أنظمة التوصية هي المحركات غير المرئية التي يمكنها تخصيص وسائل التواصل الاجتماعي وخدمات OTT والتجارة الإلكترونية. سواء كنت تتصفح Netflix لمشاهدة عرض جديد أو تتصفح Amazon بحثًا عن أداة ذكية، فإن هذه الخوارزميات تعمل خلف الكواليس للتنبؤ بشيء ما بالنسبة لك. واحدة من أكثر الطرق فعالية للقيام بذلك هي النظر في كيفية تصرف الأشخاص الآخرين ذوي الأذواق المماثلة. هذا هو جوهر التخصيص الحديث. في هذه المقالة، سنستكشف كيفية بناء أحد هذه الأنظمة باستخدام التصفية التعاونية وجعلها أكثر ذكاءً باستخدام OpenAI. دون مزيد من اللغط، دعونا نتعمق.
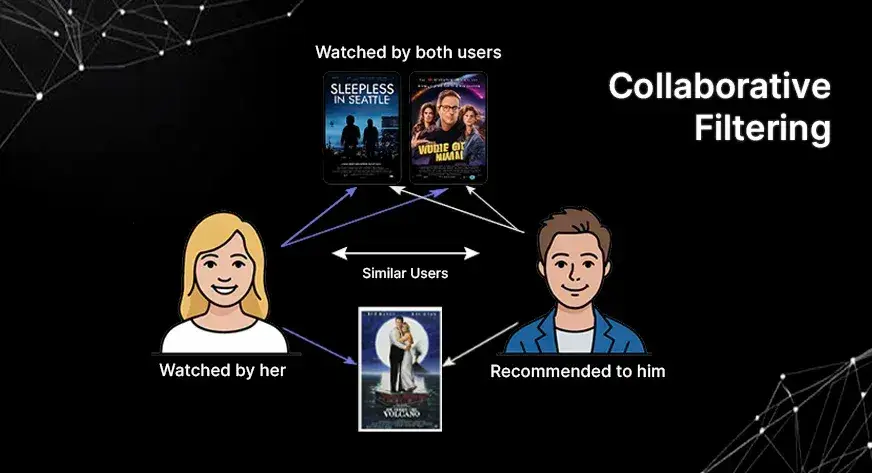
ما هي التصفية التعاونية؟
التصفية التعاونية هي تقنية لتقديم توصيات من مجموعة من المستخدمين المختلفين. الحدس هنا هو أنه إذا كان المستخدم 1 والمستخدم 2 يحبان نفس الأفلام، فمن المحتمل أن يكون لهما أذواق مماثلة. إذا شاهد المستخدم 1 فيلمًا جديدًا وأعجب به، فسيوصي النظام بهذا الفيلم للمستخدم 2. ولا يحتاج إلى معرفة أي شيء آخر مثل النوع أو الممثلين، بل يحتاج فقط إلى معرفة من أعجبه.
يتم استخدام مصفوفة عنصر المستخدم لإجراء التصفية التعاونية. يتم إنشاء هذا بشكل عام باستخدام عمود عنصر مثل الأفلام لإنشاء جدول محوري مع كل قيمة كعمود في الجدول الناتج.
اقرأ المزيد: دليل التصفية التعاونية
سلبيات بعض تقنيات التصفية التعاونية
هناك طريقتان شائعتان لإجراء التصفية التعاونية، ولكن لكل منهما جوانب سلبية:
- تصفية المستخدم-المستخدم: يؤدي هذا إلى العثور على المستخدمين المشابهين لك. المشكلة هي أن عدد المستخدمين في النظام يمكن أن يصل إلى الملايين، مما يجعل المقارنة بين الجميع بطيئة جدًا من الناحية الحسابية. كما أن أذواق الأشخاص تتغير بمرور الوقت، مما قد يؤدي إلى إرباك النظام أو يتطلب إعادة تدريب متكررة جدًا للنظام.
- تصفية العنصر-العنصر: يؤدي هذا إلى البحث عن الأفلام بناءً على تشابه العنصر مع العنصر. على الرغم من أن هذا أكثر استقرارًا من تصفية المستخدم والمستخدم، إلا أنه لا يزال يعاني من التشتت. يحدث هذا لأن معظم المستخدمين يقومون بتقييم جزء صغير فقط من آلاف الأفلام المتاحة.
تحليل القيمة المفردة (SVD)
الحدس هنا هو استخدام تحليل المصفوفة باستخدام تحليل القيمة المفردة (SVD) لتحليل مصفوفة متفرقة إلى مصفوفات عوامل لاحقة ذات أبعاد أقل. هذه هي تقنية التصفية التعاونية لعنصر المستخدم وهذه هي تقنية التصفية التعاونية التي سنختارها لنظام التوصيات الخاص بنا.
