
بناء مشروع مطابقة الصور الحقيقية باستخدام Gemini Embedding 2
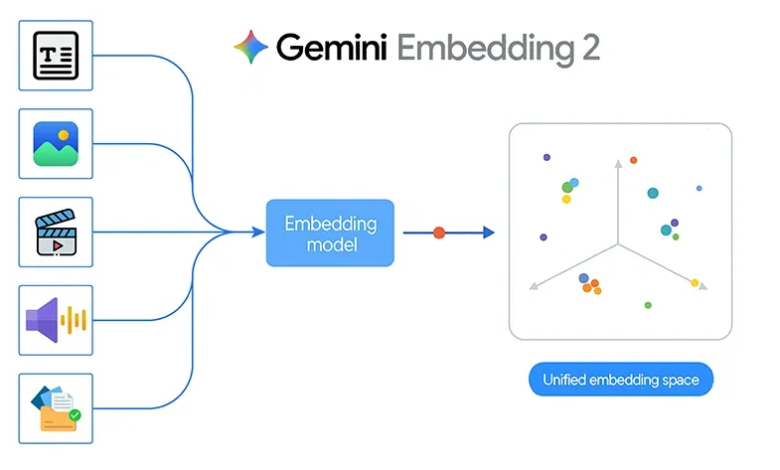
طرحت Google مؤخرًا Gemini Embedding 2، وهو أول نموذج تضمين متعدد الوسائط محليًا. تعد هذه خطوة مهمة للأمام لأنها تجمع النصوص والصور والفيديو والصوت والمستندات في مساحة تضمين مشتركة واحدة. بدلاً من العمل مع نماذج منفصلة لكل نوع من البيانات، يمكن للمطورين الآن استخدام نموذج تضمين واحد عبر طرائق متعددة للاسترجاع والبحث والتجميع والتصنيف.
وهذا التحول قوي من الناحية النظرية، لكنه يصبح أكثر إثارة للاهتمام عند تطبيقه على مشروع حقيقي. لاستكشاف ما يمكن أن يفعله Gemini Embedding 2 عمليًا، قمت ببناء نظام بسيط لمطابقة الصور يحدد الشخص الموجود في صورة الاستعلام الأكثر تشابهًا مع الصور المخزنة.
الجوزاء التضمين 2 الميزات الرئيسية
غالبًا ما يتم تصميم أنظمة التضمين التقليدية للنص وحده. إذا كنت ترغب في إنشاء نظام يعمل عبر الصور أو الصوت أو المستندات، فعادةً ما يتعين عليك ربط خطوط أنابيب متعددة معًا. يتغير Gemini Embedding 2 عن طريق تعيين أنواع مختلفة من المحتوى في مساحة متجهة واحدة موحدة.
وفقًا لجوجل، يدعم Gemini Embedding 2 ما يلي:
- نص يحتوي على ما يصل إلى 8192 رمزًا للإدخال
- الصور، بما يصل إلى 6 صور لكل طلب بتنسيق PNG وJPEG
- فيديو تصل مدته إلى 120 ثانية بصيغة mp4 و mov
- الصوت دون الحاجة إلى النسخ أولاً
- مستندات PDF يصل طولها إلى 6 صفحات
كما أنه يدعم الإدخال المتعدد الوسائط المتداخل، مثل الصورة بالإضافة إلى النص في طلب واحد. يتيح ذلك للنموذج التقاط علاقات أكثر ثراءً بين أنواع البيانات المختلفة.
ميزة أخرى مهمة هي أبعاد المخرجات المرنة من خلال تعلم تمثيل ماتريوشكا. الحجم الافتراضي هو 3072 بُعدًا، ولكن يمكن تصغيره إلى أحجام أصغر مثل 1536 أو 768. وهذا يساعد المطورين على تحقيق التوازن بين الجودة والتخزين وسرعة الاسترداد اعتمادًا على التطبيق.
