بناء خط أنابيب للذكاء الاصطناعي للوكالات لإعداد التقارير البيئية والاجتماعية والحوكمة

غالبًا ما تبدو التقارير البيئية والاجتماعية والإدارية أو التقارير البيئية والاجتماعية والحوكمة مرهقة لأن البيانات تأتي من أماكن كثيرة وتستغرق وقتًا طويلاً لتجميعها معًا. تقضي الفرق معظم وقتها في جمع الأرقام بدلاً من تفسير ما تعنيه. يقوم الذكاء الاصطناعي الوكيل بتغيير تلك الديناميكية. بدلاً من قيام روبوت محادثة واحد بالإجابة على الأسئلة، ستحصل على مجموعة منسقة من مساعدي الذكاء الاصطناعي الذين يعملون مثل فريق إعداد التقارير المخصص. إنهم يجمعون المعلومات، ويتحققون منها وفقًا للقواعد ذات الصلة، ويعدون مسودة ملخصات واضحة حتى يتمكن البشر من التركيز على المعرفة بدلاً من الأعمال الورقية.
في هذا الدليل، سنقدم، خطوة بخطوة، مسارًا عمليًا يركز على المطورين لإعداد التقارير البيئية والاجتماعية والحوكمة (ESG) ويغطي:
- تجميع البيانات: استخدم وكلاء متزامنين للحصول على البيانات من واجهات برمجة التطبيقات والمستندات ثم فهرستها باستخدام بحث المتجهات (على سبيل المثال، تضمينات OpenAI + FAISS).
- فحوصات الامتثال: قم بتنفيذ القواعد التنظيمية (مثل CSRD أو تصنيف الاتحاد الأوروبي) من خلال منطق التعليمات البرمجية أو استعلامات SQL لتسليط الضوء على أي مشاكل.
- التقرير الذكي: قم بتوجيه إنشاء تقرير سردي باستخدام سلاسل الاسترجاع المعزز (RAG) وLLM وقم بتسليمه كملف PDF.
الخطوة 1: تجميع البيانات البيئية والاجتماعية والحوكمة (ESG) مع وكلاء الذكاء الاصطناعي
في البداية، من الضروري جمع كافة البيانات ذات الصلة بوسائل متوازية. للتوضيح، يمكن لأحد الوكلاء الحصول على أحدث الأبحاث البيئية والاجتماعية والحوكمة من خلال arXiv API، ويمكن للوكيل الآخر البحث عن التحديثات التنظيمية الأخيرة عبر واجهة برمجة التطبيقات الإخبارية، ويمكن للوكيل الثالث تصنيف مستندات ESG الداخلية للشركة.
في إحدى التجارب، عمل ثلاثة “وكلاء بحث” محددين في وقت واحد لإجراء استفسارات إلى arXiv، وفهرس بحث Azure AI الداخلي، ومصادر الأخبار. بعد ذلك، قام كل وكيل بتزويد قاعدة المعرفة المركزية ببياناته. يمكننا محاكاة هذه العملية في بايثون من خلال استخدام سلاسل الرسائل مع مخزن متجه للبحث في المستندات:
import requests
import concurrent.futures
from langchain.document_loaders import PyPDFLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.chat_models import ChatOpenAI
from langchain.chains import RetrievalQA
# ESG Data Aggregation and RAG Pipeline Example
# 1. External Search Functions
# Example: search arXiv for ESG-related papers
def search_arxiv(query, max_results=3):
"""Searches the arXiv API for papers."""
url = (
f"http://export.arxiv.org/api/query?"
f"search_query=all:{query}&max_results={max_results}"
)
res = requests.get(url)
# (Parse the XML response; here we just return raw text for brevity)
return res.text(:200) # show first 200 chars of result
# Example: search news using a hypothetical API (replace with a real news API)
def search_news(query, api_key):
"""Searches a hypothetical news API (needs replacement with a real one)."""