نظام توصية الفيلم
دعونا نفهم البيانات ونبني نظام التوصيات الخاص بنا باستخدام تقنية التصفية التعاونية SVD التي تمت مناقشتها سابقًا.
ملحوظة: نظرًا لحجم الكود، تم شرح الأجزاء المهمة فقط من الكود، يمكنك الرجوع إلى المفكرة الكاملة هنا: (https://www.kaggle.com/code/mounishv/movie-recommender)
فهم مجموعة البيانات
في هذا المشروع، نستخدم مجموعة بيانات الأفلام (https://www.kaggle.com/datasets/rounakbanik/the-movies-dataset)، وهي عبارة عن مجموعة من البيانات الوصفية لأكثر من 45000 فيلم. على الرغم من أن مجموعة البيانات الكاملة ضخمة، إلا أننا نستخدم على وجه التحديد ratings_small.csv ملف. تحتوي هذه النسخة الأصغر على حوالي 100000 تقييم من 700 مستخدم على 9000 فيلم. نحن نستخدم النسخة الصغيرة لأنها تتيح لنا تدريب النماذج بسرعة.
المتطلبات المسبقة
سوف نستخدم:
المكتبة المفاجئة لتقسيم البيانات وSVD
تم تصميم مكتبة Surprise خصيصًا للتوصيات. إنه يبسط عملية تحميل البيانات واختبار الخوارزميات المختلفة. قبل التدريب، قمنا بتقسيم بياناتنا إلى مجموعة تدريب ومجموعة اختبار باستخدام المفاجأة ونستخدم أيضًا التنفيذ المدمج لـ SVD.
كود بايثون
يتبع الكود المقدم سير عمل احترافي لبناء النموذج وتحسينه.
متطلبات
!pip install "numpy<2"
!pip install -q openaiملحوظة: أعد تشغيل جلسة Colab قبل المتابعة
1. إعداد البيانات
يقوم الكود أولاً بدمج معرفات الأفلام من ملفات مختلفة لضمان تطابق التصنيفات وعناوين الأفلام بشكل صحيح.
import pandas as pd
from surprise import Dataset, Reader, SVD
from surprise.model_selection import GridSearchCV, train_test_split
from surprise import accuracy
# Kaggle path for The Movies Dataset
path="/kaggle/input/the-movies-dataset/"
# Loading relevant files
ratings = pd.read_csv(path + 'ratings_small.csv')
metadata = pd.read_csv(path + 'movies_metadata.csv', low_memory=False)
links = pd.read_csv(path + 'links_small.csv')
ratings('movieId') = pd.to_numeric(ratings('movieId'), errors="coerce").astype('Int32')
ratings = ratings.merge(links(('movieId', 'tmdbId')), on='movieId', how='left')2. تقسيم البيانات وإيجاد النموذج الأفضل
# Initialize the Reader for Surprise (ratings are 1-5)
reader = Reader(rating_scale=(0.5, 5.0))
# Load the dataframe into Surprise format
data = Dataset.load_from_df(
ratings(('userId', 'movieId', 'rating')),
reader
)
# Split into 75% training and 25% testing
trainset, testset = train_test_split(data, test_size=0.25, random_state=42)بدلاً من تخمين أفضل الإعدادات، يستخدم الكود GridSearchCV. يقوم هذا تلقائيًا باختبار إصدارات مختلفة من SVD للعثور على الإصدار الذي يحتوي على أقل RMSE.
# Define the parameter grid
param_grid = {
'n_factors': (10, 20, 50),
'n_epochs': (10, 20),
'lr_all': (0.005, 0.01), # learning rate
'reg_all': (0.02, 0.1) # regularization
}
# Run Grid Search with 3-fold cross-validation
gs = GridSearchCV(SVD, param_grid, measures=('rmse'), cv=3, n_jobs=-1)
gs.fit(data)
# Best RMSE score
print(f"Best RMSE score found: {gs.best_score('rmse')}")
# Combination of parameters that gave the best RMSE score
print(f"Best parameters: {gs.best_params('rmse')}")Best RMSE score found: 0.8902760026938319Best parameters: {'n_factors': 50, 'n_epochs': 20, 'lr_all': 0.01, 'reg_all': 0.1}
3. التطور الذكي
الجزء الأكثر تميزًا في هذا الرمز هو كيفية استخدام LLM لمساعدة المستخدم. بمجرد أن يتنبأ نموذج SVD بأفضل 5 أفلام للمستخدم، يطرح LLM (GPT-4.1 mini) سؤالاً لمساعدة المستخدم على اختيار فيلم واحد فقط.
