
بناء نموذج أولي LLM هو سريع. بضعة أسطر من بايثون، موجه، ويعمل. لكن الإنتاج لعبة مختلفة تمامًا. تبدأ في رؤية إجابات غامضة، وهلوسة، وطفرات في زمن الاستجابة، وإخفاقات غريبة حيث من الواضح أن النموذج “يعرف” شيئًا ما ولكنه لا يزال يخطئ في فهمه. نظرًا لأن كل شيء يعمل وفقًا للاحتمالات، يصبح تصحيح الأخطاء أمرًا صعبًا. لماذا تحول البحث عن الأحذية إلى أحذية؟ لقد قام النظام بالاختيار، لكن لا يمكنك تتبع الأسباب بسهولة.
لمعالجة هذا، سوف نبني فيوزكومرس، نظام دعم التجارة الإلكترونية المتقدم المصمم للرؤية والتحكم. باستخدام Langfuse، سنقوم بإنشاء سير عمل وكيل مع البحث الدلالي وتصنيف النوايا، مع الحفاظ على شفافية كل قرار. في هذه المقالة، سنقوم بتحويل النموذج الأولي الهش إلى نظام LLM يمكن ملاحظته وجاهز للإنتاج.
ما هو لانجفيوز؟
تعمل Langfuse كمنصة مفتوحة المصدر لهندسة LLM والتي تمكن الفرق من العمل معًا على تصحيح الأخطاء وتحليل وتطوير تطبيقات LLM الخاصة بهم. تعمل المنصة كأدوات تطوير لوكلاء الذكاء الاصطناعي.
ويقدم النظام ثلاث وظائف رئيسية تشمل:
- التتبع الذي يعرض جميع مسارات التنفيذ من خلال النظام بما في ذلك مكالمات LLM واستعلامات قاعدة البيانات واستخدام الأداة.
- المقاييس التي توفر مراقبة في الوقت الفعلي لوقت الاستجابة والتكلفة واستخدام الرمز المميز.
- التقييم الذي يجمع تعليقات المستخدمين من خلال نظام الإبهام والإبهام الذي يتصل مباشرة بالجيل المحدد الذي أنتج التعليقات.
- يتيح النظام الاختبار من خلال إدارة مجموعة البيانات التي تتيح للمستخدمين تنظيم مدخلات ومخرجات الاختبار الخاصة بهم.
في هذا المشروع، يعمل Langfuse كنظام التسجيل الرئيسي لدينا والذي يساعدنا في إنشاء نظام آلي يعزز أدائه.
ما نقوم بإنشائه: FuseCommerce…
سنقوم بتطوير ممثل ذكي لدعم العملاء لشركة تجزئة تكنولوجية يُدعى “فيوزكومرس“.
وعلى النقيض من غلاف LLM القياسي، سيتم تضمين العناصر التالية:
- التوجيه المعرفي – القدرة على تحليل (التفكير مليًا) ما يجب قوله قبل الرد – بما في ذلك تحديد سبب (أسباب) التفاعل (أي الرغبة في شراء شيء ما مقابل التحقق من الطلب مقابل الرغبة في التحدث عن شيء ما).
- الذاكرة الدلالية – القدرة على معرفة الأفكار وتمثيلها كمفاهيم (على سبيل المثال: كيفية ربط “معدات الألعاب” و”الفأرة الميكانيكية” من الناحية المفاهيمية) عبر تضمين المتجهات.
- التفكير البصري (بما في ذلك واجهة مستخدم مذهلة) – وسيلة للعرض بصريًا (للعميل) ما يفعله الوكيل.
دور لانجفيوز في المشروع
Langfuse هو العمود الفقري للعامل المستخدم في هذا العمل. فهو يتيح لنا اتباع الخطوات الفريدة لعميلنا (تصنيف النوايا، والاسترجاع، والتوليد) ويوضح لنا كيف تعمل جميعها معًا، مما يسمح لنا بتحديد مكان حدوث خطأ ما إذا كانت الإجابة غير صحيحة.
- إمكانية التتبع – سنسعى إلى التقاط جميع خطوات العميل على Langfuse باستخدام الامتدادات. عندما يتلقى المستخدم إجابة غير صحيحة، يمكننا استخدام التتبع الممتد أو التتبع لتحديد مكان حدوث الخطأ بالضبط أثناء عملية الوكيل.