اقرأ أيضًا: 14 تقنية قوية تحدد تطور التضمين
بناء نظام مطابقة الصور باستخدام Gemini Embedding 2
يستخدم المشروع ثلاثة مجلدات داخل دليل مجموعة البيانات:
dataset/
nitika/
vasu/
janvi/
يحتوي كل مجلد على صور متعددة لشخص واحد. الهدف واضح ومباشر:
- قراءة جميع الصور من مجموعة البيانات
- قم بإنشاء تضمين لكل صورة باستخدام Gemini Embedding 2
- قم بتخزين هذه التضمينات في الذاكرة وقم بتخزينها محليًا
- التقاط صورة الاستعلام
- توليد التضمين الخاص به
- قارنه مع كافة تضمينات الصور المخزنة باستخدام تشابه جيب التمام
- قم بإرجاع أفضل الصور المطابقة وتوقع اسم الشخص
يعد هذا مثالًا قويًا لكيفية استخدام Gemini Embedding 2 للاسترجاع القائم على الصور والتصنيف خفيف الوزن.
أفضل جزء من هذا المشروع هو أنه لا يتطلب خط تدريب كامل للتعلم العميق. لا يوجد تدريب مخصص لـ CNN، ولا يوجد ضبط دقيق، ولا يوجد سير عمل كثيف التعليقات التوضيحية. بدلاً من ذلك، يعتمد النظام على نموذج التضمين كمستخرج للميزات الدلالية.
وهذا يجعل التنمية أسرع بكثير.
نظرًا لأن Gemini Embedding 2 متعدد الوسائط في الأصل، فيمكن توسيع تصميم المشروع نفسه لاحقًا إلى ما هو أبعد من الصور. على سبيل المثال:
- مطابقة مقطع صوتي منطوق مع ملف تعريف الشخص
- البحث عن ملف PDF ذي صلة من صورة
- استرداد مقطع فيديو من استعلام نصي
- مقارنة أوصاف الصور والنصوص المختلطة في مساحة تضمين واحدة
وبهذا المعنى، فإن المشروع الحالي هو نقطة دخول بسيطة إلى بنية استرجاعية متعددة الوسائط أوسع بكثير.
استخدام Gemini Embedding 2 API
توفر Google نموذج Gemini Embedding 2 من خلال Gemini API وVertex AI. يتم إجراء مكالمة التضمين من خلال embed_content طريقة.
يبدو المثال المتعدد الوسائط من Google كما يلي:
from google import genai
from google.genai import types
client = genai.Client()
with open("example.png", "rb") as f:
image_bytes = f.read()
with open("sample.mp3", "rb") as f:
audio_bytes = f.read()
result = client.models.embed_content(
model="gemini-embedding-2-preview",
contents=(
"What is the meaning of life?",
types.Part.from_bytes(
data=image_bytes,
mime_type="image/png",
),
types.Part.from_bytes(
data=audio_bytes,
mime_type="audio/mpeg",
),
),
)
print(result.embeddings) بالنسبة لمشروعي، كنت بحاجة فقط إلى جزء الصورة من سير العمل هذا. بدلاً من إرسال النص والصورة والصوت معًا، استخدمت صورة واحدة لكل طلب وقمت بتضمينها.
تنفيذ المشروع
يبدأ المشروع بتحميل مفتاح Gemini API من ملف .env وإنشاء عميل:
from dotenv import load_dotenv
import os
from google import genai
load_dotenv()
GEMINI_API_KEY = os.getenv("GEMINI_API_KEY")
client = genai.Client(api_key=GEMINI_API_KEY) ثم قمت بتعريف الوظائف المساعدة للتحقق من صحة الصورة، واكتشاف نوع MIME، والتطبيع، وتشابه جيب التمام، وعرض الصورة.