import numpy as np
from openai import OpenAI
from collections import defaultdict
from sklearn.metrics.pairwise import cosine_similarity
client = OpenAI(api_key=OPENAI_API_KEY)سنحدد وظيفتين لتنفيذ فكرتنا. وظيفة واحدة get_top_5_for_user سيتم استرجاع 5 توصيات للمستخدم والآخر smart_recommendation سوف يقوم بالمهام التالية:
- يستخدم البيانات الوصفية للحصول على مزيد من السياق حول الأفلام الخمسة
- يمررها إلى LLM لصياغة سؤال للمستخدم
- سيتم استخدام إجابة المستخدم لتقديم توصيته النهائية باستخدام تشابه جيب التمام.
منطق إنشاء السؤال
movie_list_str = "\n".join((f"- {m('title')}: {m('desc')}" for m in movie_info))
prompt = f"I have selected these 5 movies for a user based on their history:\n{movie_list_str}\n\n" \
"Frame one short, engaging question to help the user choose between these specific options."
question = client.chat.completions.create(
model="gpt-4.1-mini",
messages=({"role": "user", "content": prompt})
).choices(0).message.contentمنطق المطابقة الدلالية (باستخدام تشابه جيب التمام)
resp_vec = client.embeddings.create(
input=(user_response),
model="text-embedding-3-small"
).data(0).embedding
movie_texts = (f"{m('title')} {m('desc')}" for m in movie_info)
movie_vecs = (e.embedding for e in client.embeddings.create(
input=movie_texts,
model="text-embedding-3-small"
).data)
scores = cosine_similarity((resp_vec), movie_vecs)(0)
winner_idx = np.argmax(scores)4. تشغيل النظام
توقع تقييم المستخدم:
# Pick a random user and movie from the test set
uid = testset(0)(0)
iid = testset(0)(1)
true_r = testset(0)(2)
pred = final_model.predict(uid, iid)
print(f"\nUser: {uid}")
print(f"Movie: {iid}")
print(f"Actual Rating: {true_r}")
print(f"Predicted Rating: {pred.est:.2f}")User: 30
Movie: 2856
Actual Rating: 4.0
Predicted Rating: 3.72
التوصية الذكية
top_5 = get_top_5_for_user(predictions, target_uid=testset(0)(0))
final_movie, score = llm_recommendation(top_5, metadata, links)
print(f"\nFinal Recommendation: {final_movie('title')} (Match Score: {score:.2f})")Agent: Are you in the mood for a gripping drama, a thrilling action-packed story, a classic comedy adventure, or an enchanting animated fantasy?Your answer: animated movie
Final Recommendation: How to Train Your Dragon (Match Score: 0.32)
كما ترون، عندما قلت فيلم رسوم متحركة، أوصى النظام بـ “كيف تدرب تنينك” بناءً على حالتي المزاجية الحالية. الاستفادة من تشابه جيب التمام بين إجابتي وأوصاف الفيلم لاختيار التوصية النهائية.
خاتمة
لقد نجحنا في بناء نظام التوصيات الذكي الخاص بنا. باستخدام SVD باستخدام مكتبة Surprise، قمنا بتخفيف المشكلات باستخدام تقنيات التصفية التعاونية الأخرى. إن إضافة LLM إلى هذا المزيج يجعل النظام أفضل ويعتمد أيضًا على الحالة المزاجية بدلاً من وجود نظام ثابت، على الرغم من أن مستوى التخصيص يمكن أن يكون أعلى من خلال تضمين بيانات المستخدم أيضًا في السؤال. ومن المهم أيضًا ملاحظة أنه يتعين علينا إعادة تدريب نموذج التصفية التعاوني بشكل متكرر على أحدث البيانات للحفاظ على التوصيات ذات الصلة.
الأسئلة المتداولة
ج: إنها علاقة بيرسون، فهي تقيس التشابه بين مستخدمين من خلال مقارنة أنماط التقييم الخاصة بهم والتحقق من مدى قوة تحرك تفضيلاتهم معًا.
أ. يقيس تشابه جيب التمام مدى تشابه المتجهين عن طريق حساب الزاوية بينهما، والتي تستخدم عادة للنص والتضمين.
ج. يبحث التنقيب عن قواعد الارتباط عن العلاقات بين العناصر في مجموعات البيانات، مثل المنتجات التي يتم شراؤها معًا بشكل متكرر، باستخدام مقاييس الدعم والثقة والرفع.
قم بتسجيل الدخول لمواصلة القراءة والاستمتاع بالمحتوى الذي ينظمه الخبراء.