- تتبع الجلسة – سنقوم بالتقاط جميع التفاعلات بين المستخدم والوكيل ضمن مجموعة واحدة يتم تحديدها بواسطة `
session_id` على لوحة تحكم Langfuse للسماح لنا بإعادة تشغيل كل تفاعلات المستخدم للسياق. - حلقة ردود الفعل – سنقوم بإنشاء أزرار تعليقات المستخدمين مباشرة في التتبع، لذلك إذا قام المستخدم بالتصويت السلبي على إجابة ما، فسنكون قادرين على معرفة أي استرجاع على الفور أو مطالبة المستخدم بالخبرة التي أدت إلى التصويت السلبي للإجابة.
ابدء
يمكنك بدء عملية التثبيت للوكيل بسرعة وسهولة.
المتطلبات الأساسية
تثبيت
أول شيء عليك القيام به هو تثبيت التبعيات التالية والتي تتكون من Langfuse SDK وGoogle’s Geneative AI.
pip install langfuse streamlit google-generativeai python-dotenv numpy scikit-learn 
إعدادات
بعد الانتهاء من تثبيت المكتبات، ستحتاج إلى إنشاء ملف .env ملف حيث سيتم تخزين بيانات الاعتماد الخاصة بك بطريقة آمنة.
GOOGLE_API_KEY=your_gemini_key
LANGFUSE_PUBLIC_KEY=pk-lf-...
LANGFUSE_SECRET_KEY=sk-lf-...
LANGFUSE_HOST=https://cloud.langfuse.com
كيفية البناء؟
الخطوة 1: قاعدة المعرفة الدلالية
يمكن أن ينهار البحث التقليدي عن الكلمات الرئيسية إذا استخدم المستخدم كلمات مختلفة، أي استخدام المرادفات. لذلك، نريد الاستفادة من Vector Embeddings لإنشاء محرك بحث دلالي.
من خلال الرياضيات فقط، أي تشابه جيب التمام، سنقوم بإنشاء “ناقل المعنى” لكل منتج من منتجاتنا.
# db.py
from sklearn.metrics.pairwise import cosine_similarity
import google.generativeai as genai
def semantic_search(query):
# Create a vector representation of the query
query_embedding = genai.embed_content(
model="models/text-embedding-004",
content=query
)("embedding")
# Using math, find the nearest meanings to the query
similarities = cosine_similarity((query_embedding), product_vectors)
return get_top_matches(similarities)
الخطوة الثانية: “عقل” التوجيه الذكي
عندما يقول المستخدمون “مرحبًا”، يمكننا تصنيف نية المستخدم باستخدام مصنف حتى نتمكن من تجنب البحث في قاعدة البيانات.
سترى أننا أيضًا نكتشف تلقائيًا المدخلات والمخرجات ووقت الاستجابة باستخدام @langfuse.observe مصمم ديكور. مثل السحر!
@langfuse.observe(as_type="generation")
def classify_user_intent(user_input):
prompt = f"""
Use the following user input to classify the user's intent into one of the three categories:
1. PRODUCT_SEARCH
2. ORDER_STATUS
3. GENERAL_CHAT
Input: {user_input}
"""
# Call Gemini model here...
intent = "PRODUCT_SEARCH" # Placeholder return value
return intent
الخطوة 3: سير عمل الوكيل
نحن نخيط عمليتنا معًا. سوف يقوم الوكيل بالإدراك، والحصول على المدخلات، والتفكير (التصنيف)، ثم التصرف (التوجيه).
نحن نستخدم الطريقة lf_client.update_current_trace لوضع علامة على المحادثة بمعلومات البيانات الوصفية مثل session_id.
@langfuse.observe() # Root Trace
def handle_customer_user_input(user_input, session_id):
# Tag the session
langfuse.update_current_trace(session_id=session_id)
# Think
intent = get_classified_intent(user_input)
# Act based on classified intent
if intent == "PRODUCT_SEARCH":
context = use_semantic_search(user_input)
elif intent == "ORDER_STATUS":
context = check_order_status(user_input)
else:
context = None # Optional fallback for GENERAL_CHAT or unknown intents
# Return the response
response = generate_ai_response(context, intent)
return responseالخطوة 4: واجهة المستخدم ونظام الملاحظات
نقوم بإنشاء واجهة مستخدم Streamlit محسنة. التغيير المهم هو أن أزرار التعليقات ستوفر نتيجة ملاحظات إلى Langfuse بناءً على معرف التتبع الفردي المرتبط بمحادثة المستخدم المحددة.