تقوم وظيفة التضمين الرئيسية بقراءة بايتات الصورة وإرسالها إلى Gemini Embedding 2:
def embed_image(image_path):
image_path = Path(image_path)
mime_type = guess_mime_type(image_path)
with open(image_path, "rb") as f:
image_bytes = f.read()
result = client.models.embed_content(
model="gemini-embedding-2-preview",
contents=(
types.Part.from_bytes(
data=image_bytes,
mime_type=mime_type,
)
),
config=types.EmbedContentConfig(
output_dimensionality=3072
)
)
emb = np.array(result.embeddings(0).values, dtype=np.float32)
return normalize(emb) هذه الوظيفة هي جوهر خط الأنابيب بأكمله. فهو يحول كل صورة إلى تمثيل متجه ذي 3072 بُعدًا.
بناء قاعدة بيانات تضمين مجموعة البيانات
والخطوة التالية هي الاطلاع على مجلد مجموعة البيانات، وقراءة جميع الصور لكل شخص، وتضمينها واحدة تلو الأخرى.
يتم تخزين كل صورة مضمنة كقاموس يحتوي على:
- تسمية الشخص
- مسار الملف
- ناقلات التضمين
لتجنب إعادة حساب عمليات التضمين في كل مرة، قمت بتخزينها مؤقتًا في ملف اختيار محلي:
def build_embeddings_db(dataset, cache_file="image_embeddings_cache.pkl", force_rebuild=False):
cache_path = Path(cache_file)
if cache_path.exists() and not force_rebuild:
with open(cache_path, "rb") as f:
embeddings_db = pickle.load(f)
return embeddings_db
embeddings_db = ()
for item in dataset:
emb = embed_image(item("path"))
embeddings_db.append({
"label": item("label"),
"path": item("path"),
"embedding": emb
})
with open(cache_path, "wb") as f:
pickle.dump(embeddings_db, f)
return embeddings_dbوهذا يجعل دفتر الملاحظات أكثر كفاءة لأنه يتم إنشاء عمليات التضمين مرة واحدة فقط ما لم تتغير مجموعة البيانات.
مطابقة صورة الاستعلام
بمجرد أن تصبح عمليات تضمين مجموعة البيانات جاهزة، فإن الخطوة التالية هي اختبار النظام باستخدام صورة استعلام جديدة.
تم تضمين صورة الاستعلام باستخدام نفس الوظيفة. ثم تتم مقارنة التضمين الخاص به بجميع التضمينات المخزنة باستخدام تشابه جيب التمام.
def find_best_matches(query_image_path, top_k=5):
query_emb = embed_image(query_image_path)
results = ()
for item in embeddings_db:
score = cosine_similarity(query_emb, item("embedding"))
results.append({
"label": item("label"),
"path": item("path"),
"score": score
})
results.sort(key=lambda x: x("score"), reverse=True)
return results(:top_k) تقوم هذه الوظيفة بإرجاع أفضل صور مجموعة البيانات المطابقة.
للتنبؤ بتسمية الشخص النهائي، استخدمت التصويت بـ top-k:
def predict_person(query_image_path, top_k=5):
matches = find_best_matches(query_image_path, top_k=top_k)
labels = (m("label") for m in matches)
predicted_label = Counter(labels).most_common(1)(0)(0)
return predicted_label, matches وهذا أكثر استقرارًا من الاعتماد على صورة واحدة أقرب.