# NOTE: This is a placeholder URL and will not work without a real news API
url = f"https://newsapi.example.com/search?q={query}&apiKey={api_key}"
try:
# Simulate a request; this will likely fail with a 404/SSL error
res = requests.get(url, timeout=5)
articles = res.json().get("articles", ())
return (article("title") for article in articles(:3))
except requests.exceptions.RequestException as e:
return (f"Error fetching news (API Placeholder): {e}")
# 2. Internal Document Indexing Function (for RAG)
def build_vector_index(pdf_paths):
"""Loads, splits, and embeds PDF documents into a FAISS vector store."""
splitter = CharacterTextSplitter(chunk_size=800, chunk_overlap=100)
all_docs = ()
# NOTE: PyPDFLoader requires the files 'annual_report.pdf' and 'energy_audit.pdf' to exist
for path in pdf_paths:
try:
loader = PyPDFLoader(path)
pages = loader.load()
docs = splitter.split_documents(pages)
all_docs.extend(docs)
except Exception as e:
print(f"Warning: Could not load PDF {path}. Skipping. Error: {e}")
if not all_docs:
# Return a simple object or raise an error if no documents were loaded
print("Error: No documents were successfully loaded to build the index.")
return None
embeddings = OpenAIEmbeddings()
vector_index = FAISS.from_documents(all_docs, embeddings)
return vector_index
# --- Main Execution ---
# Paths to internal ESG PDFs (must exist in the same directory or have full path)
pdf_files = ("annual_report.pdf", "energy_audit.pdf")
# Run external searches and document indexing in parallel
print("Starting parallel data fetching and index building...")
with concurrent.futures.ThreadPoolExecutor() as executor:
# External Searches
future_arxiv = executor.submit(search_arxiv, "net zero 2030")
# NOTE: Replace 'YOUR_NEWS_API_KEY' with a valid key for a real news API
future_news = executor.submit(
search_news,
"EU CSRD regulation",
"YOUR_NEWS_API_KEY"
)
# Build vector index (will print warnings if PDFs don't exist)
future_index = executor.submit(build_vector_index, pdf_files)
# Collect results
arxiv_data = future_arxiv.result()
news_data = future_news.result()
vector_index = future_index.result()
print("\n--- Aggregated Results ---")
print("ArXiv fetched data snippet:", arxiv_data)
print("Top news titles:", news_data)
if vector_index:
print("\nFAISS Vector Index successfully built.")
# Example continuation: Initialize the RAG chain
# llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
# qa_chain = RetrievalQA.from_chain_type(
# llm=llm,
# retriever=vector_index.as_retriever()
# )
# print("RAG setup complete. Ready to query internal documents.")
else:
print("RAG setup skipped due to failed vector index creation.")الإخراج:

هنا، استخدمنا تجمع مؤشرات الترابط للاتصال بمصادر مختلفة في وقت واحد. يقوم أحد الخيوط بجلب أوراق arXiv، وآخر يستدعي واجهة برمجة تطبيقات الأخبار، ويقوم آخر بإنشاء مخزن متجه للمستندات الداخلية. يستخدم فهرس المتجهات عمليات تضمين OpenAI المخزنة في FAISS، مما يتيح البحث باللغة الطبيعية في المستندات.
الاستعلام عن البيانات المجمعة
ومن خلال البيانات التي تم جمعها، يمكن للوكلاء الاستعلام عنها عبر اللغة الطبيعية. على سبيل المثال، يمكننا استخدام خط أنابيب RAG الخاص بـ LangChain لطرح أسئلة مقابل المستندات المفهرسة:
# Create a retriever from the FAISS index
retriever = vector_index.as_retriever(
search_type="similarity",
search_kwargs={"k": 4}
)
# Initialize an LLM (e.g., GPT-4) and a RetrievalQA chain
llm = ChatOpenAI(temperature=0, model="gpt-4")
qa_chain = RetrievalQA(llm=llm, retriever=retriever)
# Ask a natural language question about ESG data
answer = qa_chain.run("What were the Scope 2 emissions for 2023?")