# app.py
col1, col2 = st.columns(2)
if col1.button("👍"):
lf_client.score(trace_id=trace_id, name="user-satisfaction", value=1)
if col2.button("👎"):
lf_client.score(trace_id=trace_id, name="user-satisfaction", value=0)المدخلات والمخرجات وتحليل النتائج
دعونا نلقي نظرة فاحصة على استفسار المستخدم: “هل تبيعون أي ملحقات لأنظمة الألعاب؟”
- الاستفسار
- مستخدم: “هل تبيعون أي ملحقات لأنظمة الألعاب؟”
- سياق: لا توجد تطابق تام للكلمة الرئيسية “ملحق”.
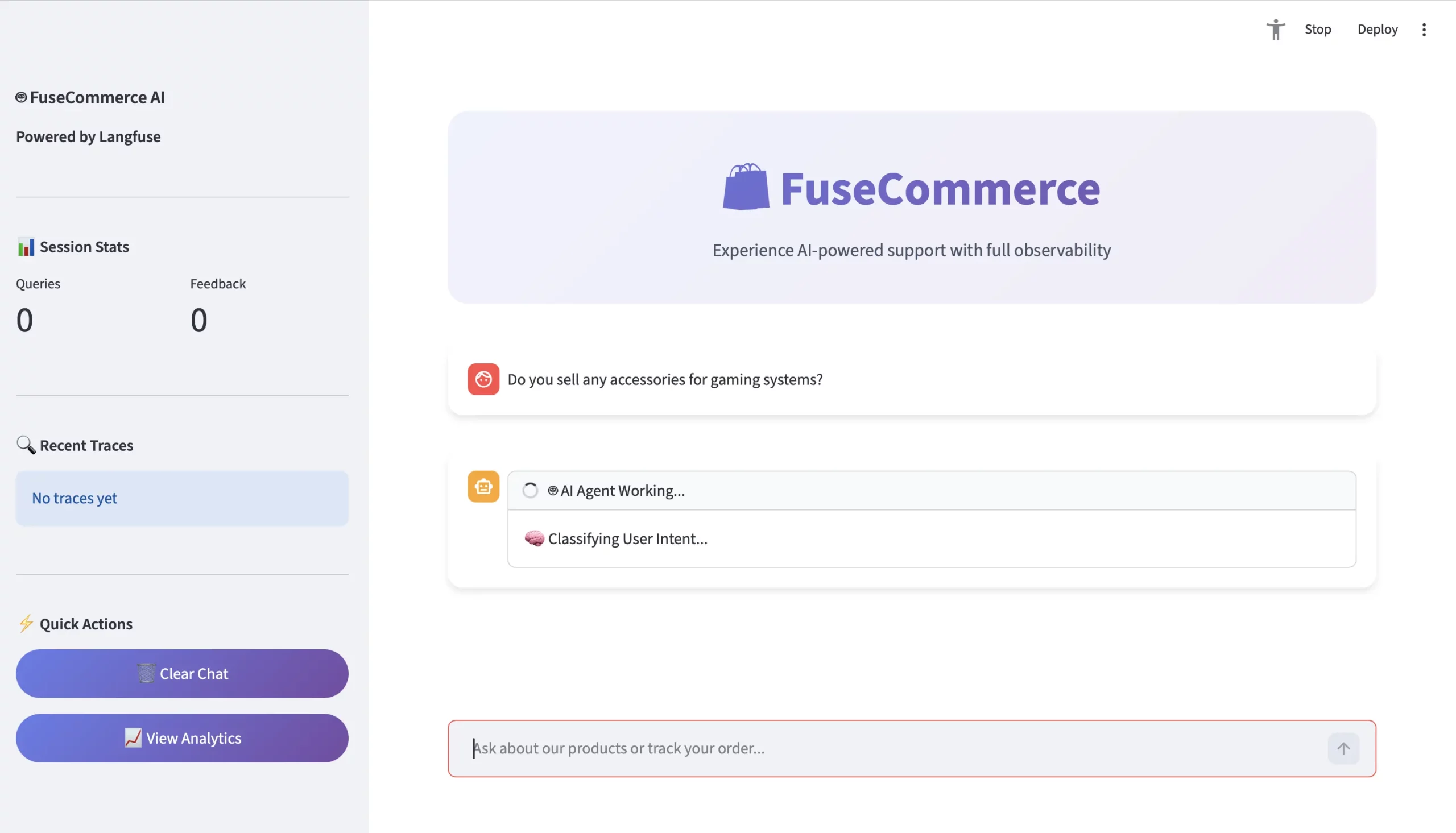
- الأثر (نقطة لانجفيوز للمنظور)
سيقوم Langfuse بإنشاء عرض تتبع لتصور التسلسل الهرمي المتداخل:
TRACE: محادثة الوكيل (1.5 ثانية)
- جيل: classify_intent -> الإخراج = PRODUCT_SEARCH
- فترة: Recovery_knowledge –> البحث الدلالي = يقوم بتعيين بيانات الألعاب هندسيًا إلى ماوس Quantum Wireless Mouse وUltraView Monitor.