اختبار المشروع
في المشروع، قمت باختبار صور الاستعلام مثل:
مثال 1:
query_image = "Nitika_Test_Image.jpeg"
predicted_person, matches = predict_person(query_image, top_k=2)
print("\nQuery image:")
show_image(query_image, title="Query Image")
print("Predicted person:", predicted_person)
print("\nTop matches:")
for i, match in enumerate(matches, 1):
print(f"{i}. {match('label')} | score={match('score'):.4f} | path={match('path')}")
show_image(match("path"), title=f"Rank {i} | {match('label')} | score={match('score'):.4f}")
print("\nBest match:")
print(matches(0))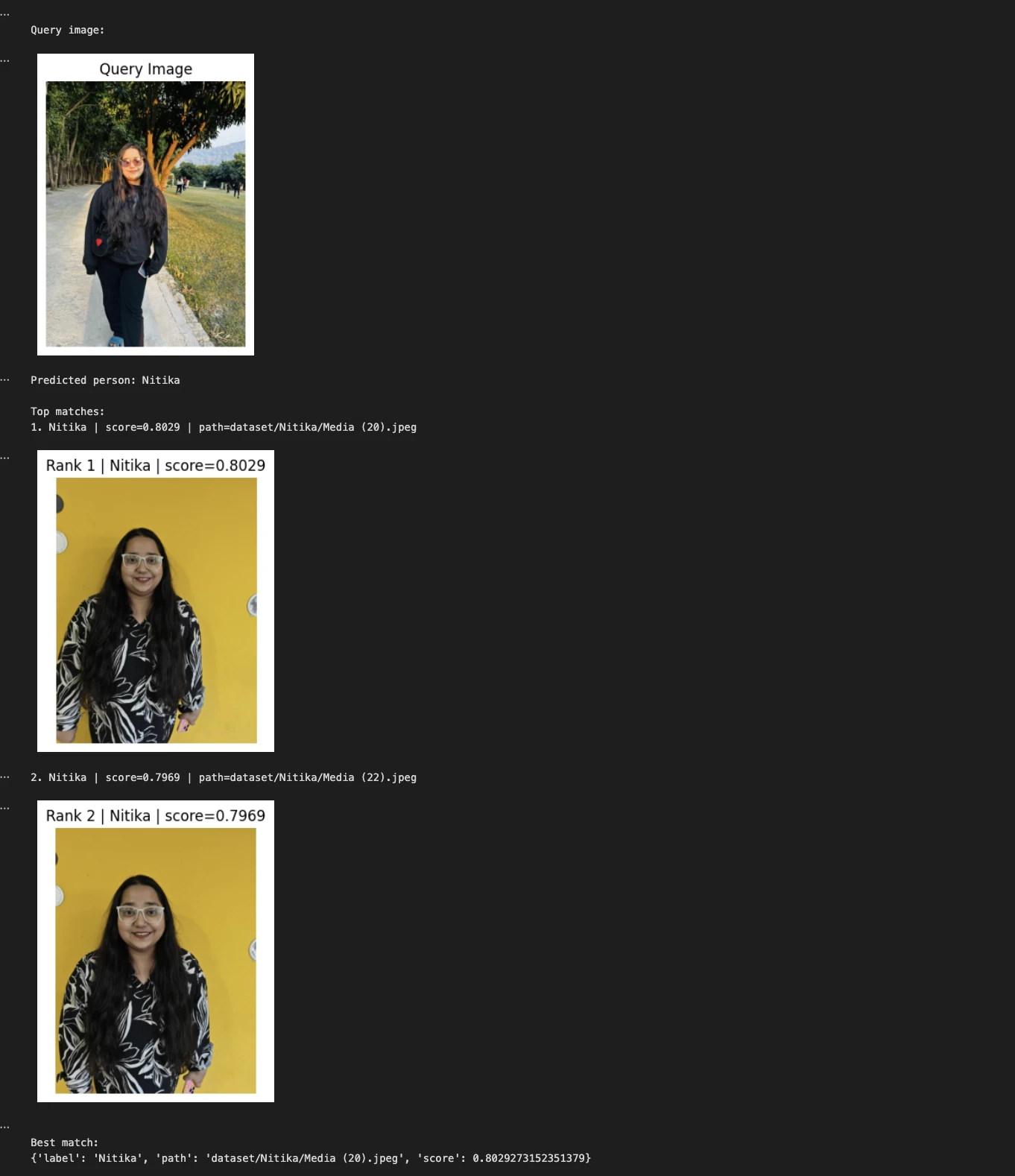
مثال 2:
query_image = "/Users/janvi/Downloads/Him.jpeg" # change this
predicted_person, matches = predict_person(query_image, top_k=2)
print("\nQuery image:") show_image(query_image, title="Query Image")