print("RAG answer:", answer)يتيح أسلوب RAG هذا للوكيل استرداد أجزاء المستند ذات الصلة (من خلال البحث عن التشابه) ثم إنشاء إجابة. في أحد العروض التوضيحية، قام أحد الوكلاء بتحويل استعلامات اللغة الإنجليزية البسيطة إلى SQL لجلب البيانات الرقمية (مثل “انبعاثات النطاق 2 في 2024”) من قاعدة بيانات الانبعاثات. يمكننا بالمثل تضمين خطوة استعلام SQL إذا لزم الأمر، على سبيل المثال باستخدام SQLite في Python:
import sqlite3
# Example: store some emissions data in SQLite
conn = sqlite3.connect(':memory:')
cursor = conn.cursor()
cursor.execute("CREATE TABLE emissions (year INTEGER, scope2 REAL)")
cursor.execute("INSERT INTO emissions VALUES (2023, 1725.4)")
conn.commit()
# Simple SQL query for numeric data
cursor.execute("SELECT scope2 FROM emissions WHERE year=2023")
scope2_emissions = cursor.fetchone()(0)
print("Scope 2 emissions 2023 (from DB):", scope2_emissions) من الناحية العملية، يمكنك دمج LangChain SQL Agent لتحويل اللغة الطبيعية إلى SQL تلقائيًا. بغض النظر عن المصدر، فإن كل نقاط البيانات هذه – من ملفات PDF وواجهات برمجة التطبيقات وقواعد البيانات – تغذي قاعدة معرفية موحدة لمسار إعداد التقارير.
الخطوة 2: فحوصات الامتثال الآلي
تأتي عملية ضمان الامتثال بعد تجميع المقاييس الأولية. يمكن أن يساعد مزيج منطق الكود ودعم LLM في هذا الصدد. على سبيل المثال، يمكننا تعيين قواعد المجال (مثل معايير التصنيف في الاتحاد الأوروبي) ثم إجراء عمليات التحقق:
# Example ESG metrics extracted from data aggregation
metrics = {
"scope1_tCO2": 980,
"scope2_tCO2": 1725.4,
"renewable_percent": 25, # percent of energy from renewables
"water_usage_liters": 50000,
"reported_water_liters": 48000
}
# Simple rule-based compliance checks
def run_compliance_checks(metrics):
"""
Runs basic checks against predefined ESG compliance rules.
"""
issues = ()
# Example rule 1: EU Taxonomy requires >= 30% renewable energy
if metrics("renewable_percent") < 30:
issues.append("Renewables below EU taxonomy threshold (30%).")
# Example rule 2: Consistency check (tolerance of 1000 liters)
if abs(metrics("water_usage_liters") - metrics("reported_water_liters")) > 1000:
issues.append("Water usage mismatch between operations data and financial report.")
return issues
# Execute the checks
compliance_issues = run_compliance_checks(metrics)
print("Compliance issues found:", compliance_issues)تحدد هذه الوظيفة البسيطة أي قواعد تم انتهاكها. في الحياة الواقعية، ربما يمكنك الحصول على القواعد من قاعدة المعرفة أو التكوين. يتم تقسيم فحوصات الامتثال بشكل متكرر إلى أدوار في الأنظمة القائمة على الوكيل. يقوم وكلاء المعايير/التعيين بربط البيانات التي تم استخراجها بحقول الكشف المحددة أو معايير التصنيف بينما يقوم وكلاء الحساب بإجراء عمليات التحقق أو التحويلات الرقمية. على سبيل المثال، يمكن لأحد الوكلاء التحقق مما إذا كان نشاط معين يتوافق مع معايير “عدم إحداث ضرر كبير” التي حددها التصنيف أو يمكنه استخلاص إجمالي الانبعاثات عن طريق استعلامات تحويل النص إلى SQL.
مثال لتحويل النص إلى SQL (اختياري)
يوفر LangChain أدوات SQL لأتمتة هذه الخطوة. على سبيل المثال، يمكن إنشاء وكيل SQL الذي يفحص مخطط قاعدة البيانات الخاصة بك ويقوم بإنشاء الاستعلامات. إليك رسمًا باستخدام قاعدة بيانات SQLDatabase الخاصة بـ LangChain:
from langchain.agents import create_sql_agent
from langchain.sql_database import SQLDatabase
# Set up a SQLite DB (same as above)
db = SQLDatabase.from_uri("sqlite:///:memory:", include_tables=("emissions"))
# Create an agent that can answer questions using the DB
sql_agent = create_sql_agent(llm=llm, db=db, verbose=False)
query_result = sql_agent.run("What is the total Scope 2 emissions for 2023?")
print("SQL Agent result:", query_result)سيقوم هذا الوكيل بفحص جدول الانبعاثات وإنتاج استعلام لحساب الإجابة والتحقق منها قبل إرجاع النتيجة. (من الناحية العملية، تأكد من تأمين أذونات قاعدة البيانات الخاصة بك، حيث إن تنفيذ SQL المنشأ بواسطة النموذج ينطوي على مخاطر.)