- جيل: generator_ai_response –> Output = “نعم! بالنسبة لأنظمة الألعاب، سنوصي باستخدام ماوس Quantum اللاسلكي…”
- تحليل
بمجرد أن ينقر المستخدم على “الإبهام”، يحصل Langfuse على درجة 1. سيكون لديك إجمالي عدد النقرات “الإبهام” يوميًا لعرض المتوسط اليومي. سيكون لديك أيضًا لوحة تحكم مرئية تراكمية لعرضها:
- متوسط الكمون: هل بحثك الدلالي بطيء؟؟
- دقة النية: هل التوجيه هلوسة؟؟
- التكلفة / الجلسة: كم تكلفة استخدام الجوزاء؟؟
خاتمة
من خلال تطبيقنا لـ Langfuse، قمنا بتحويل نظام chatbot ذو الوظيفة المخفية إلى نظام تشغيلي مفتوح ومرئي. لقد أنشأنا ثقة المستخدم من خلال تطوير وظائف المنتج.
لقد أثبتنا أن وكيلنا يمتلك قدرات “التفكير” من خلال تصنيف النوايا بينما يمكنه “فهم” الأشياء من خلال البحث الدلالي ويمكنه “اكتساب” المعرفة من خلال نتائج تعليقات المستخدم. يعد هذا التصميم المعماري بمثابة الأساس لأنظمة الذكاء الاصطناعي المعاصرة التي تعمل في بيئات العالم الحقيقي.
الأسئلة المتداولة
A. يوفر Langfuse أدوات التتبع والمقاييس والتقييم لتصحيح أخطاء وكلاء LLM ومراقبتهم وتحسينهم في الإنتاج.
ج: يستخدم تصنيف النوايا لاكتشاف نوع الاستعلام، ثم التوجيه إلى البحث الدلالي، أو البحث عن الطلبات، أو منطق الدردشة العام.
أ. يتم تسجيل تعليقات المستخدم لكل عملية تتبع، مما يتيح مراقبة الأداء والتحسين التكراري للمطالبات والاسترداد والتوجيه.
![]()
متدرب في علوم البيانات في Analytics Vidhya
أعمل حاليًا كمتدرب في علوم البيانات في Analytics Vidhya، حيث أركز على بناء حلول تعتمد على البيانات وتطبيق تقنيات الذكاء الاصطناعي/التعلم الآلي لحل مشكلات الأعمال الواقعية. يتيح لي عملي استكشاف التحليلات المتقدمة والتعلم الآلي وتطبيقات الذكاء الاصطناعي التي تمكن المؤسسات من اتخاذ قرارات أكثر ذكاءً وقائمة على الأدلة.
مع أساس قوي في علوم الكمبيوتر، وتطوير البرمجيات، وتحليلات البيانات، أنا متحمس للاستفادة من الذكاء الاصطناعي لإنشاء حلول مؤثرة وقابلة للتطوير تعمل على سد الفجوة بين التكنولوجيا والأعمال.
📩 كما يمكنكم التواصل معي على (البريد الإلكتروني محمي)
قم بتسجيل الدخول لمواصلة القراءة والاستمتاع بالمحتوى الذي ينظمه الخبراء.