print("Predicted person:", predicted_person) print("\nTop matches:")
for i, match in enumerate(matches, 1):
print(f"{i}. {match('label')} | score={match('score'):.4f} | path={match('path')}") show_image(match("path"), title=f"Rank {i} | {match('label')} | score={match('score'):.4f}")
print("\nBest match:") print(matches(0))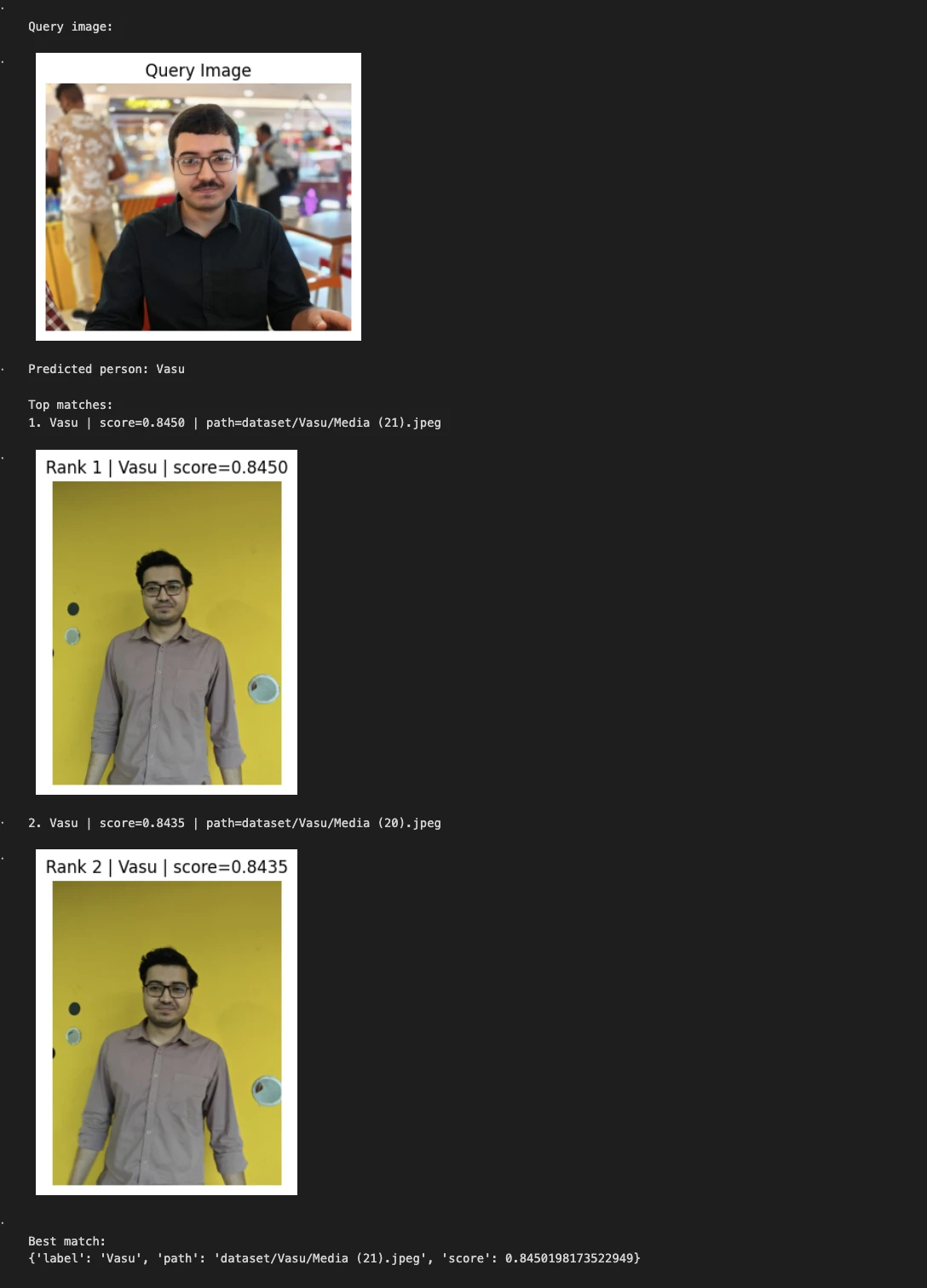
المثال الثالث:
query_image = "/Users/janvi/Downloads/Nerd.jpeg" # change this
predicted_person, matches = predict_person(query_image, top_k=5)
print("\nQuery image:")
show_image(query_image, title="Query Image")
print("Predicted person:", predicted_person)
print("\nTop matches:")
for i, match in enumerate(matches, 1):
print(f"{i}. {match('label')} | score={match('score'):.4f} | path={match('path')}")
show_image(match("path"), title=f"Rank {i} | {match('label')} | score={match('score'):.4f}")
