط فيها على “تشغيل على نموذج ضخم”، لا تدع مثيل Google Colab الخاص بك يتعطل. من خلال تعلم العلاقة بين عدد المعلمات ودقة الوزن، يمكنك حساب مساحة الذاكرة المطلوبة بشكل تقريبي. سواء من خلال bfloat16 أو التكميم العميق بمقدار 4 بت، لم يعد تقليص حجم النموذج لغزًا. لديك الآن الأدوات والأفكار اللازمة للتعامل مع النماذج الكبيرة بسهولة. تذكر أيضًا اختبار نماذجك على مجموعات البيانات القياسية لتقييم أدائها.
الأسئلة المتداولة
A. عرض تفاصيل وحدة المعالجة المركزية باستخدام !lscpu وحالة GPU عبر !nvidia-smi. وبدلاً من ذلك، انقر فوق شريط حالة ذاكرة الوصول العشوائي/القرص (في الجزء العلوي الأيمن) لرؤية تخصيص موارد الأجهزة الحالية واستخدامها.
A. قم بتقييم LLMs باستخدام MMLU للمعرفة، وGSM8K للرياضيات، وHumanEval للبرمجة، وTruthfulQA. استخدم مجموعة بيانات خاصة بالمجال إذا كنت تقوم بتقييم نموذج تم ضبطه بدقة.
A. QLoRA هي طريقة ضبط دقيقة فعالة تستخدم تكميم 4 بت لتقليل استخدام الذاكرة مع الحفاظ على الأداء من خلال تدريب طبقات المحول الصغيرة في الأعلى.
![]()
شغوف بالتكنولوجيا والابتكار، خريج معهد فيلور للتكنولوجيا. أعمل حاليًا كمتدرب في علوم البيانات، مع التركيز على علوم البيانات. مهتم بشدة بالتعلم العميق والذكاء الاصطناعي التوليدي، ومتلهف لاستكشاف التقنيات المتطورة لحل المشكلات المعقدة وإنشاء حلول مؤثرة.
قم بتسجيل الدخول لمواصلة القراءة والاستمتاع بالمحتوى الذي ينظمه الخبراء.
Source link