الخطوة 3: إعداد التقارير الذكية التوليدية مع وكلاء RAG
بعد التحقق من الصحة، المرحلة النهائية هي كتابة التقرير السردي. وهنا يأخذ وكيل التوليف البيانات التي تم تنظيفها ويكتب إفصاحات يمكن قراءتها بواسطة الإنسان. يمكننا استخدام سلاسل LLM لهذا الغرض، غالبًا مع RAG لتضمين أرقام واستشهادات محددة. على سبيل المثال، قد نطالب النموذج بالمقاييس الأساسية ونسمح له بصياغة ملخص:
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
# Prepare a prompt template to generate an executive summary
prompt_template = """
Write a concise executive summary of the ESG report using the data below.
Include key figures and context:
{summary_data}
"""
template = PromptTemplate(
input_variables=("summary_data"),
template=prompt_template
)
# Example data to include in the summary
findings = f"""
- Scope 1 CO2 emissions: {metrics('scope1_tCO2')} tCO2e
- Scope 2 CO2 emissions: {metrics('scope2_tCO2')} tCO2e
- Renewable energy share: {metrics('renewable_percent')}%
"""
chain = LLMChain(llm=ChatOpenAI(temperature=0.2), prompt=template)
summary_text = chain.run({"summary_data": findings})
print("Generated summary:\n", summary_text)الإخراج:
=== ANSWER ===
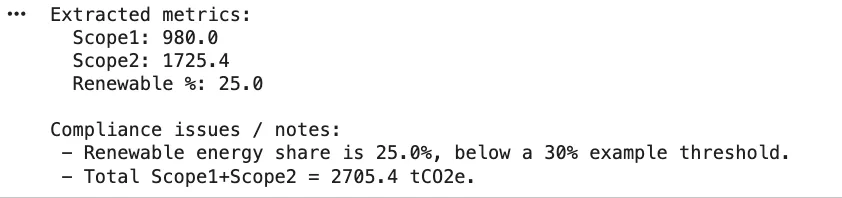
In the **Sustainability Annual Report 2024**, the reported emissions are as follows:- **Scope 1 Emissions**: 980 tCO2e
- **Scope 2 Emissions**: 1,725.4 tCO2eThe total emissions amount to **2,705.4 tCO2e**.
A notable compliance gap is identified in the **Energy Audit Summary - 2024**, where the renewable energy share is reported at **28%**, which is below the regulatory target of **30%**. This indicates a need for improvement in renewable energy utilization to meet compliance standards.
Additionally, the report highlights a recommendation to add **500 kW** of rooftop solar to enhance renewable energy capacity.
وبدلاً من ذلك، يمكنك إنشاء برنامج RetrievalQA أو وكيل متسلسل يسحب من المستندات والبيانات المفهرسة، ثم يستدعي LLM لكتابة كل قسم. على سبيل المثال، باستخدام برنامج LangChain’s RetrievalQA كما هو مذكور أعلاه، يمكنك أن تطلب من الوكيل “تلخيص النطاق 1 و2 من الانبعاثات وتسليط الضوء على أي فجوات في الامتثال”. المفتاح هو أن كل إجابة يمكن أن تستشهد بمصادر أو طرق، مما يتيح تتبع الأدلة.
الخطوة 4: تجميع التقرير النهائي
بعد الصياغة، سيكون من الممكن دمج الأقسام وتنسيقها كما يتم ذلك بطريقة بسيطة جدًا باستخدام fpdf. سيتم استخدام PDF لكتابة الملخص.
from fpdf import FPDF
pdf = FPDF()
pdf.add_page()
pdf.set_font("Arial", size=14)
pdf.multi_cell(0, 10, summary_text)
pdf.output("esg_report_summary.pdf")
print("PDF report generated.")الإخراج:

في خط أنابيب كامل، يمكن للمرء إنشاء العديد من الأقسام (مثل الثقافات، والانبعاثات، والطاقة، والمياه، وما إلى ذلك) وجمعها معًا. يمكن للوكلاء أيضًا المساعدة في التحرير المباشر: يتم عرض مسودة الإجابات في واجهة مستخدم الدردشة ليتمكن خبراء المجال من تقييمها وتحسينها. بمجرد الموافقة عليه، يمكن لوكيل التوليف إنشاء ملف PDF النهائي أو تسليم النص، بالإضافة إلى الجداول والأشكال حسب الضرورة.