print("\nBest match:")
print(matches(0))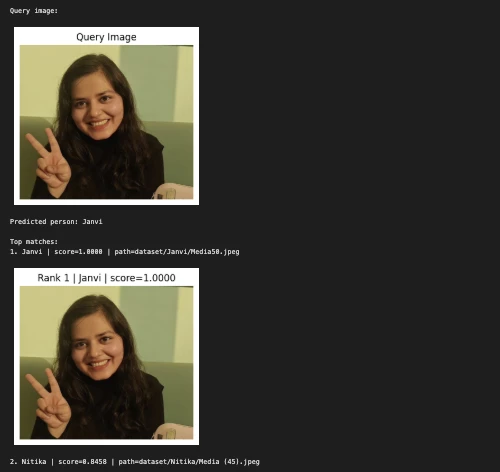
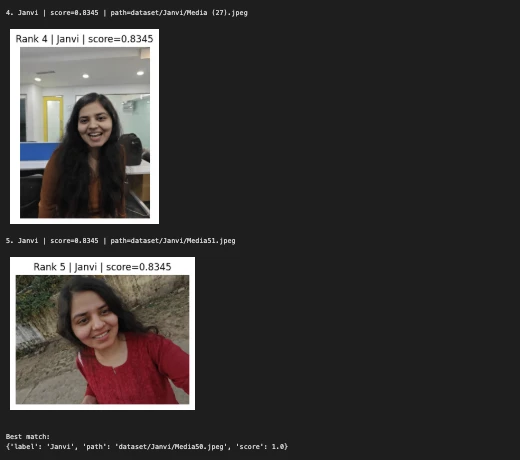
ثم تم عرض دفتر الملاحظات:
- صورة الاستعلام
- تسمية الشخص المتوقع
- أعلى الصور المطابقة من مجموعة البيانات
- درجة تشابه جيب التمام لكل مباراة
وهذا يجعل من السهل فحص النظام بصريًا ويساعد في التحقق مما إذا كان الاسترجاع القائم على التضمين يعمل بشكل صحيح.
تجربتي في استخدام الجوزاء التضمين 2
قد يكون هذا المشروع بسيطًا، لكنه يوضح بوضوح القيمة العملية لـ Gemini Embedding 2.
أولا، يوضح أنه يمكن استخدام التضمينات مباشرة لاسترجاع الصور دون تدريب نموذج تصنيف منفصل.
ثانيًا، يوضح كيف يمكن لمساحة التضمين المشتركة أن تبسط التطبيقات الحقيقية. على الرغم من أن هذا الإصدار يستخدم الصور فقط، إلا أنه يمكن توسيع نفس البنية لاحقًا لتشمل استرجاع النصوص والصوت والفيديو والمستندات.
ثالثًا، يسلط الضوء على كيفية تقليل التضمينات الحديثة متعددة الوسائط من الحاجة إلى خطوط أنابيب المعالجة المسبقة المعقدة. بدلاً من استخراج الميزات المصنوعة يدويًا أو إنشاء نموذج من الصفر، يمكن للمطورين استخدام نموذج التضمين باعتباره العمود الفقري الدلالي للأغراض العامة.
نقاط قوة هذا النهج
هناك عدة أسباب تجعل هذا النهج يعمل بشكل جيد بالنسبة للنموذج الأولي:
- القليل جدا من النفقات العامة للتدريب
- تنفيذ بسيط في دفتر الملاحظات
- من السهل أن تمتد
- تجريب سريع
- نتائج يمكن قراءتها بواسطة الإنسان من خلال تصور أفضل التطابقات
- يعمل بشكل طبيعي مع البحث عن التشابه
إنه مفيد بشكل خاص لمهام مطابقة الصور صغيرة الحجم حيث تريد إثباتًا واضحًا للمفهوم.
القيود
وفي الوقت نفسه، لا يزال هذا تجريبيًا خفيف الوزن وليس نظامًا بيومتريًا للإنتاج.
تجدر الإشارة إلى بعض القيود:
- يعتمد الأداء على جودة الصورة والإضاءة والخلفية والوضعية
- عادةً ما يؤدي المزيد من الصور لكل شخص إلى تحسين المتانة
- قد ينتج الأشخاص ذوو المظهر المماثل زخارف أقرب
- لا يتضمن خط الأنابيب الحالي عتبة شخص غير معروف
- وستكون هناك حاجة إلى مجموعة تقييم كاملة لإجراء قياس جدي
هذه ليست إخفاقات في Gemini Embedding 2. إنها اعتبارات عادية لأي نظام لمطابقة الصور.
خاتمة
يمثل Gemini Embedding 2 تحولًا مهمًا في كيفية عمل المطورين مع البيانات متعددة الوسائط. بدلاً من بناء مسارات منفصلة للنصوص والصور والصوت والفيديو والمستندات، لدينا الآن نموذج مصمم لتمثيل كل منهم في مساحة دلالية موحدة.
يعد مشروع مطابقة الصور الخاص بي مثالًا صغيرًا ولكنه مفيد لهذه الفكرة في الممارسة العملية. من خلال تضمين صور لثلاثة أشخاص معروفين ومقارنة صورة استعلام من خلال تشابه جيب التمام، تمكنت من إنشاء سير عمل استرجاع وتصنيف نظيف باستخدام القليل جدًا من التعليمات البرمجية.
هذا هو الوعد الحقيقي لـ Gemini Embedding 2. إنه ليس مجرد إعلان عن نموذج جديد. إنها لبنة بناء عملية للأنظمة متعددة الوسائط التي يسهل تصميمها، وأسهل في التوسع، وأقرب بكثير إلى بيانات العالم الحقيقي.
الأسئلة المتداولة
ج: إنه نموذج التضمين متعدد الوسائط من Google الذي يقوم بتعيين النص والصور والصوت والفيديو والمستندات في مساحة متجهة مشتركة واحدة للبحث والاسترجاع والتجميع والتصنيف.
أ. يقوم بتضمين صور مجموعة البيانات، ومقارنة صورة الاستعلام باستخدام تشابه جيب التمام، والتنبؤ بالشخص بناءً على أقرب التضمينات المطابقة.
ج: يعمل كمستخرج للميزات الدلالية، مما يسمح بمطابقة الصور دون بناء أو تدريب نموذج تصنيف منفصل للتعلم العميق.
![]()
مرحبًا، أنا جانفي، متحمس لعلوم البيانات وأعمل حاليًا في Analytics Vidhya. بدأت رحلتي إلى عالم البيانات بفضول عميق حول كيفية استخلاص رؤى ذات معنى من مجموعات البيانات المعقدة.
قم بتسجيل الدخول لمواصلة القراءة والاستمتاع بالمحتوى الذي ينظمه الخبراء.
Source link