في النهاية، يعمل سير عمل الوكلاء هذا على تقليل الوقت المستغرق في إعداد التقارير اليدوية من أسابيع إلى ساعات: يقوم الوكلاء بملء عناصر الاستبيان من البيانات على دفعات، ووضع علامة على أي مشكلات، والسماح للمراجعة البشرية، ثم إنتاج تقرير كامل. تأتي كل إجابة مع مراجع مضمنة وخطوات حسابية من أجل الوضوح. والنتيجة هي تقرير ESG جاهز للتدقيق والذي تم إنشاؤه بواسطة الكود والذكاء الاصطناعي، وليس يد بشرية.
خاتمة
يمكن تشغيل سير عمل ESG الشامل بشكل أكثر سلاسة عندما يتقاسم العديد من وكلاء الذكاء الاصطناعي العبء. إنهم يسحبون المعلومات من مصادر البحث وموجزات الأخبار والملفات الداخلية في نفس الوقت، ويتحققون من البيانات مقابل القواعد ذات الصلة، ويساعدون في تشكيل التقرير النهائي باستخدام الإنشاء الواعي بالسياق. توضح أمثلة التعليمات البرمجية كيف يظل كل جزء نظيفًا ومعياريًا، مما يجعل من السهل توصيل واجهات برمجة التطبيقات الحقيقية، أو توسيع مجموعة القواعد، أو ضبط المنطق عندما تتغير اللوائح. الفوز الحقيقي هو الوقت: تنفق الفرق طاقة أقل في مطاردة البيانات وأكثر على فهم ما تعنيه. باستخدام هذا المسار، لديك مخطط واضح لبناء نظام إعداد التقارير البيئي والاجتماعي والحوكمة (ESG) الخاص بك والذي يحركه الوكيل.
الأسئلة المتداولة
ج. إنه يقسم عبء العمل عبر الوكلاء المستقلين الذين يقومون بسحب البيانات والتحقق من التوافق وصياغة الأقسام بالتوازي. تختفي معظم الأعمال الشاقة، تاركة البشر للمراجعة والتحسين بدلاً من تجميع كل شيء يدويًا.
أ. ليس حقاً. يستخدم الإعداد النموذجي Python وLangChain وأدوات البحث المتجهة مثل FAISS وLLM API. يمكنك التوسع لاحقًا باستخدام منسقي سير العمل أو الوظائف السحابية إذا لزم الأمر.
أ. نعم. توجد قواعد الامتثال في التعليمات البرمجية أو التكوين، لذا يمكنك تحديث أو إضافة وحدات قواعد جديدة دون لمس بقية المسار. يقوم الوكلاء تلقائيًا بتطبيق أحدث المنطق أثناء عمليات الفحص.
![]()
متدرب في علوم البيانات في Analytics Vidhya
أعمل حاليًا كمتدرب في علوم البيانات في Analytics Vidhya، حيث أركز على بناء حلول تعتمد على البيانات وتطبيق تقنيات الذكاء الاصطناعي/التعلم الآلي لحل مشكلات الأعمال الواقعية. يتيح لي عملي استكشاف التحليلات المتقدمة والتعلم الآلي وتطبيقات الذكاء الاصطناعي التي تمكن المؤسسات من اتخاذ قرارات أكثر ذكاءً وقائمة على الأدلة.
مع أساس قوي في علوم الكمبيوتر، وتطوير البرمجيات، وتحليلات البيانات، أنا متحمس للاستفادة من الذكاء الاصطناعي لإنشاء حلول مؤثرة وقابلة للتطوير تعمل على سد الفجوة بين التكنولوجيا والأعمال.
📩 كما يمكنكم التواصل معي على (البريد الإلكتروني محمي)
قم بتسجيل الدخول لمواصلة القراءة والاستمتاع بالمحتوى الذي ينظمه الخبراء.
Source link